启发式算法 (Heuristic Algorithms)
启发式算法 (Heuristic Algorithms) 是相对于最优算法提出的。一个问题的最优算法是指求得该问题每个实例的最优解. 启发式算法可以这样定义 1:一个基于直观或经验构造的算法,在可接受的花费 (指计算时间、占用空间等) 下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度不一定事先可以预计。
在某些情况下,特别是实际问题中,最优算法的计算时间使人无法忍受或因问题的难度使其计算时间随问题规模的增加以指数速度增加,此时只能通过启发式算法求得问题的一个可行解。
利用启发式算法进行目标优化的一些优缺点如下:
| 优点 | 缺点 |
|---|---|
| 1. 算法简单直观,易于修改 2. 算法能够在可接受的时间内给出一个较优解 |
1. 不能保证为全局最优解 2. 算法不稳定,性能取决于具体问题和设计者经验 |
启发式算法简单的划分为如下三类:简单启发式算法 (Simple Heuristic Algorithms),元启发式算法 (Meta-Heuristic Algorithms) 和 超启发式算法 (Hyper-Heuristic Algorithms)。
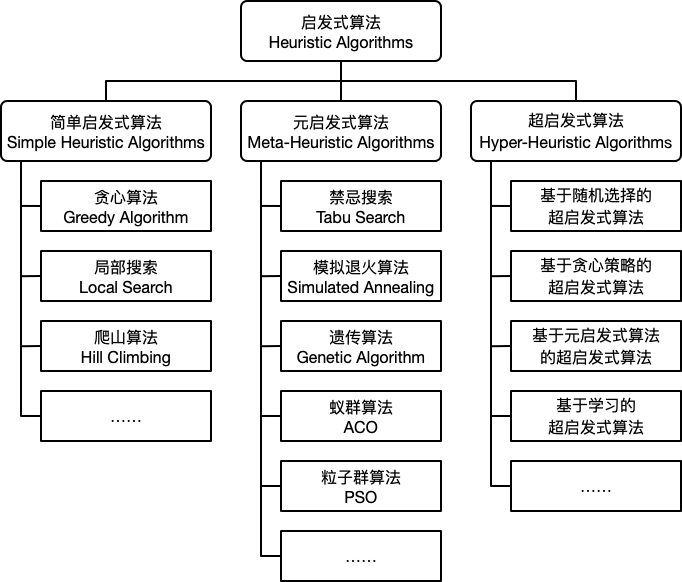
简单启发式算法 (Simple Heuristic Algorithms)
贪心算法 (Greedy Algorithm)
贪心算法是指一种在求解问题时总是采取当前状态下最优的选择从而得到最优解的算法。贪心算法的基本步骤定义如下:
- 确定问题的最优子结构。
- 设计递归解,并保证在任一阶段,最优选择之一总是贪心选择。
- 实现基于贪心策略的递归算法,并转换成迭代算法。
对于利用贪心算法求解的问题需要包含如下两个重要的性质:
- 最优子结构性质。当一个问题具有最优子结构性质时,可用 动态规划 法求解,但有时用贪心算法求解会更加的简单有效。同时并非所有具有最优子结构性质的问题都可以利用贪心算法求解。
- 贪心选择性质。所求问题的整体最优解可以通过一系列局部最优的选择 (即贪心选择) 来达到。这是贪心算法可行的基本要素,也是贪心算法与动态规划算法的主要区别。
贪心算法和动态规划算法之间的差异如下表所示:
| 贪心算法 | 动态规划 |
|---|---|
| 每个阶段可以根据选择当前状态最优解快速的做出决策 | 每个阶段的选择建立在子问题的解之上 |
| 可以在子问题求解之前贪婪的做出选择 | 子问题需先进行求解 |
| 自顶向下的求解 | 自底向上的求解 (也可采用带备忘录的自顶向下方法) |
| 通常情况下简单高效 | 效率可能比较低 |
局部搜索 (Local Search) 和爬山算法 (Hill Climbing)
局部搜索算法基于贪婪思想,从一个候选解开始,持续地在其邻域中搜索,直至邻域中没有更好的解。对于一个优化问题:
$$ \min f \left(x\right), x \in \mathbb{R}^n $$
其中,$f \left(x\right)$ 为目标函数。搜索可以理解为从一个解移动到另一个解的过程,令 $s \left(x\right)$ 表示通过移动得到的一个解,$S \left(x\right)$ 为从当前解出发所有可能的解的集合 (邻域),则局部搜索算法的步骤描述如下:
- 初始化一个可行解
$x$。 - 在当前解的邻域内选择一个移动后的解
$s \left(x\right)$,使得$f \left(s \left(x\right)\right) < f \left(x\right), s \left(x\right) \in S \left(x\right)$,如果不存在这样的解,则$x$为最优解,算法停止。 - 令
$x = s \left(x\right)$,重复步骤 2。
当我们的优化目标为最大化目标函数 $f \left(x\right)$ 时,这种局部搜索算法称之为爬山算法。
元启发式算法 (Meta-Heuristic Algorithms)
元启发式算法 (Meta-Heuristic Algorithms) 是启发式算法的改进,通常使用随机搜索技巧,可以应用在非常广泛的问题上,但不能保证效率。本节部分内容参考了《智能优化方法》2 和《现代优化计算方法》1。
禁忌搜索 (Tabu Search)
禁忌搜索 (Tabu Search) 是由 Glover 3 提出的一种优化方法。禁忌搜索通过在解邻域内搜索更优的解的方式寻找目标的最优解,在搜索的过程中将搜索历史放入禁忌表 (Tabu List) 中从而避免重复搜索。禁忌表通过模仿人类的记忆功能,禁忌搜索因此得名。
在禁忌搜索算法中,禁忌表用于防止搜索过程出现循环,避免陷入局部最优。对于一个给定长度的禁忌表,随着新的禁忌对象的不断进入,旧的禁忌对象会逐步退出,从而可以重新被访问。禁忌表是禁忌搜索算法的核心,其功能同人类的短时记忆功能相似,因此又称之为“短期表”。
在某些特定的条件下,无论某个选择是否包含在禁忌表中,我们都接受这个选择并更新当前解和历史最优解,这个选择所满足的特定条件称之为渴望水平。
一个基本的禁忌搜索算法的步骤描述如下:
- 给定一个初始可行解,将禁忌表设置为空。
- 选择候选集中的最优解,若其满足渴望水平,则更新渴望水平和当前解;否则选择未被禁忌的最优解。
- 更新禁忌表。
- 判断是否满足停止条件,如果满足,则停止算法;否则转至步骤 2。
模拟退火 (Simulated Annealing)
模拟退火 (Simulated Annealing) 是一种通过在邻域中寻找目标值相对小的状态从而求解全局最优的算法,现代的模拟退火是由 Kirkpatrick 等人于 1983 年提出 4。模拟退火算法源自于对热力学中退火过程的模拟,在给定一个初始温度下,通过不断降低温度,使得算法能够在多项式时间内得到一个近似最优解。
对于一个优化问题 $\min f \left(x\right)$,模拟退火算法的步骤描述如下:
- 给定一个初始可行解
$x_0$,初始温度$T_0$和终止温度$T_f$,令迭代计数为$k$。 - 随机选取一个邻域解
$x_k$,计算目标函数增量$\Delta f = f \left(x_k\right) - f \left(x\right)$。若$\Delta f < 0$,则令$x = x_k$;否则生成随机数$\xi = U \left(0, 1\right)$,若随机数小于转移概率$P \left(\Delta f, T\right)$,则令$x = x_k$。 - 降低温度
$T$。 - 若达到最大迭代次数
$k_{max}$或最低温度$T_f$,则停止算法;否则转至步骤 2。
整个算法的伪代码如下:
\begin{algorithm}
\caption{模拟退火算法}
\begin{algorithmic}
\STATE $x \gets x_0$
\STATE $T \gets T_0$
\STATE $k \gets 0$
\WHILE{$k \leq k_{max}$ \AND $T \geq T_f$}
\STATE $x_k \gets $ \CALL{neighbor}{$s$}
\STATE $\Delta f = f \left(x_k\right) - f \left(x\right)$
\IF{$\Delta f < 0$ \OR \CALL{random}{$0, 1$} $ \leq P \left(\Delta f, T\right)$}
\STATE $x \gets x_k$
\ENDIF
\STATE $T \gets $ \CALL{cooling}{$T, k, k_{max}$}
\STATE $k \gets k + 1$
\ENDWHILE
\end{algorithmic}
\end{algorithm}
在进行邻域搜索的过程中,当温度较高时,搜索的空间较大,反之搜索的空间较小。类似的,当 $\Delta f > 0$ 时,转移概率的设置也同当前温度的大小成正比。常用的降温函数有两种:
$T_{k+1} = T_k * r$,其中$r \in \left(0.95, 0.99\right)$,$r$设置的越大,温度下降越快。$T_{k+1} = T_k - \Delta T$,其中$\Delta T$为每一步温度的减少量。
初始温度和终止温度对算法的影响较大,相关参数设置的细节请参见参考文献。
模拟退火算法是对局部搜索和爬山算法的改进,我们通过如下示例对比两者之间的差异。假设目标函数如下:
$$ f \left(x, y\right) = e^{- \left(x^2 + y^2\right)} + 2 e^{- \left(\left(x - 1.7\right)^2 + \left(y - 1.7\right)^2\right)} $$
优化问题定义为:
$$ \max f \left(x, y\right), x \in \left[-2, 4\right], y \in \left[-2, 4\right] $$
我们分别令初始解为 $\left(1.5, -1.5\right)$ 和 $\left(3.5, 0.5\right)$,下图 (上) 为爬山算法的结果,下图 (下) 为模拟退火算法的结果。


其中,白色 的大点为初始解位置,粉色 的大点为求解的最优解位置,颜色从白到粉描述了迭代次数。从图中不难看出,由于局部最大值的存在,从不同的初始解出发,爬山算法容易陷入局部最大值,而模拟退火算法则相对稳定。
遗传算法 (Genetic Algorithm)
遗传算法 (Genetic Algorithm, GA) 是由 John Holland 提出,其学生 Goldberg 对整个算法进行了进一步完善 5。算法的整个思想来源于达尔文的进化论,其基本思想是根据问题的目标函数构造一个适应度函数 (Fitness Function),对于种群中的每个个体 (即问题的一个解) 进行评估 (计算适应度),选择,交叉和变异,通过多轮的繁殖选择适应度最好的个体作为问题的最优解。算法的整个流程如下所示:
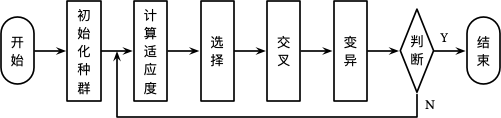
初始化种群
在初始化种群时,我们首先需要对每一个个体进行编码,常用的编码方式有二进制编码,实值编码 6,矩阵编码 7,树形编码等。以二进制为例 (如下不做特殊说明时均以二进制编码为例),对于 $p \in \left\{0, 1, \dotsc, 100\right\}$ 中 $p_i = 50$ 可以表示为:
$$ x_i = 50_{10} = 0110010_{2} $$
对于一个具体的问题,我们需要选择合适的编码方式对问题的解进行编码,编码后的个体可以称之为一个染色体。则一个染色体可以表示为:
$$ x = \left(p_1, p_2, \dotsc, p_m\right) $$
其中,$m$ 为染色体的长度或编码的位数。初始化种群个体共 $n$ 个,对于任意一个个体染色体的任意一位 $i$,随机生成一个随机数 $\text{rand} \in U \left(0, 1\right)$,若 $\text{rand} > 0.5$,则 $p_i = 1$,否则 $p_i = 0$。
计算适应度
适应度为评价个体优劣程度的函数 $f\left(x\right)$,通常为问题的目标函数,对最小化优化问题 $f\left(x\right) = - \min \sum{\mathcal{L} \left(\hat{y}, y\right)}$,对最大化优化问题 $f\left(x\right) = \max \sum{\mathcal{L} \left(\hat{y}, y\right)}$,其中 $\mathcal{L}$ 为损失函数。
选择
对于种群中的每个个体,计算其适应度,记第 $i$ 个个体的适应度为 $F_i = f\left(x_i\right)$。则个体在一次选择中被选中的概率为:
$$ P_i = \dfrac{F_i}{\sum_{i=1}^{n}{F_i}} $$
为了保证种群的数量不变,我们需要重复 $n$ 次选择过程,单次选择采用轮盘赌的方法。利用计算得到的被选中的概率计算每个个体的累积概率:
$$ \begin{equation} \begin{split} CP_0 &= 0 \\ CP_i &= \sum_{j=1}^{i}{P_i} \end{split} \end{equation} $$
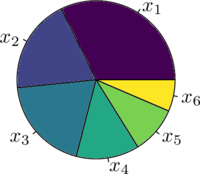
对于如下一个示例:
| 指标 \ 个体 | $x_1$ |
$x_2$ |
$x_3$ |
$x_4$ |
$x_5$ |
$x_6$ |
|---|---|---|---|---|---|---|
| 适应度 (F) | 100 | 60 | 60 | 40 | 30 | 20 |
| 概率 (P) | 0.322 | 0.194 | 0.194 | 0.129 | 0.097 | 0.064 |
| 累积概率 (CP) | 0.322 | 0.516 | 0.71 | 0.839 | 0.936 | 1 |
每次选择时,随机生成 $\text{rand} \in U \left(0, 1\right)$,当 $CP_{i-1} \leq \text{rand} \leq CP_i$ 时,选择个体 $x_i$。选择的过程如同在下图的轮盘上安装一个指针并随机旋转,每次指针停止的位置的即为选择的个体。
交叉
交叉运算类似于染色体之间的交叉,常用的方法有单点交叉,多点交叉和均匀交叉等。
- 单点交叉:在染色体中选择一个切点,然后将其中一部分同另一个染色体的对应部分进行交换得到两个新的个体。交叉过程如下图所示:

- 多点交叉:在染色体中选择多个切点,对其任意两个切点之间部分以概率
$P_c$进行交换,其中$P_c$为一个较大的值,例如$P_m = 0.9$。两点交叉过程如下图所示:

- 均匀交叉:染色体任意对应的位置以一定的概率进行交换得到新的个体。交叉过程如下图所示:

变异
变异即对于一个染色体的任意位置的值以一定的概率 $P_m$ 发生变化,对于二进制编码来说即反转该位置的值。其中 $P_m$ 为一个较小的值,例如 $P_m = 0.05$。
小结
在整个遗传运算的过程中,不同的操作发挥着不同的作用:
- 选择:优胜劣汰,适者生存。
- 交叉:丰富种群,持续优化。
- 变异:随机扰动,避免局部最优。
除此之外,对于基本的遗传算法还有多种优化方法,例如:精英主义,即将每一代中的最优解原封不动的复制到下一代中,这保证了最优解可以存活到整个算法结束。
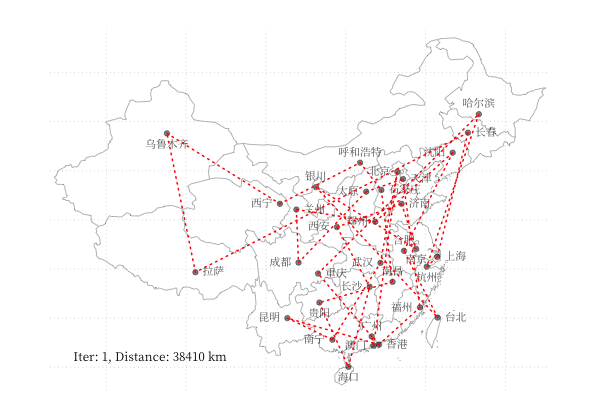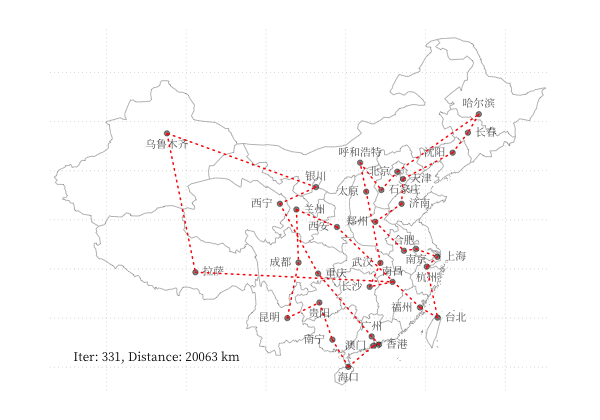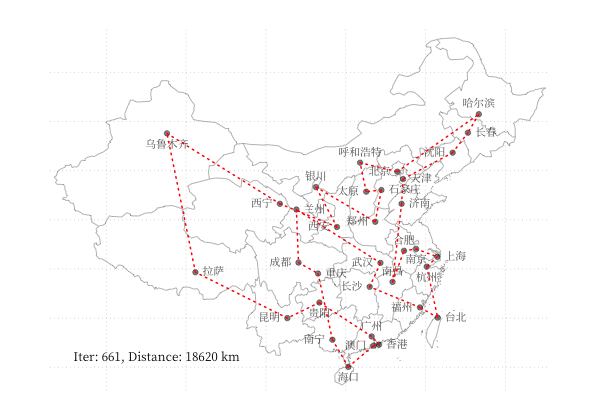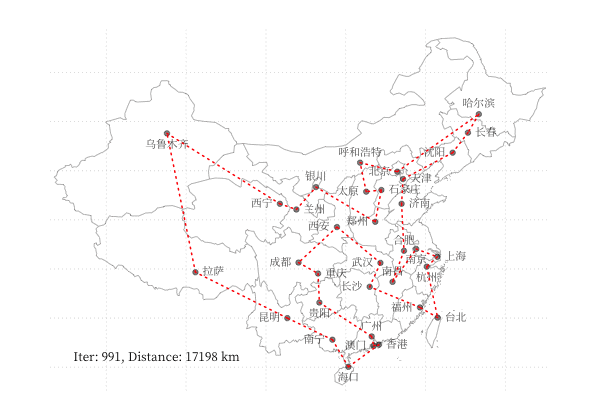
示例 - 商旅问题
以 商旅问题 为例,利用 GA 算法求解中国 34 个省会城市的商旅问题。求解代码利用了 Deap 库,结果可视化如下图所示:
一个更有趣的例子是利用 GA 算法,使用不同颜色和透明度的多边形的叠加表示一张图片,在线体验详见 这里,下图为不同参数下的蒙娜丽莎图片的表示情况:

蚁群算法 (Ant Colony Optimization, ACO)
1991 年,意大利学者 Dorigo M. 等人在第一届欧洲人工生命会议 (ECAL) 上首次提出了蚁群算法。1996 年 Dorigo M. 等人发表的文章 “Ant system: optimization by a colony of cooperating agents” 8 为蚁群算法奠定了基础。在自然界中,蚂蚁会分泌一种叫做信息素的化学物质,蚂蚁的许多行为受信息素的调控。蚂蚁在运动过程中能够感知其经过的路径上信息素的浓度,蚂蚁倾向朝着信息素浓度高的方向移动。以下图为例 9:
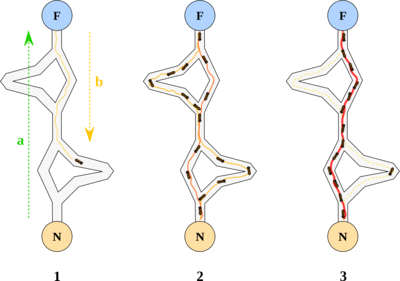
蚂蚁从蚁巢 (N) 出发到达食物源所在地 (F),取得食物后再折返回蚁巢。整个过程中蚂蚁有多种路径可以选择,单位时间内路径上通过蚂蚁的数量越多,则该路径上留下的信息素浓度越高。因此,最短路径上走过的蚂蚁数量越多,则后来的蚂蚁选择该路径的机率就越大,从而蚂蚁通过信息的交流实现了寻找食物和蚁巢之间最短路的目的。
粒子群算法 (Particle Swarm Optimization, PSO)
Eberhart, R. 和 Kennedy, J. 于 1995 年提出了粒子群优化算法 10 11。粒子群算法模仿的是自然界中鸟群和鱼群等群体的行为,其基本原理描述如下:
一个由 $m$ 个粒子 (Particle) 组成的群体 (Swarm) 在 $D$ 维空间中飞行,每个粒子在搜索时,考虑自己历史搜索到的最优解和群体内 (或邻域内) 其他粒子历史搜索到的最优解,在此基础上进行位置 (状态,也就是解) 的变化。令第 $i$ 个粒子的位置为 $x_i$,速度为 $v_i$,历史搜索的最优解对应的点为 $p_i$,群体内 (或邻域内) 所有粒子历史搜索到的最优解对应的点为 $p_g$,则粒子的位置和速度依据如下公式进行变化:
$$ \begin{equation} \begin{split} v^{k+1}_i &= \omega v^k_i + c_1 \xi \left(p^k_i - x^k_i\right) + c_2 \eta \left(p^k_g - x^k_i\right) \\ x^{k+1}_i &= x^k_i + v^{k+1}_i \end{split} \end{equation} $$
其中,$\omega$ 为惯性参数;$c_1$ 和 $c_2$ 为学习因子,其一般为正数,通常情况下等于 2;$\xi, \eta \in U \left[0, 1\right]$。学习因子使得粒子具有自我总结和向群体中优秀个体学习的能力,从而向自己的历史最优点以及群体内或邻域内的最优点靠近。同时,粒子的速度被限制在一个最大速度 $V_{max}$ 范围内。
对于 Rosenbrock 函数
$$ f \left(x, y\right) = \left(1 - x\right)^2 + 100 \left(y - x^2\right)^2 $$
当 $x \in \left[-2, 2\right], y \in \left[-1, 3\right]$,定义优化问题为最小化目标函数,最优解为 $\left(1, 1\right)$。利用 PySwarms 扩展包的优化过程可视化如下:
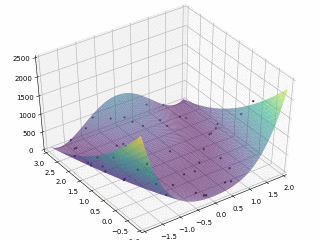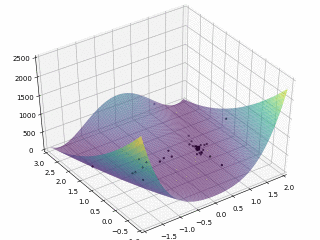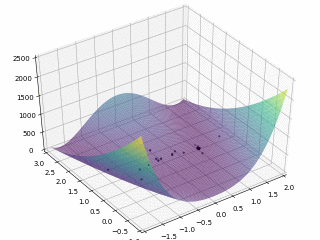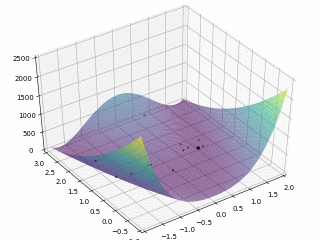
其中,$m = 50, \omega = 0.8, c_1 = 0.5, c_2 = 0.3$,迭代次数为 200。
本节相关示例代码详见 这里。
超启发式算法 (Hyper-Heuristic Algorithms)
超启发式算法 (Hyper-Heuristic Algorithms) 提供了一种高层次启发式方法,通过管理或操纵一系列低层次启发式算法 (Low-Level Heuristics,LLH),以产生新的启发式算法。这些新启发式算法被用于求解各类组合优化问题 12。
下图给出了超启发式算法的概念模型。该模型分为两个层面:在问题域层面上,应用领域专家根据自己的背景知识,在智能计算专家协助下,提供一系列 LLH 和问题的定义、评估函数等信息;在高层次启发式方法层面上,智能计算专家设计高效的管理操纵机制,运用问题域所提供的 LLH 算法库和问题特征信息,构造出新的启发式算法。
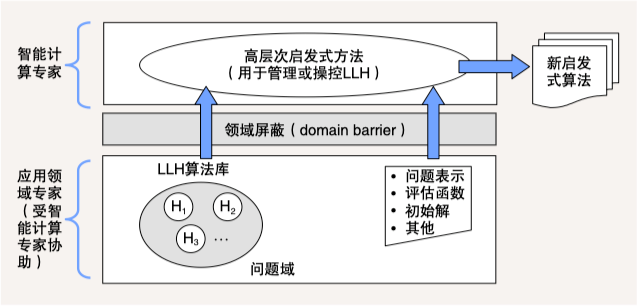
-
汪定伟, 王俊伟, 王洪峰, 张瑞友, & 郭哲. (2007). 智能优化方法. 高等教育出版社. ↩︎
-
Glover, F. W., & Laguna, M. (1997). Tabu Search. Springer US. ↩︎
-
Kirkpatrick, S., Gelatt, C. D., & Vecchi, M. P. (1983). Optimization by Simulated Annealing. Science, 220(4598), 671–680. ↩︎
-
Michalewicz, Z., Janikow, C. Z., & Krawczyk, J. B. (1992). A modified genetic algorithm for optimal control problems. Computers & Mathematics with Applications, 23(12), 83-94. ↩︎
-
Gottlieb, J., & Paulmann, L. (1998, May). Genetic algorithms for the fixed charge transportation problem. In Evolutionary Computation Proceedings, 1998. IEEE World Congress on Computational Intelligence., The 1998 IEEE International Conference on (pp. 330-335). IEEE. ↩︎
-
Dorigo, M., Maniezzo, V., & Colorni, A. (1996). Ant system: optimization by a colony of cooperating agents. IEEE Transactions on Systems, man, and cybernetics, Part B: Cybernetics, 26(1), 29-41. ↩︎
-
Toksari, M. D. (2016). A hybrid algorithm of Ant Colony Optimization (ACO) and Iterated Local Search (ILS) for estimating electricity domestic consumption: Case of Turkey. International Journal of Electrical Power & Energy Systems, 78, 776-782. ↩︎
-
Eberhart, R., & Kennedy, J. (1995, November). Particle swarm optimization. In Proceedings of the IEEE international conference on neural networks (Vol. 4, pp. 1942-1948). ↩︎
-
Eberhart, R., & Kennedy, J. (1995, October). A new optimizer using particle swarm theory. In MHS'95. Proceedings of the Sixth International Symposium on Micro Machine and Human Science (pp. 39-43). IEEE. ↩︎
-
江贺. (2011). 超启发式算法:跨领域的问题求解模式. 中国计算机学会通讯, 7(2), 63-70 ↩︎