本文为 Pre-trained Models for Natural Language Processing: A Survey 和相关模型的读书笔记 1。
在当下的 NLP 研究领域,随着计算机算力的不断增强,越来越多的通用语言表征的预训练模型(Pre-trained Models,PTMs)逐渐涌现出来。这对下游的 NLP 任务非常有帮助,可以避免大量从零开始训练新的模型。PTM 大致可以分为两代:
- 第一代 PTM 旨在学习词嵌入。由于下游任务不在需要这些模型,因此为了计算效率,这些模型往往采用浅层模型,例如 Skip-Gram 2,GloVe 3 等。尽管这些模型可以捕获词的语义,但由于未基于上下文环境,因此不能够捕捉到更深层次的概念,例如:句法结构,语义角色,指代等等。
- 第二代 PTM 专注于学习基于上下文的词嵌入,例如 CoVe 4,ELMo 5,OpenAI GPT 6 和 BERT 7 等。这些学习到的编码器在下游任务中仍会用于词在上下文中的语义表示。
预训练原理
语言表示学习
分布式表示的核心思想为用一个低维的实值向量表示一段文本,向量单独每个维度不具有任何实质含义,但整个向量表示了一个具体的概念。下图展示了一个 NLP 任务的一般神经网络架构:
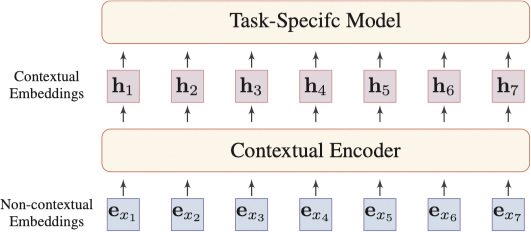
词嵌入包含两种类型:上下文无关的词嵌入和基于上下文的词嵌入。两者的不同点在于一个词的嵌入是够会随着上下文的不同而随之改变。
- 上下文无关的词嵌入
为了表征语义,我们需要将离散的语言符号映射到一个分布式嵌入空间中。对于词典 $\mathcal{V}$ 中的一个词 $x$,我们将其映射为查询表 $\mathbf{E} \in \mathbb{R}^{D_e \times \|\mathcal{V}\|}$ 中的一个向量 $\mathbf{e}_x \in \mathbb{R}^{D_e}$,其中 $D_e$ 为嵌入的维度。
这种类型的嵌入主要有两个缺陷:一是嵌入是静态的,词在不同的上下文中的嵌入表示是相同的,因此无法处理一词多义;二是未登录词(out-of-vocabulary,OOV)问题,通常可以采用字符级嵌入表示解决该问题。更多上下文无关的词嵌入模型,请参见之前的博客 词向量。
- 基于上下文的词嵌入
为了解决上述问题,我们需要区分在不同上下文下词的含义。给定一段文本 $x_1, x_2, \dotsc, x_T$ 其中每段标记 $x_t \in \mathcal{V}$ 为一个词或子词,$x_t$ 基于上下文的表示依赖于整段文本。
$$ \left[\mathbf{h}_1, \mathbf{h}_2, \dotsc, \mathbf{h}_T\right] = f_{\text{enc}} \left(x_1, x_2, \dotsc, x_T\right) $$
其中,$f_{\text{enc}} \left(\cdot\right)$ 为神经编码器,$\mathbf{h}_t$ 为标记 $x_t$ 的基于上下文的嵌入或动态嵌入。
神经上下文编码器
神经上下文编码器大致可以分为 3 类:
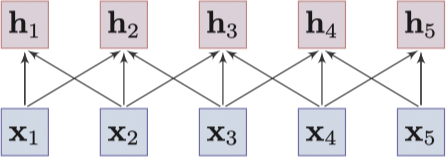
- 基于卷积的模型:基于卷积的模型通过卷积操作从一个词的邻居中聚合局部信息来捕获这个词的含义 8。
![Convolutional model]()
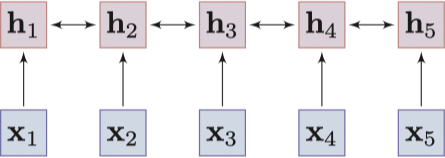
Convolutional model - 基于序列的模型:基于序列的模型采用 RNNs(LSTM 9 和 GRU 10) 来捕获词的上下文信息。实际中,我们采用双向的 RNNs 从词的两端收集信息,不过整体效果容易收到长期依赖问题的影响。
![Sequential model]()
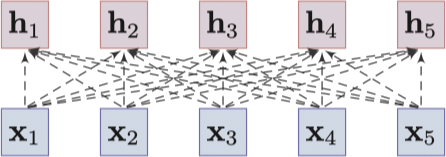
Sequential model - 基于图的模型:基于图的模型将字作为图中的一个节点来学习上下文表示,这个图通常是一个词之间预定义的语言结构,例如:语法结构 11 12 或语义关系 13。尽管基于语言学的图结构能提供有用的信息,但如何构建一个好的图结构则成为了难题。除此之外,基于语言学的图结构需要依赖专家知识和外部工具,例如:依存句法分析等。事实上,我们会采用一个更直接的方式去学习任意两个词之间的关系,通常连接的权重可以通过自注意力机制自动计算得出。Transformer 14 是一个采用了全链接自注意力架构的实现,同时也采用了位置嵌入(positional embedding),层标准化(layer normalization)和残差连接(residual connections)等网络设计理念。
![Fully-connected graph-based model]()
Fully-connected graph-based model
为什么预训练
对于大多数的 NLP 任务,构建一个大规模的有标签的数据集是一项很大的挑战。相反,大规模的无标签语料是相对容易构建的,为了充分利用这些无标签数据,我们可以先利用它们获取一个好的语言表示,再将这些表示用于其他任务。预训练的好处如下:
- 预训练可以从大规模语料中学习得到通用的语言表示,并用于下游任务。
- 预训练提供了更优的模型初始化方法,有助于提高模型的泛化能力和加速模型收敛。
- 预训练可以当作是在小数据集上一种避免过拟合的正则化方法。
预训练任务
预训练任务对于学习语言的通用表示来说至关重要。通常情况下,预训练任务具有挑战性,同时需要大量训练数据。我们将预训练任务划分为 3 类:
- 监督学习,即从包含输入输出对的训练数据中学习一个由输入到输出的映射函数。
- 非监督学习,即从无标签数据获取一些固有的知识,例如:聚类,密度,潜在表征等。
- 自监督学习,是监督学习和非监督学习的混合体,核心思想是对于输入的一部分利用其他部分进行预测。
语言模型(Language Modeling,LM)
NLP 中最常见的非监督任务为概率语言建模,这是一个经典的概率密度估计问题。给定一个文本序列 $x_{1:T} = \left[x_1, x_2, \dotsc, x_T\right]$,他的联合概率 $p \left(x_{1:T}\right)$ 可以分解为:
$$ p \left(x_{1:T}\right) = \prod_{t=1}^{y}{p \left(x_t \mid x_{0:t-1}\right)} $$
其中 $x_0$ 为序列开始的特殊标记。条件概率 $p \left(x_t \mid x_{0:t-1}\right)$ 可以通过给定的语言上下文 $x_{0:t-1}$ 词的概率分布进行建模估计。上下文 $x_{0:t-1}$ 可以通过神经编码器 $f_{\text{enc}} \left(\cdot\right)$ 进行建模,则条件概率可以表示为:
$$ p \left(x_t | x_{0:t-1}\right) = g_{\text{LM}} \left(f_{\text{enc}} \left(x_{0:t-1}\right)\right) $$
其中,$g_{\text{LM}}$ 为预测层。
遮罩语言模型(Masked Language Modeling,MLM)
大致上来说,MLM 首先将输入句子的一些词条进行遮挡处理,其次再训练模型利用剩余的部分预测遮挡的部分。这种预训练方法会导致在预训练(pre-training)阶段和微调(fine-tuning)阶段的不一致,因为在微调阶段遮挡标记并未出现,BERT 15 通过一个特殊的符号 [MASK] 对其进行处理。
Sequence-to-Sequence MLM (Seq2Seq MLM)
MLM 通常以一个分类问题进行求解,我们将遮挡后的序列输入到一个神经编码器,再将输出向量传给一个 Softmax 分类器来预测遮挡的字符。我们可以采用 Encoder-Decoder(Seq2Seq)网络结构,将遮挡的序列输入到 Encoder,Decoder 则会循序的产生被遮挡的字符。MASS 16 和 T5 17 均采用了这种序列到序列的 MLM 结构,这种结构对 Seq2Seq 风格的下游任务很有帮助,例如:问答,摘要和机器翻译。
Enhanced Masked Language Modeling (E-MLM)
同时,大量研究对于 BERT 所使用的遮罩处理进行了改进。RoBERTa 18 采用了一种动态的遮罩处理。UniLM 将遮罩任务拓展到 3 种不同的类型:单向的,双向的和 Seq2Seq 类型的。
排列语言模型(Permuted Language Modeling,PLM)
在 MLM 中一些特殊字符(例如:[MASK])在下游任务中是无用的,为了解决这个问题,XLNet 19 提出了一种排列语言模型(Permuted Language Modeling,PLM)用于替代 MLM。简言之,PLM 是对输入序列的排列进行语言建模。给定一个序列,从所有可能的排列中随机抽样得到一个排列,将排列后的序列中的一些字符作为模型的预测目标,利用其他部分和目标的自然位置进行训练。需要注意的是这种排列并不会影响序列的自然位置,其仅用于定义字符预测的顺序。
去噪自编码(Denoising Autoencoder,DAE)
DAE 旨在利用部分有损的输入恢复原始无损的输入。对于语言模型,例如 Seq2Seq 模型,可以采用标准的 Transformer 来重构原始文本。有多种方式可以对文本进行破坏 20:
- 字符遮罩:随机采样字符并将其替换为
[MASK]。 - 字符删除:随机的从输入中删除字符,不同于字符遮罩,模型需要确定丢失字符的位置。
- 文本填充:采样一段文本并将其替换为一个
[MASK],每段文本的长度服从泊松分布($\lambda = 3$),模型需要确定这段文本中缺失的字符个数。 - 句子重排:将文档以终止标点进行分割,再进行随机排序。
- 文档旋转:随机均匀地选择一个字符,对文档进行旋转使得这个字符作为文档的起始字符,模型需要确定文档真实的起始位置。
对比学习(Contrastive Learning,CTL)
对比学习 21 假设一些观测到的文本对比随机采样的文本具有更相似的语义。对于文本对 $\left(x, y\right)$ 通过最小化如下目标函数来学习评分函数 $s \left(x, y\right)$:
$$ \mathbb{E}_{x, y^+, y^-} \left[- \log \dfrac{\exp \left(s \left(x, y^+\right)\right)}{\exp \left(s \left(x, y^+\right)\right) + \exp \left(s \left(x, y^-\right)\right)}\right] $$
其中,$\left(x, y^+\right)$ 为一个相似对,$y^-$ 对于 $x$ 而言假定为不相似,$y^+$ 和 $y^-$ 通常称之为正样本和负样本。评分函数 $s \left(x, y\right)$ 通过一个神经编码器计算可得,$s \left(x, y\right) = f^{\top}_{\text{enc}} \left(x\right) f_{\text{enc}} \left(y\right)$ 或 $s \left(x, y\right) = f_{\text{enc}} \left(x \oplus y\right)$。CTL 的核心思想是“通过对比进行学习”。
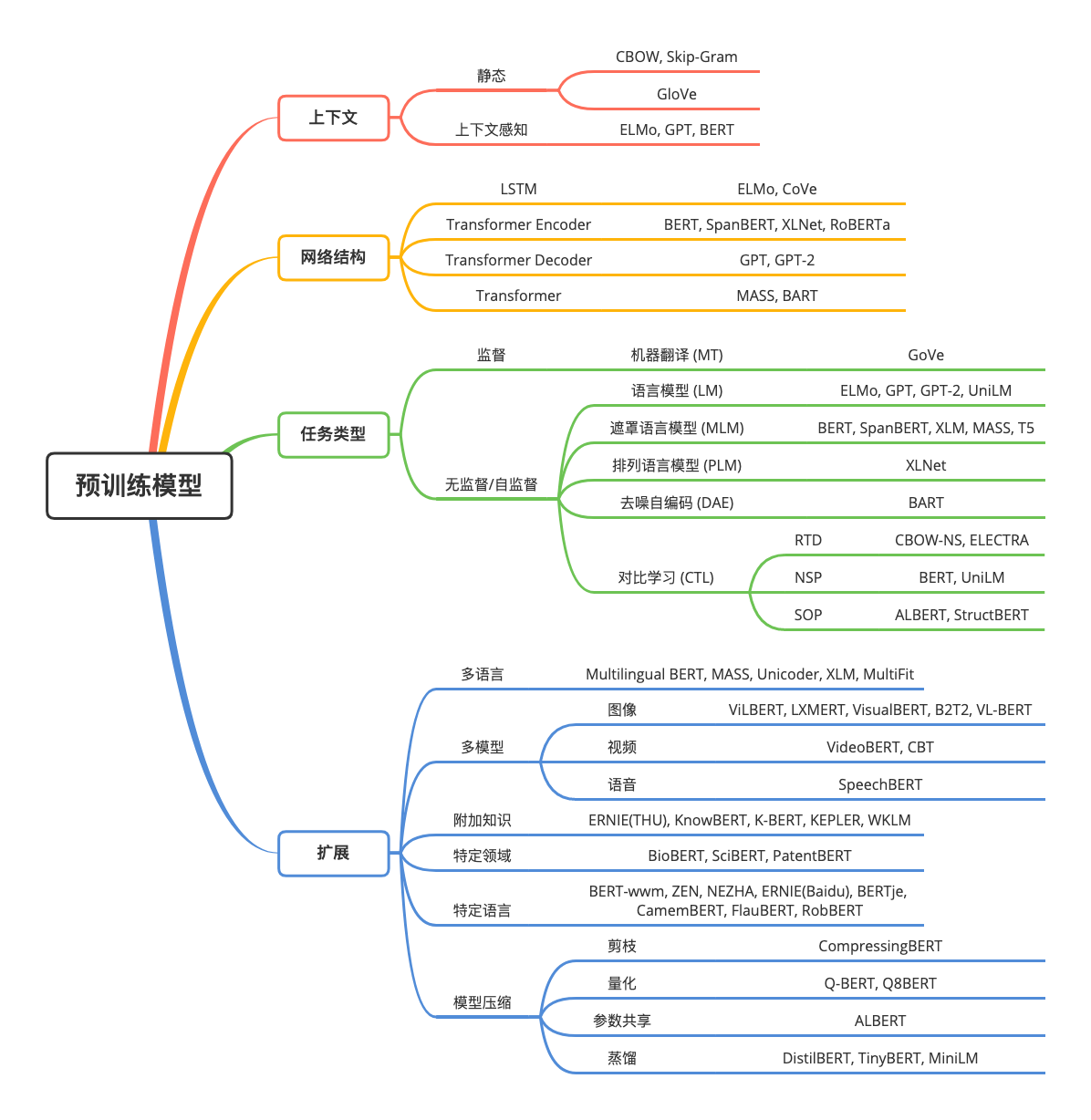
下图展示了预训练模型的分类和部分代表模型:
应用于下游任务
如何迁移
选择合适的预训练任务,模型架构和语料
不同的 PTMs 在相同的下游任务上有着不同的效果,这是因为 PTMs 有着不同的预训练任务,模型架构和语料。
- 目前,语言模型是最流行的预训练任务,同时也可以有效地解决很多 NLP 问题。但是不同的预训练任务有着自己的侧重,在不同的任务上会有不同的效果。例如:NSP 任务使得 PTM 可以理解两句话之间的关系,因此 PTM 可以在例如问答(Question Answering,QA)和自然语言推理(Natural Language Inference,NLI)等下游任务上表现更好。
- PTM 的网络架构对下游任务也至关重要。例如:尽管 BERT 可以处理大多数自然语言理解任务,对其很难生成语言。
- 下游任务的数据分布应该和 PTM 训练所用语料相似。目前,大量现成的 PTM 仅可以快速地用于特定领域或特定语言的下游任务上。
选择合适的网络层
给定一个预训练的模型,不同的网络层捕获了不同的信息,例如:词性标记(POS tagging),语法(parsing),长期依赖(long-term dependencies),语义角色(semantic roles),指代(coreference)等。Tenney 22 等人发现 BERT 表示方式类似传统的 NLP 流程:基础的句法信息出现在浅层的网络中,高级的语义信息出现在更高的层级中。
令 $\mathbf{H}^{\left(l\right)} \left(1 \leq l \leq L\right)$ 表示共 $L$ 层的预训练模型的第 $l$ 层表示,$g \left(\cdot\right)$ 表示用于特定任务的的模型。一般有 3 中情况选择表示:
- Embedding Only:一种情况是仅选用预训练模型的静态嵌入,模型的其他部分仍需作为一个任务从头训练。这种情况不能够获取到一些有用的深层信息,词嵌入仅能够捕获词的语义信息。
- Top Layer:最简单有效的方式是将网络的顶层表示输入到模型中
$g \left(\mathbf{H}^{\left(L\right)}\right)$。 - All Layers:另一种更灵活的方式是自动选择最合适的层,例如 ELMo:
$$ \mathbf{r}_t = \gamma \sum_{l=1}^{L}{\alpha_l \mathbf{h}^{\left(l\right)}_t} $$其中$\alpha_l$是层$l$的 softmax 归一的权重,$\gamma$是用于缩放预训练模型输出向量的一个标量值,再将不同层的混合输出输入到后续模型中$g \left(\mathbf{r}_t\right)$。
是否微调
目前,主要有两种方式进行模型迁移:特征提取(预训练模型的参数是固定的)和模型微调(预训练模型的参数是经过微调的)。当采用特征提取时,预训练模型可以被看作是一个特征提取器。除此之外,我们应该采用内部层作为特征,因为他们通常是最适合迁移的特征。尽管两种不同方式都能对大多数 NLP 任务效果有显著提升,但以特征提取的方式需要更复杂的特定任务的架构。因此,微调是一种更加通用和方便的处理下游任务的方式。
微调策略
随着 PTMs 网络层数的加深,其捕获的表示使得下游任务变得越来越简单,因此整个模型中用于特定任务的网络层一般比较简单,微调已经成为了采用 PTMs 的主要方式。但是微调的过程通常是比较不好预估的,即使采用相同的超参数,不同的随机数种子也可能导致差异较大的结果。除了标准的微调外,如下为一些有用的微调策略:
两步骤微调
一种方式是两阶段的迁移,在预训练和微调之间引入了一个中间阶段。在第一个阶段,PTM 通过一个中间任务或语料转换为一个微调后的模型,在第二个阶段,再利用目标任务进行微调。
多任务微调
在多任务学习框架下对其进行微调。
利用额外模块进行微调
微调的主要缺点就是其参数的低效性。每个下游模型都有其自己微调好的参数,因此一个更好的解决方案是将一些微调好的适配模块注入到 PTMs 中,同时固定原始参数。
开放资源
PTMs 开源实现:
| 项目 | 框架 | PTMs |
|---|---|---|
| word2vec | - | CBOW, Skip-Gram |
| GloVe | - | Pre-trained word vectors |
| FastText | - | Pre-trained word vectors |
| Transformers | PyTorch & TF | BERT, GPT-2, RoBERTa, XLNet, etc. |
| Fairseq | PyTorch | English LM, German LM, RoBERTa, etc. |
| Flair | PyTorch | BERT, ELMo, GPT, RoBERTa, XLNet, etc. |
| AllenNLP | PyTorch | ELMo, BERT, GPT-2, etc. |
| FastNLP | PyTorch | BERT, RoBERTa, GPT, etc. |
| Chinese-BERT | - | BERT, RoBERTa, etc. (for Chinese) |
| BERT | TF | BERT, BERT-wwm |
| RoBERTa | PyTorch | |
| XLNet | TF | |
| ALBERT | TF | |
| T5 | TF | |
| ERNIE(THU) | PyTorch | |
| ERNIE(Baidu) | PaddlePaddle | |
| Hugging Face | PyTorch & TF | 很多… |
论文列表和 PTMs 相关资源:
| 资源 | URL |
|---|---|
| 论文列表 | https://github.com/thunlp/PLMpapers |
| 论文列表 | https://github.com/tomohideshibata/BERT-related-papers |
| 论文列表 | https://github.com/cedrickchee/awesome-bert-nlp |
| Bert Lang Street | https://bertlang.unibocconi.it |
| BertViz | https://github.com/jessevig/bertviz |
预训练模型
CoVe (2017) 4
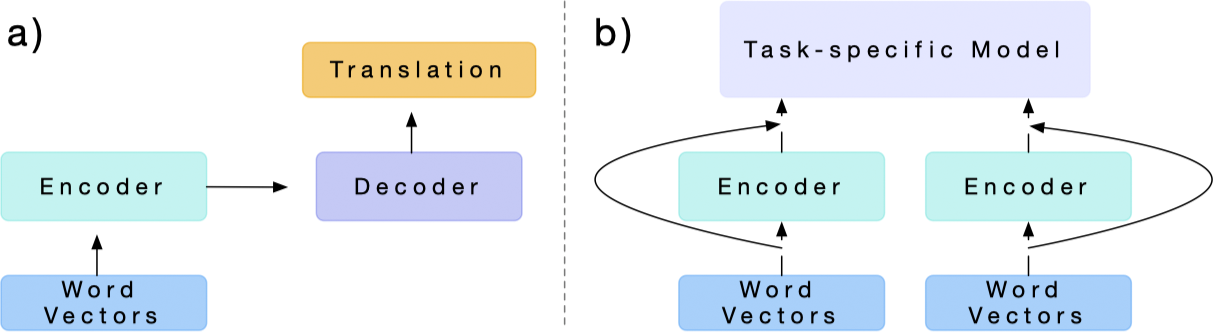
首先,给定一个源语言序列 $w^x = \left[w^x_1, \dotsc, w^x_n\right]$ 和一个翻译目标语言序列 $w^z = \left[w^z_1, \dotsc, w^z_n\right]$。令 $\text{GloVe} \left(w^x\right)$ 为词 $w^x$ 对应的 GloVe 向量,$z$ 为 $w^z$ 中的词随机初始化的词向量。将 $\text{GloVe} \left(w^x\right)$ 输入到一个标准的两层 biLSTM 网络中,称之为 MT-LSTM,MT-LSTM 用于计算序列的隐含状态如下:
$$ h = \text{MT-LSTM} \left(\text{GloVe} \left(w^x\right)\right) $$
对于机器翻译,MT-LSTM 的注意力机制的解码器可以对于输出的词在每一步产生一个分布 $p \left(\hat{w}^z_t \mid H, w^z_1, \dotsc, w^z_{t-1}\right)$。在 $t$ 步,解码器利用一个两层的单向 LSTM 基于之前目标词嵌入 $z_{t-1}$ 和一个基于上下文调整的隐含状态 $\tilde{h}_{t-1}$ 生成一个隐含状态 $h^{\text{dec}}_t$:
$$ h^{\text{dec}}_t = \text{LSTM} \left(\left[z_{t-1}; \tilde{h}_{t-1}\right], h^{\text{dec}}_{t-1}\right) $$
之后解码器计算每一步编码到当前解码状态的注意力权重 $\alpha$:
$$ \alpha_t = \text{softmax} \left(H \left(W_1 h^{\text{dec}}_t + b_1\right)\right) $$
其中 $H$ 表示 $h$ 按照时间维度的堆叠。之后解码器将这些权重作为相关性用于计算基于上下文调整的隐含状态 $\tilde{h}$:
$$ \tilde{h}_t = \text{tanh} \left(W_2 \left[H^{\top} \alpha_t; h^{\text{dec}}_t\right] + b_2\right) $$
最后,输出词的分布通过基于上下文调整的隐含状态计算可得:
$$ p \left(\hat{w}^z_t \mid H, w^z_1, \dotsc, w^z_{t-1}\right) = \text{softmax} \left(W_{\text{out}} \tilde{h}_t + b_{\text{out}}\right) $$
CoVe 将 MT-LSTM 学习到的表示迁移到下游任务中,令 $w$ 表示文字序列,$\text{GloVe} \left(w\right)$ 表示对应的 GloVe 向量,则:
$$ \text{CoVe} \left(w\right) = \text{MT-LSTM} \left(\text{GloVe} \left(w\right)\right) $$
表示由 MT-LSTM 产生的上下文向量,对于分类和问答任务,有一个输入序列 $w$,我们可以将 GloVe 和 CoVe 向量进行拼接作为其嵌入表示:
$$ \tilde{w} = \left[\text{GloVe} \left(w\right); \text{CoVe} \left(w\right)\right] $$
CoVe 网络架构示意图如下:
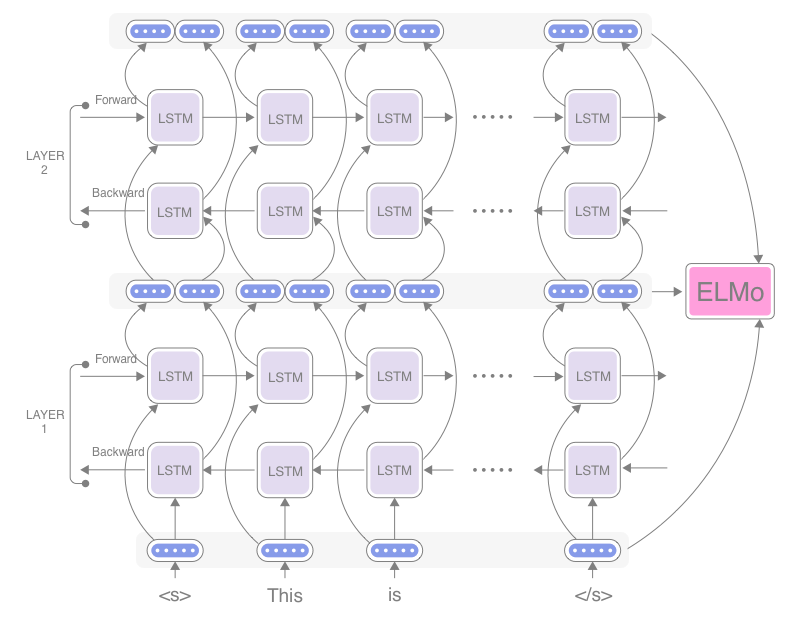
ELMo (2018) 5
在 ELMo 模型中,对于每个词条 $t_k$,一个 $L$ 层的 biLM 可以计算得到 $2L + 1$ 个表示:
$$ \begin{aligned} R_k &= \left\{\mathbf{x}^{LM}_k, \overrightarrow{\mathbf{h}}^{LM}_{k, j}, \overleftarrow{\mathbf{h}}^{LM}_{k, j} \mid j = 1, \dotsc, L \right\} \\ &= \left\{\mathbf{h}^{LM}_{k, j} \mid j = 0, \dotsc, L\right\} \end{aligned} $$
其中 $\mathbf{h}^{LM}_{k, 0}$ 为词条的嵌入层,$\mathbf{h}^{LM}_{k, j} = \left[\overrightarrow{\mathbf{h}}^{LM}_{k, j}; \overleftarrow{\mathbf{h}}^{LM}_{k, j}\right]$ 为每个 biLSTM 层。
对于下游任务,ELMo 将 $R$ 中的所有层汇总成一个向量 $\mathbf{ELMo}_k = E \left(R_k; \mathbf{\Theta}_e\right)$。在一些简单的案例中,ELMo 仅选择顶层,即:$E \left(R_k\right) = \mathbf{h}^{LM}_{k, L}$。更通用的,对于一个特定的任务,我们可以计算一个所有 biLM 层的加权:
$$ \mathbf{ELMo}^{task}_k = E \left(R_k; \Theta^{task}\right) = \gamma^{task} \sum_{j=0}^{L}{s^{task}_j \mathbf{h}^{LM}_{k, j}} $$
其中,$s^{task}$ 表示 softmax 归一化后的权重,$\gamma^{task}$ 允许模型对整个 ELMo 向量进行缩放。$\gamma$ 对整个优化过程具有重要意义,考虑每个 biLM 层的激活具有不同的分布,在一些情况下这相当于在进行加权之前对每一个 biLM 层增加了层标准化。
ELMo 网络架构示意图如下 23:
GPT (2018) 6
给定一个语料 $\mathcal{U} = \left\{u_1, \dotsc, u_n\right\}$,使用标准的语言建模目标来最大化如下似然:
$$ L_1 \left(\mathcal{U}\right) = \sum_{i} \log P \left(u_i \mid u_{i-k}, \dotsc, u_{i-1}; \Theta\right) $$
其中,$k$ 为上下文窗口的大小,条件概率 $P$ 通过参数为 $\Theta$ 的神经网络进行建模。GPT 中使用了一个多层的 Transformer Decoder 作为语言模型。模型首先对输入上下文词条应用多头自注意力机制,再通过按位置的前馈层产生目标词条的输出分布:
$$ \begin{aligned} h_0 &= UW_e + W_p \\ h_l &= \text{transformer\_black} \left(h_{l-1}\right), \forall i \in \left[1, n\right] \\ P \left(u\right) &= \text{softmax} \left(h_n W^{\top}_e\right) \end{aligned} $$
其中,$U = \left(u_{-k}, \dotsc, u_{-1}\right)$ 为词条的上下文向量,$n$ 为网络层数,$W_e$ 为词条的嵌入矩阵,$W_p$ 为位置嵌入矩阵。
给定一个有标签的数据集 $\mathcal{C}$,其中包含了输入词条序列 $x^1, \dotsc, x^m$ 和对应的标签 $y$。利用上述预训练的模型获得输入对应的最后一个 Transformer 的激活输出 $h^m_l$,之后再将其输入到一个参数为 $W_y$ 的线性输入层中预测 $y$:
$$ P \left(y \mid x^1, \dotsc, x^m\right) = \text{softmax} \left(h^m_l W_y\right) $$
模型通过最小化如下损失进行优化:
$$ L_2 \left(\mathcal{C}\right) = \sum_{\left(x, y\right)} \log P \left(y \mid x^1, \dotsc, x^m\right) $$
研究还发现将语言建模作为微调的附加目标可以帮助提高模型的泛化能力,同时可以加速模型收敛。GPT 中采用如下的优化目标:
$$ L_3 \left(\mathcal{C}\right) = L_2 \left(\mathcal{C}\right) + \lambda L_1 \left(\mathcal{C}\right) $$
GPT 网络架构示意图如下:
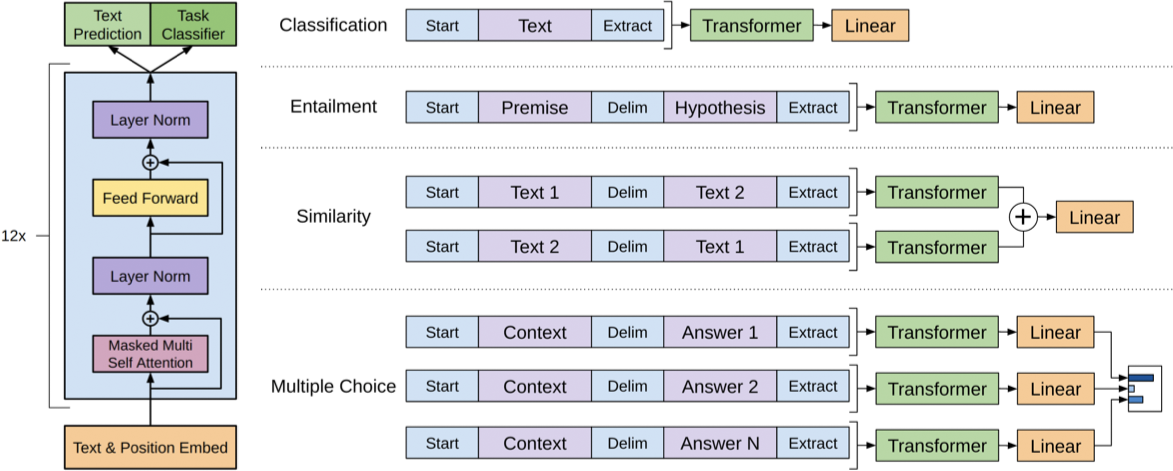
BERT (2018) 7
BERT 采用了一中基于 Vaswani 14 所提出模型的多层双向 Transformer 编码器。在 BERT 中,令 $L$ 为 Transformer Block 的层数,$H$ 为隐层大小,$A$ 为自注意力头的数量。在所有情况中,设置前馈层的大小为 $4H$,BERT 提供了两种不同大小的预训练模型:
$\text{BERT}_{\text{BASE}}$:$L=12, H=768, A=12$,参数总量为 100 M。$\text{BERT}_{\text{LARGE}}$:$L=24, H=1024, A=16$,参数总量为 340 M。
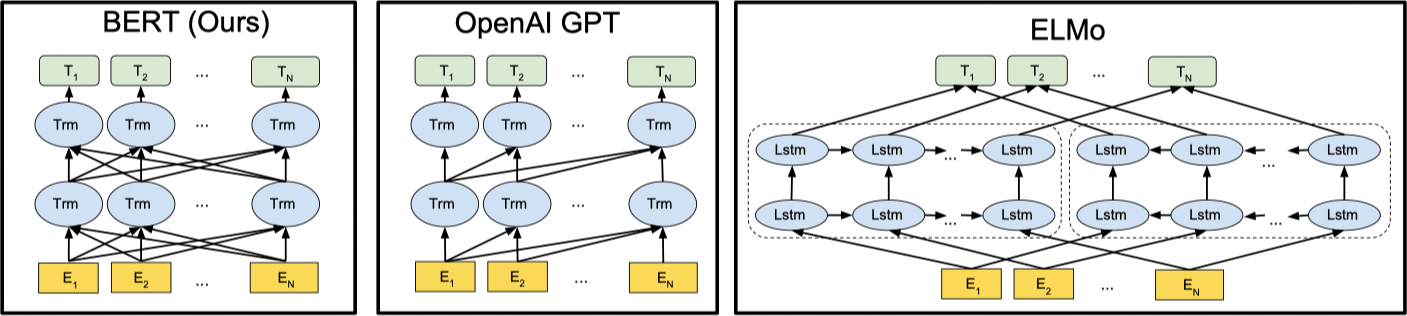
$\text{BERT}_{\text{BASE}}$ 采用了同 GPT 相同的模型大小用于比较,不同与 GPT,BERT 使用了双向的注意力机制。在文献中,双向 Transformer 通常称之为 Transformer 编码器,仅利用左边上下文信息的 Transformer 由于可以用于文本生成被称之为 Transformer 解码器。BERT,GPT 和 ELMo 之间的不同如下图所示:
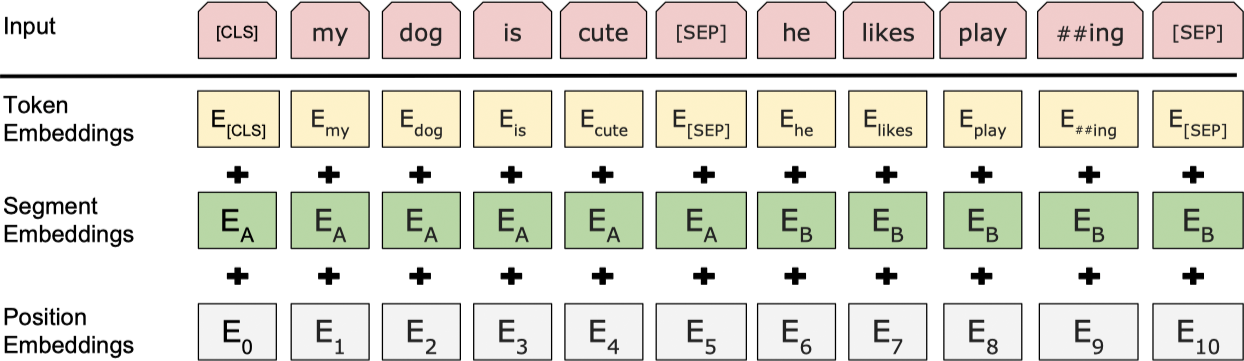
BERT 的输入表示既可以表示一个单独的文本序列,也可以表示一对文本序列(例如:问题和答案)。对于一个给定的词条,其输入表示由对应的词条嵌入,分割嵌入和位置嵌入三部分加和构成,如下图所示:
具体的有:
- 采用一个包含 30,000 个词条的 WordPiece 嵌入 24。
- 位置嵌入最大支持 512 个词条。
- 序列的第一字符采用特殊的分类嵌入
[CLS],其最终的隐含状态在分类任务中用于汇总整个序列的表示,对于非分类任务则忽视该向量。 - 句子对被整合成一个序列,首先利用一个特殊词条
[SEP]对句子进行分割,其次对于第一个句子中的每个词条叠加一个学习到的 A 句子嵌入,对于第二个句子中的每个词条叠加一个学习到的 B 句子嵌入。 - 对于一个单独的句子,仅使用 A 句子嵌入。
在预训练阶段,BERT 采用了两个无监督预测任务:
- 遮罩的语言模型(Masked LM,MLM)
不同于一般的仅利用[MASK]进行遮挡,BERT 选择采用 80% 的[MASK],10% 的随机词和 10% 保留原始词的方式对随机选择的 15% 的词条进行遮挡处理。由于编码器不知会预测哪个词或哪个词被随机替换了,这迫使其必须保留每个输入词条的分布式上下文表示。同时 1.5% 的随机替换也不会过多的损害模型的理解能力。 - 预测是否为下一个句子(Next Sentence Prediction)
一些重要的下游任务,例如问答(Question Answering,QA)和自然语言推断(Natural Language Inference,NLI)是基于两个句子之间关系的理解,这是语言建模无法直接捕获的。BERT 通过训练一个预测是否为下一个句子的二分类任务来实现,对于一个句子对 A 和 B,50% 的 B 是句子 A 真实的下一句,剩余 50% 为随机抽取的。
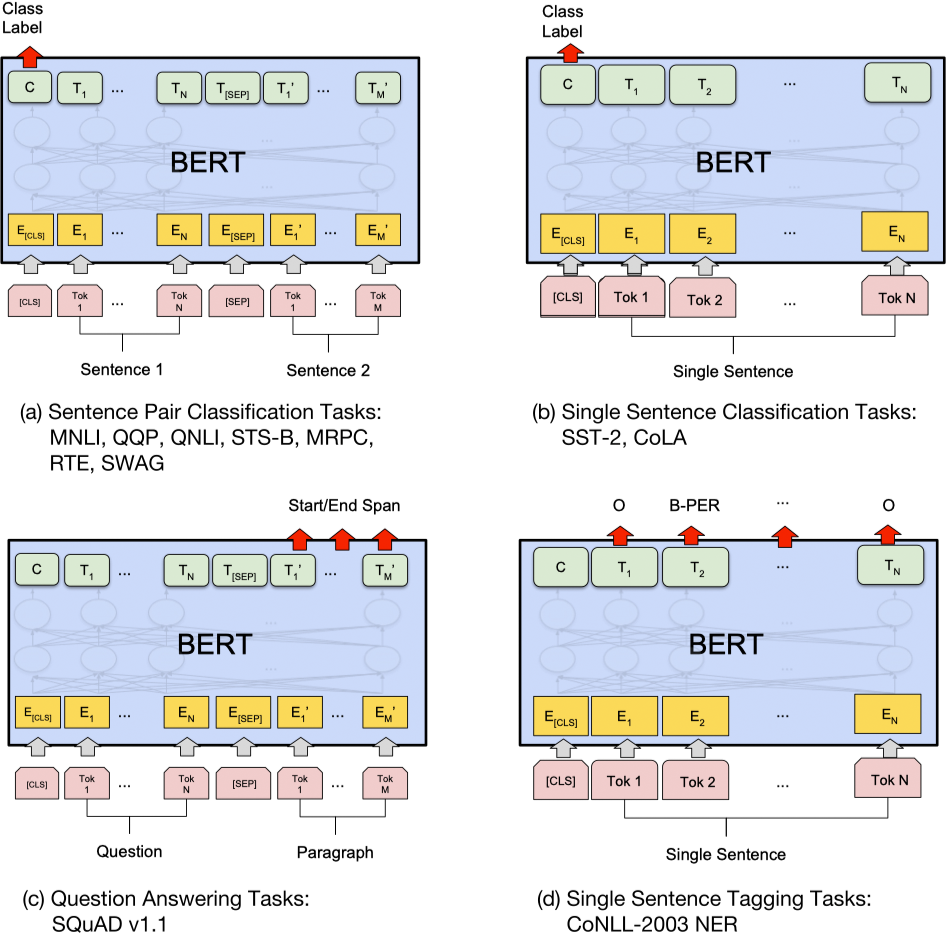
基于 BERT 的不同下游任务的实现形式如下图所示:
UniLM (2019) 25
给定一个输入序列 $x = x_1 \cdots x_{|x|}$,UniLM 通过下图的方式获取每个词条的基于上下文的向量表示。整个预训练过程利用单向的语言建模(unidirectional LM),双向的语言建模(bidirectional LM)和 Seq2Seq 语言建模(sequence-to-sequence LM)优化共享的 Transformer 网络。
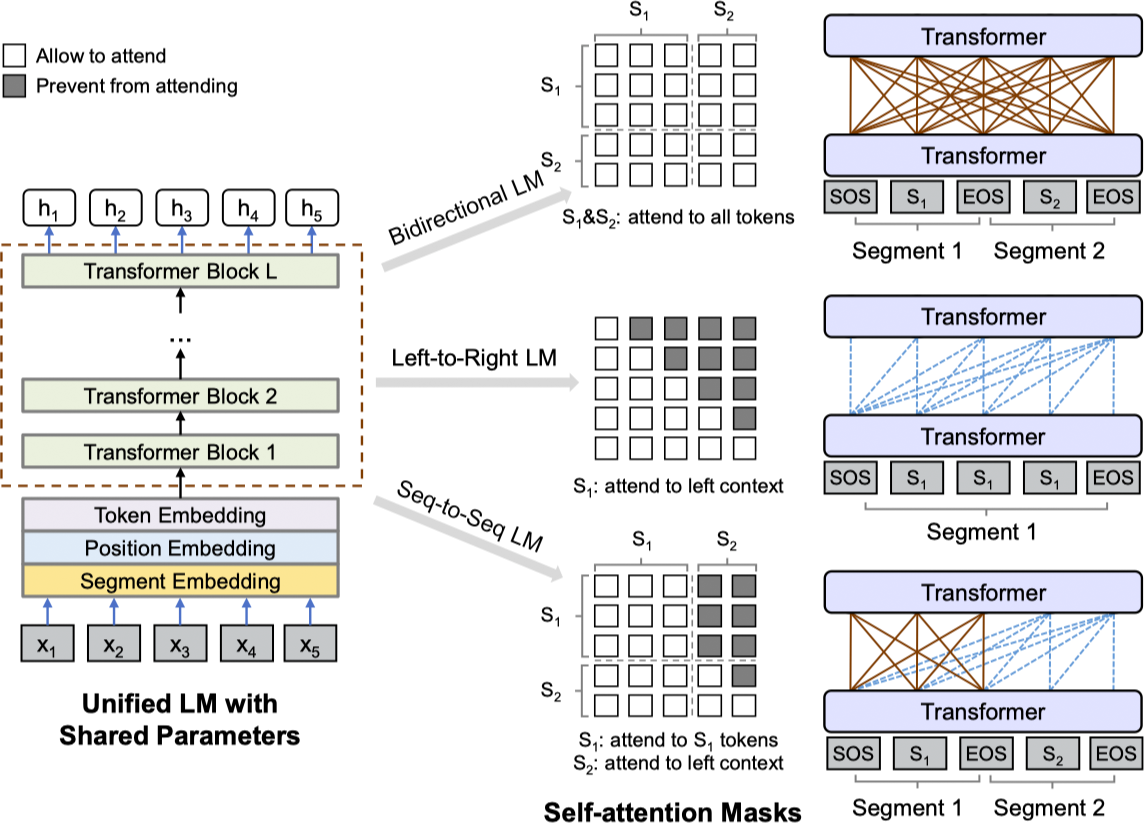
输入序列 $x$ 对于单向语言模型而言是一个分割的文本,对于双向语言模型和 Seq2Seq 语言模型而言是一对打包的分割文本。UniLM 在输入的起始位置添加特殊的 [SOS] (start-of-sequence),在结尾处添加 [EOS](end-of-sequence)。[EOS] 对于自然语言理解(NLU)任务可以标记句子之间的界线,对于自然语言生成(NLG)任务可以确定解码过程停止的时间。输入的表示同 BERT 一样,文本利用 WordPiece 进行分割,对于每个输入词条,其向量表示为对应的词条嵌入,位置嵌入和分割嵌入的汇总。
对于输入向量 $\left\{\mathbf{x}_i\right\}^{|x|}_{i=1}$ 首先将其输入到隐层 $\mathbf{H}^0 = \left[\mathbf{x}_1, \dotsc, \mathbf{x}_{|x|}\right]$,之后使用一个 $L$ 层的 Transformer $\mathbf{H}^l = \text{Transformer}_l \left(\mathbf{H}^{l-1}\right), l \in \left[1, L\right]$ 对每一层 $\mathbf{H}^l = \left[\mathbf{h}^l_1, \dotsc, \mathbf{h}^l_{|x|}\right]$ 进行上下文表示编码。在每个 Tansformer 块中,使用多头自注意力机制对输出向量和上一层进行汇总,第 $l$ 层 Transformer 自注意力头 $\mathbf{A}_l$ 的输入通过如下方式计算:
$$ \begin{aligned} \mathbf{Q} &= \mathbf{H}^{l-1} \mathbf{W}^Q_l, \mathbf{K} = \mathbf{H}^{l-1} \mathbf{W}^K_l, \mathbf{V} = \mathbf{H}^{l-1} \mathbf{W}^W_l \\ \mathbf{M}_{ij} &= \begin{cases} 0, & \text{allow to attend} \\ -\infty, & \text{prevent from attending} \end{cases} \\ \mathbf{A}_l &= \text{softmax} \left(\dfrac{\mathbf{Q} \mathbf{K}^{\top}}{\sqrt{d_k}} + \mathbf{M}\right) \mathbf{V}_l \end{aligned} $$
其中,上一层的输出 $\mathbf{H}^{l-1} \in \mathbb{R}^{|x| \times d_h}$ 通过参数矩阵 $\mathbf{W}^Q_l, \mathbf{W}^K_l, \mathbf{W}^V_l \in \mathbb{R}^{d_h \times d_k}$ 线性地映射为相应的 Query,Key 和 Value,遮罩矩阵 $\mathbf{M} \in \mathbb{R}^{|x| \times |x|}$ 用于确定一对词条是否可以被相互连接。
Transformer-XL (2019) 26
将 Transformer 或注意力机制应用到语言建模中的核心问题是如何训练 Transformer 使其有效地将一个任意长文本编码为一个固定长度的表示。Transformer-XL 将整个语料拆分为较短的段落,仅利用每段进行训练并忽略之前段落的上下文信息。这种方式称之为 Vanilla Model 27,如下图所示:
在这种训练模式下,无论是前向还是后向信息都不会跨越分割的段落进行传导。利用固定长度的上下文主要有两个弊端:
- 这限制了最大依赖的长度,虽然自注意力机制不会像 RNN 一样受到梯度弥散的影响,但 Vanilla Model 也不能完全利用到这个优势。
- 虽然可以利用补全操作来实现句子或其他语义的分割,但实际上通常会简单的将一个长文本截断成一个固定长度的分割,这样会产生上下文分裂破碎的问题。
为了解决这个问题,Transformer-XL 采用了一种循环机制的 Transformer。在训练阶段,在处理新的分割段落时,之前分割分部分的隐含状态序列将被固定(fixed)和缓存(cached)下来作为一个扩展的上下文被复用参与计算,如下图所示:
虽然梯度仍仅限于这个分割段落内部,但网络可以从历史中获取信息,从而实现对长期依赖的建模。令两个长度为 $L$ 的连续分割段落为 $\mathbf{s}_{\tau} = \left[x_{\tau, 1}, \dotsc, x_{\tau, L}\right]$ 和 $\mathbf{s}_{\tau + 1} = \left[x_{\tau + 1, 1}, \dotsc, x_{\tau + 1, L}\right]$,第 $\tau$ 段分割 $\mathbf{s}_{\tau}$ 的第 $n$ 层隐含状态为 $\mathbf{h}^n_{\tau} \in \mathbb{R}^{L \times d}$,其中 $d$ 为隐含维度。则对于分割段落 $\mathbf{s}_{\tau + 1}$ 的第 $n$ 层隐含状态通过如下方式进行计算:
$$ \begin{aligned} \tilde{\mathbf{h}}^{n-1}_{\tau + 1} &= \left[\text{SG} \left(\mathbf{h}^{n-1}_{\tau}\right) \circ \mathbf{h}^{n-1}_{\tau + 1} \right] \\ \mathbf{q}^{n}_{\tau + 1}, \mathbf{k}^{n}_{\tau + 1}, \mathbf{v}^{n}_{\tau + 1} &= \mathbf{h}^{n-1}_{\tau + 1} \mathbf{W}^{\top}_{q}, \tilde{\mathbf{h}}^{n-1}_{\tau + 1} \mathbf{W}^{\top}_{k}, \tilde{\mathbf{h}}^{n-1}_{\tau + 1} \mathbf{W}^{\top}_{v} \\ \mathbf{h}^{n}_{\tau + 1} &= \text{Transformer-Layer} \left(\mathbf{q}^{n}_{\tau + 1}, \mathbf{k}^{n}_{\tau + 1}, \mathbf{v}^{n}_{\tau + 1}\right) \end{aligned} $$
其中,$\text{SG} \left(\cdot\right)$ 表示停止梯度,$\left[\mathbf{h}_u \circ \mathbf{h}_v\right]$ 表示将两个隐含序列按照长度维度进行拼接,$\mathbf{W}$ 为模型的参数。与一般的 Transformer 相比,最大的不同在于 $\mathbf{k}^n_{\tau + 1}$ 和 $\mathbf{v}^n_{\tau + 1}$ 不仅依赖于 $\tilde{\mathbf{h}}^{n-1}_{\tau - 1}$ 还依赖于之前分割段落的 $\mathbf{h}^{n-1}_{\tau}$ 缓存。
在标准的 Transformer 中,序列的顺序信息通过位置嵌入 $\mathbf{U} \in \mathbb{R}^{L_{\max} \times d}$ 提供,其中第 $i$ 行 $\mathbf{U}_i$ 对应一个分割文本内部的第 $i$ 个绝对位置,$L_{\max}$ 为最大可能长度。在 Transformer-XL 中则是通过一种相对位置信息对其进行编码,构建一个相对位置嵌入 $\mathbf{R} \in \mathbb{R} ^{L_{\max} \times d}$,其中第 $i$ 行 $\mathbf{R}_i$ 表示两个位置之间相对距离为 $i$ 的嵌入表示。
对于一般的 Transformer,一个分割段落内部的 $q_i$ 和 $k_j$ 之间的注意力分数可以分解为:
$$ \begin{aligned} \mathbf{A}_{i, j}^{\mathrm{abs}} &=\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{E}_{x_{j}}}_{(a)}+\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{U}_{j}}_{(b)} \\ &+\underbrace{\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{E}_{x_{j}}}_{(c)}+\underbrace{\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{U}_{j}}_{(d)} \end{aligned} $$
利用相对位置思想,变化如下:
$$ \begin{aligned} \mathbf{A}_{i, j}^{\mathrm{rel}} &=\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k, E} \mathbf{E}_{x_{j}}}_{(a)}+\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k, R} \textcolor{blue}{\mathbf{R}_{i-j}}}_{(b)} \\ &+\underbrace{\textcolor{red}{u^{\top}} \mathbf{W}_{k, E} \mathbf{E}_{x_{j}}}_{(c)}+\underbrace{\textcolor{red}{v^{\top}} \mathbf{W}_{k, R} \textcolor{blue}{\mathbf{R}_{i-j}}}_{(d)} \end{aligned} $$
- 首先,利用相对位置
$\textcolor{blue}{\mathbf{R}_{i-j}}$替代绝对位置嵌入$\mathbf{U}_j$,这里$\mathbf{R}$采用的是无需学习的 sinusoid 编码矩阵 14。 - 其次,引入了一个可训练的参数
$\textcolor{red}{u} \in \mathbb{R}^d$用于替换$\mathbf{U}^{\top}_i \mathbf{W}^{\top}_q$。类似的,对于$\mathbf{U}^{\top} \mathbf{W}^{\top}_q$使用一个可训练的$\textcolor{red}{v} \in \mathbb{R}^d$替换。 - 最后,有意地划分了两个权重矩阵
$\mathbf{W}_{k, E}$和$\mathbf{W}_{k, R}$用于生成基于内容的 Key 向量和基于位置的 Key 向量。
这样,$\left(a\right)$ 代表了基于内容的位置信息,$\left(b\right)$ 捕获了内容无关的位置偏置,$\left(c\right)$ 表示了一个全局的内容偏置,$\left(d\right)$ 捕获了一个全局的位置偏置。
利用一个自注意力头计算 $N$ 层的 Transformer-XL 的过程如下,对于 $n = 1, \dotsc, N$ 有:
$$ \begin{aligned} \widetilde{\mathbf{h}}_{\tau}^{n-1}=&\left[\mathrm{SG}\left(\mathbf{m}_{\tau}^{n-1}\right) \circ \mathbf{h}_{\tau}^{n-1}\right] \\ \mathbf{q}_{\tau}^{n}, \mathbf{k}_{\tau}^{n}, \mathbf{v}_{\tau}^{n}=& \mathbf{h}_{\tau}^{n-1} {\mathbf{W}_{q}^{n}}^{\top}, \widetilde{\mathbf{h}}_{\tau}^{n-1} {\mathbf{W}_{k, E}^{n}}^{\top}, \widetilde{\mathbf{h}}_{\tau}^{n-1} {\mathbf{W}_{v}^{n}}^{\top} \\ \mathbf{A}_{\tau, i, j}^{n}=& {\mathbf{q}_{\tau, i}^{n}}^{\top} \mathbf{k}_{\tau, j}^{n} + {\mathbf{q}_{\tau, i}^{n}}^{\top} \mathbf{W}_{k, R}^{n} \mathbf{R}_{i-j} \\ &+u^{\top} \mathbf{k}_{\tau, j}+v^{\top} \mathbf{W}_{k, R}^{n} \mathbf{R}_{i-j} \\ \mathbf{a}_{\tau}^{n}=& \text { Masked-Softmax }\left(\mathbf{A}_{\tau}^{n}\right) \mathbf{v}_{\tau}^{n} \\ \mathbf{o}_{\tau}^{n}=& \text { LayerNorm } \left(\text{Linear}\left(\mathbf{a}_{\tau}^{n}\right)+\mathbf{h}_{\tau}^{n-1}\right) \\ \mathbf{h}_{\tau}^{n}=& \text { Positionwise-Feed-Forward }\left(\mathbf{o}_{\tau}^{n}\right) \end{aligned} $$
XLNet (2019) 19
给定一个序列 $\mathbf{X} = \left[x_1, \dotsc, x_T\right]$,AR 语言模型通过最大化如下似然进行预训练:
$$ \max_{\theta} \quad \log p_{\theta}(\mathbf{x})=\sum_{t=1}^{T} \log p_{\theta}\left(x_{t} | \mathbf{x}_{<t}\right)=\sum_{t=1}^{T} \log \frac{\exp \left(h_{\theta}\left(\mathbf{x}_{1: t-1}\right)^{\top} e\left(x_{t}\right)\right)}{\sum_{x^{\prime}} \exp \left(h_{\theta}\left(\mathbf{x}_{1: t-1}\right)^{\top} e\left(x^{\prime}\right)\right)} $$
其中,$h_{\theta}\left(\mathbf{x}_{1: t-1}\right)$ 是由 RNNs 或 Transformer 等神经网络网络模型生成的上下文表示,$e \left(x\right)$ 为 $x$ 的嵌入。对于一个文本序列 $\mathbf{x}$,BERT 首先构建了一个遮罩的数据集 $\hat{\mathbf{x}}$,令被遮挡的词条为 $\overline{\mathbf{x}}$,通过训练如下目标来利用 $\hat{\mathbf{x}}$ 重构 $\overline{\mathbf{x}}$:
$$ \max_{\theta} \quad \log p_{\theta}(\overline{\mathbf{x}} | \hat{\mathbf{x}}) \approx \sum_{t=1}^{T} m_{t} \log p_{\theta}\left(x_{t} | \hat{\mathbf{x}}\right)=\sum_{t=1}^{T} m_{t} \log \frac{\exp \left(H_{\theta}(\hat{\mathbf{x}})_{t}^{\top} e\left(x_{t}\right)\right)}{\sum_{x^{\prime}} \exp \left(H_{\theta}(\hat{\mathbf{x}})_{t}^{\top} e\left(x^{\prime}\right)\right)} $$
其中 $m_t = 1$ 表示 $x_t$ 是被遮挡的,$H_{\theta}$ 是一个 Transformer 将一个长度为 $T$ 的文本序列映射到一个隐含向量序列 $H_{\theta}(\mathbf{x})=\left[H_{\theta}(\mathbf{x})_{1}, H_{\theta}(\mathbf{x})_{2}, \cdots, H_{\theta}(\mathbf{x})_{T}\right]$。两种不同的预训练目标的优劣势如下
- 独立假设:BERT 中联合条件概率
$p(\overline{\mathbf{x}} | \hat{\mathbf{x}})$假设在给定的$\hat{\mathbf{x}}$下,遮挡的词条$\overline{\mathbf{x}}$是相关独立的,而 AR 语言模型则没有这样的假设。 - 输入噪声:BERT 在预训练是使用了特殊标记
[MASK],在下游任务微调时不会出现,而 AR 语言模型则不会存在这个问题。 - 上下文依赖:AR 语言模型仅考虑了词条左侧的上下文,而 BERT 则可以捕获两个方向的上下文。
为了利用 AR 语言模型和 BERT 的优点,XLNet 提出了排序语言模型。对于一个长度为 $T$ 序列 $\mathbf{x}$,共有 $T!$ 种不同的方式进行 AR 分解,如果模型共享不同分解顺序的参数,那么模型就能学习到两侧所有位置的信息。令 $\mathcal{Z}_T$ 为长度为 $T$ 的索引序列 $\left[1, 2, \dotsc, T\right]$ 的所有可能排列,$z_t$ 和 $\mathbf{z}_{<t}$ 分别表示一个排列 $\mathbf{z} \in \mathcal{Z}_T$ 第 $t$ 个和前 $t-1$ 个元素。则排列语言模型的优化目标为:
$$ \max_{\theta} \quad \mathbb{E}_{\mathbf{z} \sim \mathcal{Z}_{T}}\left[\sum_{t=1}^{T} \log p_{\theta}\left(x_{z_{t}} | \mathbf{x}_{\mathbf{z}_{<t}}\right)\right] $$
根据标准的 Transformer,下一个词条的分布 $p_{\theta}\left(X_{z_{t}} | \mathbf{x}_{\mathbf{z}<t}\right)$ 为:
$$ p_{\theta}\left(X_{z_{t}} = x | \mathbf{x}_{\mathbf{z}<t}\right)=\frac{\exp \left(e(x)^{\top} h_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}\right)\right)}{\sum_{x^{\prime}} \exp \left(e\left(x^{\prime}\right)^{\top} h_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}\right)\right)} $$
其中,$h_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}\right)$ 表示通过共享的 Transformer 产生的 $\mathbf{X}_{\mathbf{Z}<t}$ 的隐含表示。该表示并不依赖于所预测的位置,为了避免这个问题,我们将位置 $z_t$ 加入到模型中:
$$ p_{\theta}\left(X_{z_{t}}=x | \mathbf{x}_{z_{<t}}\right)=\frac{\exp \left(e(x)^{\top} g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right)\right)}{\sum_{x^{\prime}} \exp \left(e\left(x^{\prime}\right)^{\top} g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right)\right)} $$
对于 $g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right)$ 进行建模需要满足如下两个要求:
- 预测
$x_{z_t}$时,$g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right)$只能使用位置信息$z_t$而不能使用内容信息$x_{z_t}$。 - 在预测
$x_{z_t}$之后的词条时,$g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right)$又必须包含$x_{z_t}$的语义信息。
为了解决这个问题,XLNet 提供了两种隐含表示:
- 内容隐含表示
$h_{\theta}\left(\mathbf{x}_{\mathbf{z} \leq t}\right)$,简写为$h_{z_t}$,它和标准的 Transformer 一样,既编码上下文也编码$x_{z_t}$的内容。 - 查询隐含表示
$g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right)$,简写为$g_{z_t}$,它仅编码上下文信息$\mathbf{X}_{\mathbf{Z}<t}$和位置信息$z_t$,不编码内容$x_{z_t}$。
模型的整个计算过程如下图所示:
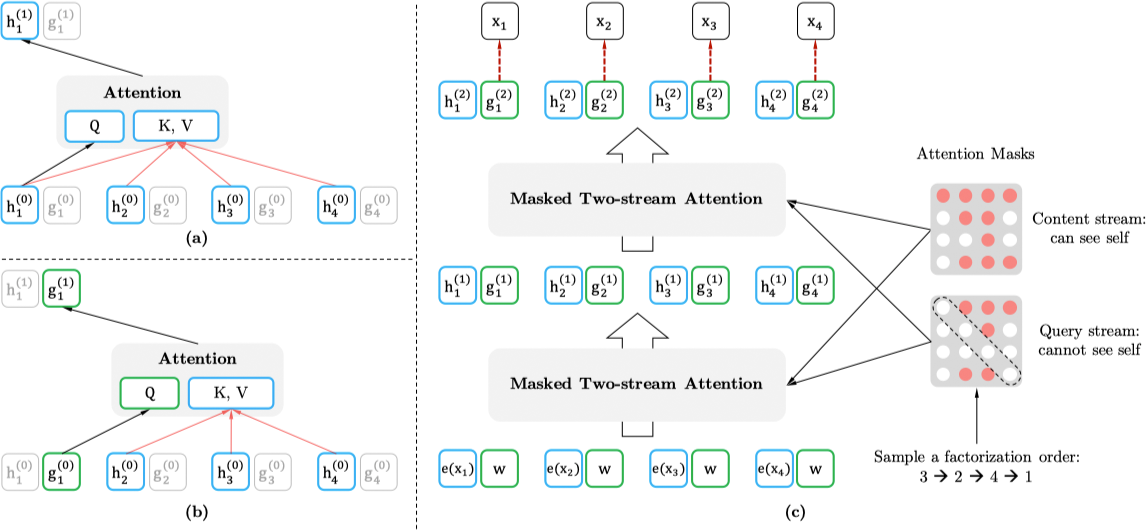
虽然排列语言模型有很多优点,但是由于计算量很大,模型很难进行优化,因此我们通过仅预测一个句子后面的一些词条解决这个问题。将 $\mathbf{z}$ 分为两部分:非目标子序列 $\mathbf{z}_{\leq c}$ 和目标子序列 $\mathbf{z}_{>c}$,其中 $c$ 为切分点。同时会设置一个超参数 $K$,表示仅 $1 / K$ 的词条会被预测,有 $|\mathbf{z}| /(|\mathbf{z}|-c) \approx K$。对于未被选择的词条,其查询隐状态无需被计算,从而节省计算时间和资源。
MASS (2019) 16
MASS 是一个专门针对序列到序列的自然语言任务设计的预训练方法,对于一个给定的原始句子 $x \in \mathcal{X}$,令 $x^{\setminus u:v}$ 表示将 $x$ 从 $u$ 到 $v$ 位置进行遮挡处理,$k = v - u + 1$ 为被遮挡词条的个数,$x^{u:v}$ 为从 $u$ 到 $v$ 位置被遮挡的部分。MASS 利用被遮挡的序列 $x^{\setminus u:v}$ 预测被遮挡的部分 $x^{u:v}$,目标函数的对数似然如下:
$$ \begin{aligned} L(\theta ; \mathcal{X}) &=\frac{1}{|\mathcal{X}|} \Sigma_{x \in \mathcal{X}} \log P\left(x^{u: v} | x^{\setminus u: v} ; \theta\right) \\ &=\frac{1}{|\mathcal{X}|} \Sigma_{x \in \mathcal{X}} \log \prod_{t=u}^{v} P\left(x_{t}^{u: v} | x_{<t}^{u: v}, x^{\setminus u: v} ; \theta\right) \end{aligned} $$
对于一个具有 8 个词条的序列,$x_3 x_4 x_5 x_6$ 被遮挡的示例如下:

模型仅预测遮挡的部分 $x_3 x_4 x_5 x_6$,对于解码器中位置 $4-6$ 利用 $x_3 x_4 x_5$ 作为输入,利用特殊遮挡符号 $\left[\mathbb{M}\right]$ 作为其他位置的输入。对于不同长度 $k$,MASS 包含了上文中提到的两种预训练模型:
| 长度 | 概率 | 模型 |
|---|---|---|
$k=1$ |
$P\left(x^{u} \mid x^{\setminus u} ; \theta\right)$ |
masked LM in BERT |
$k=m$ |
$P\left(x^{1:m} \mid x^{\setminus 1:m} ; \theta\right)$ |
masked LM in GPT |
$k \in \left(1, m\right)$ |
$P\left(x^{u:v} \mid x^{\setminus u:v} ; \theta\right)$ |
两种之间 |
对于不同 $k$ 值,实验发现当 $k$ 处于 $m$ 的 $50\%$ 至 $70\%$ 之间时下游任务性能最优。
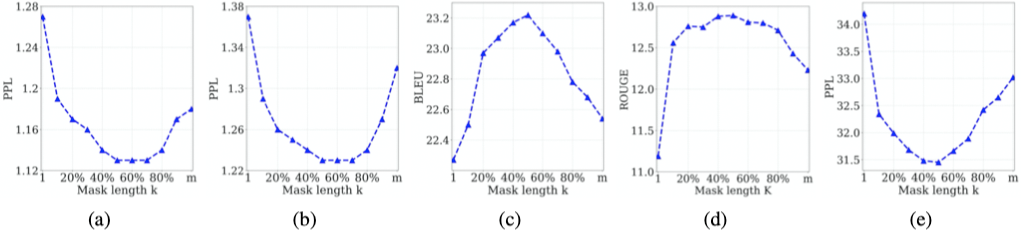
当 $k = 0.5 m$ 时,MASS 可以很好地平衡编码器和解码器的预训练。过度地偏向编码器($k=1$,masked LM in BERT)和过度地偏向解码器($k=m$,masked LM in GPT)均不能在下游的自然语言生成任务中取得很好的效果。
RoBERTa (2019) 18
RoBERTa 主要围绕 BERT 进行了如下改进:
- 模型采用了动态遮罩,不同于原始 BERT 中对语料预先进行遮罩处理,RoBERTa 在 40 轮训练过程中采用了 10 种不同的遮罩。
- 模型去掉了 NSP 任务,发现可以略微提升下游任务的性能。
- 模型采用了更大的训练数据和更大的 Batch 大小。
- 原始 BERT 采用一个 30K 的 BPE 词表,RoBERTa 采用了一个更大的 50K 的词表 28。
BART (2019) 20
BART 采用了一个标准的 Seq2Seq Transformer 结构,类似 GPT 将 ReLU 激活函数替换为 GeLUs。对于基线模型,采用了一个 6 层的编码和解码器,对于更大模型采用了 12 层的结构。相比于 BERT 的架构主要有以下两点不同:
- 解码器的每一层叠加了对编码器最后一个隐含层的注意力。
- BERT 在预测之前采用了一个前馈的网络,而 BART 没有。
BART 采用了最小化破坏后的文档和原始文档之间的重构误差的方式进行预训练。不同于其他的一些去噪自编码器,BART 可以使用任意类型的文档破坏方式。极端情况下,当源文档的所有信息均丢失时,BART 就等价与一个语言模型。BART 中采用的文本破坏方式有:字符遮罩,字符删除,文本填充,句子重排,文档旋转,如下图所示:
T5 (2019) 17
T5(Text-to-Text Transfer Transformer) 提出了一种 text-to-text 的框架,旨在利用相同的模型,损失函数和超参数等对机器翻译,文档摘要,问答和分类(例如:情感分析)等任务进行统一建模。我们甚至可以利用 T5 通过预测一个数字的文本表示而不是数字本身来建模一个回归任务。模型及其输入输出如下图所示:

Google 的这项研究并不是提出一种新的方法,而是从全面的视角来概述当前 NLP 领域迁移学习的发展现状。T5 还公开了一个名为 C4(Colossal Clean Crawled Corpus)的数据集,该数据集是一个比 Wikipedia 大两个数量级的 Common Crawl 的清洗后版本的数据。更多模型的细节请参见源论文和 Google 的 官方博客。
ERNIE (Baidu, 2019) 29 30
ERNIE 1.0 29 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。例如:
BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。
ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
在 BERT 模型中,我们通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的任何知识。而 ERNIE 通过学习词与实体的表达,使模型能够建模出『哈尔滨』与『黑龙江』的关系,学到『哈尔滨』是 『黑龙江』的省会以及『哈尔滨』是个冰雪城市。
训练数据方面,除百科类、资讯类中文语料外,ERNIE 还引入了论坛对话类数据,利用 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,进一步提升模型的语义表示能力。
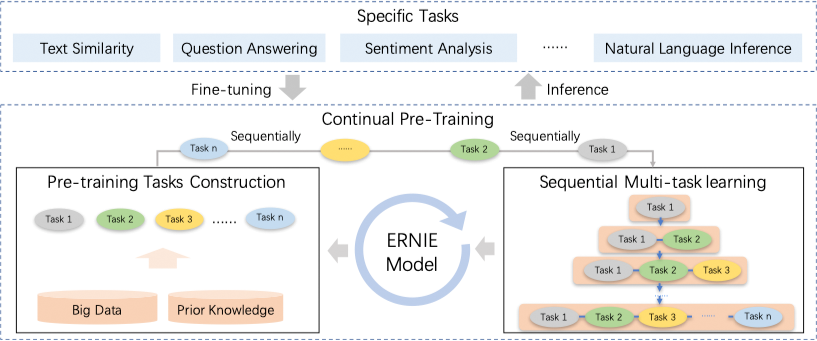
ERNIE 2.0 30 是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务。ERNIE 2.0 中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。 通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0 语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。
State-of-Art
NLP 任务的 State-of-Art 模型详见:
-
Qiu, X., Sun, T., Xu, Y., Shao, Y., Dai, N., & Huang, X. (2020). Pre-trained Models for Natural Language Processing: A Survey. ArXiv:2003.08271 [Cs]. http://arxiv.org/abs/2003.08271 ↩︎
-
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119). ↩︎
-
Pennington, J., Socher, R., & Manning, C. D. (2014, October). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543). ↩︎
-
McCann, B., Bradbury, J., Xiong, C., & Socher, R. (2017). Learned in translation: Contextualized word vectors. In Advances in Neural Information Processing Systems (pp. 6294-6305). ↩︎ ↩︎
-
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. arXiv preprint arXiv:1802.05365. ↩︎ ↩︎
-
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. URL https://openai.com/blog/language-unsupervised/. ↩︎ ↩︎
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. ↩︎ ↩︎
-
Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 1746-1751). ↩︎
-
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780. ↩︎
-
Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555. ↩︎
-
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A. Y., & Potts, C. (2013). Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing (pp. 1631-1642). ↩︎
-
Tai, K. S., Socher, R., & Manning, C. D. (2015). Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (pp. 1556-1566). ↩︎
-
Marcheggiani, D., Bastings, J., & Titov, I. (2018). Exploiting Semantics in Neural Machine Translation with Graph Convolutional Networks. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) (pp. 486-492). ↩︎
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008). ↩︎ ↩︎ ↩︎
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 4171-4186). ↩︎
-
Song, K., Tan, X., Qin, T., Lu, J., & Liu, T. Y. (2019). MASS: Masked Sequence to Sequence Pre-training for Language Generation. In International Conference on Machine Learning (pp. 5926-5936). ↩︎ ↩︎
-
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.1068 ↩︎ ↩︎
-
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692. ↩︎ ↩︎
-
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R. R., & Le, Q. V. (2019). Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems (pp. 5754-5764). ↩︎ ↩︎
-
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., … & Zettlemoyer, L. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461. ↩︎ ↩︎
-
Saunshi, N., Plevrakis, O., Arora, S., Khodak, M., & Khandeparkar, H. (2019). A Theoretical Analysis of Contrastive Unsupervised Representation Learning. In International Conference on Machine Learning (pp. 5628-5637). ↩︎
-
Tenney, I., Das, D., & Pavlick, E. (2019). BERT Rediscovers the Classical NLP Pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 4593-4601). ↩︎
-
图片来源:http://www.realworldnlpbook.com/blog/improving-sentiment-analyzer-using-elmo.html ↩︎
-
Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., … & Klingner, J. (2016). Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144. ↩︎
-
Dong, L., Yang, N., Wang, W., Wei, F., Liu, X., Wang, Y., … & Hon, H. W. (2019). Unified language model pre-training for natural language understanding and generation. In Advances in Neural Information Processing Systems (pp. 13042-13054). ↩︎
-
Dai, Z., Yang, Z., Yang, Y., Carbonell, J. G., Le, Q., & Salakhutdinov, R. (2019, July). Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 2978-2988). ↩︎
-
Al-Rfou, R., Choe, D., Constant, N., Guo, M., & Jones, L. (2019). Character-level language modeling with deeper self-attention. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, pp. 3159-3166). ↩︎
-
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. URL https://openai.com/blog/better-language-models/. ↩︎
-
Sun, Y., Wang, S., Li, Y., Feng, S., Chen, X., Zhang, H., … & Wu, H. (2019). Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223. ↩︎ ↩︎
-
Sun, Y., Wang, S., Li, Y., Feng, S., Tian, H., Wu, H., & Wang, H. (2019). Ernie 2.0: A continual pre-training framework for language understanding. arXiv preprint arXiv:1907.12412. ↩︎ ↩︎