在日常工作中,数据处理和分析在研发、产品和运营等多个领域起着重要的作用。在海量数据处理和分析中,SQL 是一项基础且重要的能力。一个优秀的 SQL Boy 和茶树姑的 SQL 代码除了保持简单、可读和易于维护的样式风格外,还需要具备良好的执行性能,准确且高效的计算出结果才能让你在工作中决胜于千里之外。
影响 SQL 执行性能的主要因素可以总结为如下几项:
- 计算资源量(CPU,内存,网络等)
- 计算数据量(输入和输出的记录数)
- 计算复杂度(业务逻辑复杂程度和对应的 SQL 实现和执行)
计算资源量是一个前置制约因素,理论上更多的资源能够带来更快的计算效果。计算数据量也可以认为是一个前置制约因素,理论上更大的数据量会导致计算速度降低,但对于复杂的计算逻辑,通过合理的 SQL 可以更好的控制计算过程中的数据量,从而提升 SQL 性能。计算复杂度是影响 SQL 性能的关键因素,复杂的业务逻辑必然比简单的业务逻辑处理时间要长,相同业务逻辑的不同 SQL 实现也会影响运行效率,这就要求我们对业务逻辑进行全面的理解,对实现 SQL 进行合理优化,从而提升计算速度。
执行引擎
SQL 是用于一种用于数据定义和数据操纵的特定目的的编程语言 1。SQL 虽然有 ISO 标准 2,但大部分 SQL 代码在不同的数据库系统中并不具有完全的跨平台性。不同的执行引擎也会对 SQL 的语法有相应的改动和扩展,同时对于 SQL 的执行也会进行不同的适配和优化。因此,脱离执行引擎的 SQL 性能优化是不可取的。
Hive
Apache Hive 是一个建立在 Hadoop 架构之上的数据仓库。可以将结构化的数据文件映射为一张数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行。因此 MapReduce 是 Hive SQL 运行的核心和根基。
我们以 Word Count 为例简单介绍一下 MapReduce 的原理和过程,Word Count 的 MapReduce 处理过程如下图所示:

- Input:程序的输入数据。
- Splitting:讲输入数据分割为若干部分。
- Mapping:针对 Splitting 分割的每个部分,对应有一个 Map 程序处理。本例中将分割后的文本统计成
<K,V>格式,其中K为单词,V为该单词在这个 Map 中出现的次数。 - Shuffling:对 Mapping 的相关输出结果进行合并。本例中将具有相同
K的统计结果合并到一起。 - Reducing:对 Shuffling 合并的结果进行汇总。本例中讲相同
K的V值进行加和操作并返回单个统计结果。 - Merged:对 Reducing 的结果进行融合形成最终输出。
Spark
Apache Spark 是一个用于大规模数据处理的统一分析引擎,Spark SQL 则作为 Apache Spark 用于处理结构化数据的模块。
Spark 中常见的概念有:
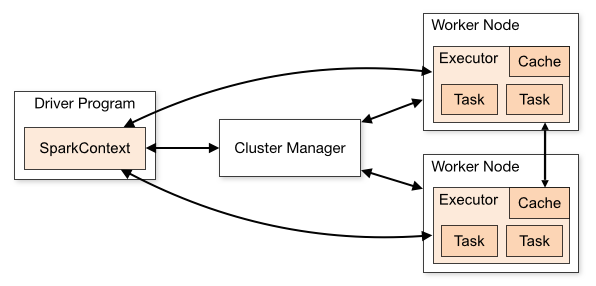
- RDD:Resilient Distributed Dataset,弹性分布式数据集,是分布式内存中一个抽象概念,提供了一种高度受限的共享内存模型。
- DAG:Directed Acyclic Graph,有向无环图,反应了 RDD 之间的依赖关系。
- Driver Program:控制程序,负责为 Application 创建 DAG,通常用
SparkContext代表 Driver Program。 - Cluster Manager:集群管理器,负责分配计算资源。
- Worker Node:工作节点,负责具体计算。
- Executor:运行在 Worker Node 上的一个进程,负责运行 Task,并为 Application 存储数据。
- Application:Spark 应用程序,包含多个 Executor。
- Task:任务,运行在 Executor 上的工作单元,是 Executor 中的一个线程。
- Stage:一组并行的 Task,Spark 一般会根据 Shuffle 类算子(例如:
reduceByKey或join等)划分 Stage。 - Job:一组 Stage 的集合,一个 Job 包含多个 RDD 及作用于 RDD 上的操作。
相关概念构成了 Spark 的整体架构,如下图所示:
在 Spark 中,一个任务的执行过程大致分为 4 个阶段,如下图所示:
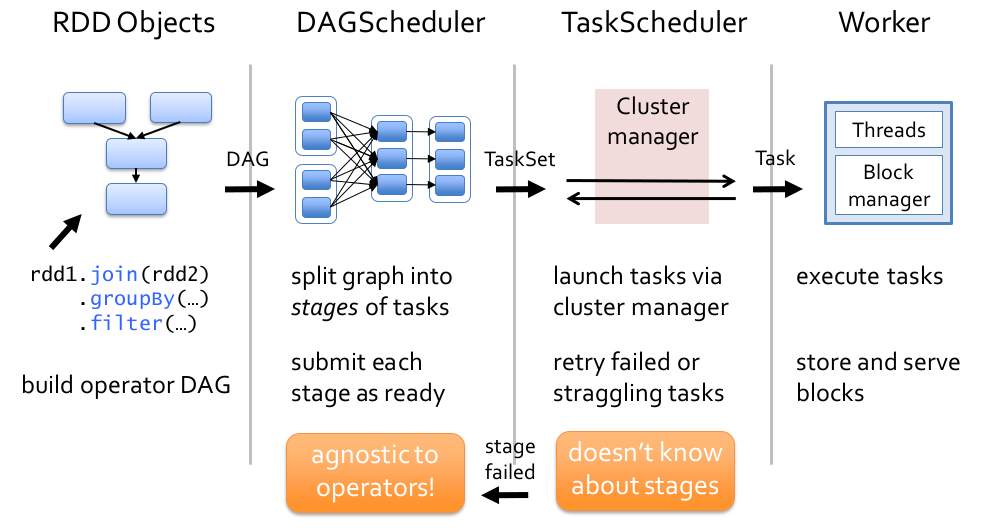
- 定义 RDD 的 Transformations 和 Actions 算子 3,并根据这些算子形成 DAG。
- 根据形成的 DAG,DAGScheduler 将其划分为多个 Stage,每个 Stage 包含多个 Task。
- DAGScheduler 将 TaskSet 交由 TaskScheduler 运行,并将执行完毕后的结果返回给 DAGScheduler。
- TaskScheduler 将任务分发到每一个 Worker 去执行,并将执行完毕后的结果返回给 TaskScheduler。
Spark 相比于 Hadoop 的主要改进有如下几点:
- Hadoop 的 MapReduce 的中间结果都会持久化到磁盘上,而 Spark 则采用基于内存的计算(内存不足时也可选持久化到磁盘上),从而减少 Shuffle 数据,进而提升计算速度。
- Spark 采用的 DAG 相比于 Hadoop 的 MapReduce 具有更好的容错性和可恢复性,由于 Spark 预先计算出了整个任务的 DAG,相比于 MapReduce 中各个操作之间是独立的,这更有助于进行全局优化。
Presto
Presto 是一种用于大数据的高性能分布式 SQL 查询引擎。Presto 与 Hive 执行任务过程的差异如下图所示:
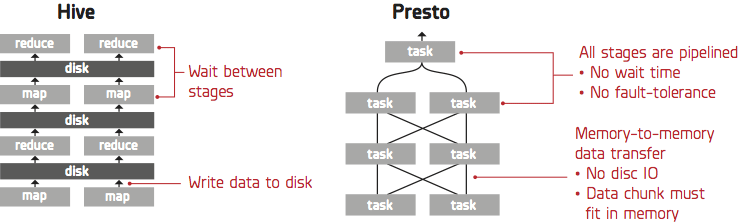
Presto 的优点主要有如下几点:
- 基于内存计算,减少了磁盘 IO,从而计算速度更快。
- 能够连接多个数据源,跨数据源连表查询。
虽然 Presto 能够处理 PB 级数据,但并不代表 Presto 会把 PB 级别数据都放在内存中计算。而是根据场景,例如 COUNT 和 AVG 等聚合操作,是边读数据边计算,再清理内存,再读取数据计算,这种情况消耗的内存并不高。但是连表查询,可能产生大量的临时数据,从而速度会变慢。
性能调优
本节关于 SQL 性能调优的建议主要针对 Hive,Spark 和 Presto 这类大数据 OLAP 执行引擎设计,其他执行引擎不一定完全适用。
下文性能调优中均以如下两张表为例进行说明:
CREATE TABLE IF NOT EXISTS sku_order
(
order_id STRING '订单 ID',
sku_id STRING '商品 ID',
sale_quantity BIGINT '销售数量'
)
COMMENT '商品订单表'
PARTITIONED BY
(
dt STRING COMMENT '日期分区'
)
;
CREATE TABLE IF NOT EXISTS sku_info
(
sku_id STRING '商品 ID',
sku_name STRING '商品名称',
category_id STRING '品类 ID',
category_name STRING '品类名称'
)
COMMENT '商品信息表'
减少数据量
- 限定查询分区。对于包含分区的数据表(例如:日期分区),通过合理限定分区来减少数据量,避免全表扫描。
- 限定查询字段。避免使用
SELECT *,仅选择需要的字段。SELECT *会通过查询元数据获取字段信息,同时查询所有字段会造成更大的网络开销。 - 在关联前过滤数据。应在进行数据表关联之前按照业务逻辑进行数据过滤,从而提升执行效率。
数据倾斜
在 Shuffle 阶段,需要将各节点上相同的 Key 拉取到某个节点(Task)上处理,如果某个 Key 对应的数据量特别大则会产生数据倾斜。结果就是该 Task 运行的时间要远远大于其他 Task 的运行时间,从而造成作业整体运行缓慢,数据量过大甚至可能导致某个 Task 出现 OOM。
在 SQL 中主要有如下几种情况会产生数据倾斜:
JOIN导致的数据倾斜:两表关联,关联字段的无效值(例如:NULL)或有效值过多,可能会导致数据倾斜。GROUP BY导致的数据倾斜:当GROUP BY的字段(或字段组合)中,Key 分布不均,可能会导致数据倾斜。DISTINCT导致的数据倾斜:当DISTINCT的字段(或字段组合)中,Key 分布不均,可能会导致数据倾斜。
对于不同的数据倾斜情况,解决方案如下:
-
对于
JOIN中的无效值进行过滤。SELECT category_name, SUM(sale_quantity) AS sale_quantity FROM ( SELECT sku_id, sale_quantity FROM sku_order WHERE dt = '20210523' AND sku_id IS NOT NULL ) AS sku_order_filtered LEFT JOIN sku_info ON sku_order_filtered.sku_id = sku_info.sku_id GROUP BY category_name ; -
对于
JOIN开启 Map Join 或 Broadcast Join 策略,将小表广播到每个 Executor 上来避免产生 Shuffle,从而使得JOIN能够快速完成。
set spark.sql.autoBroadcastJoinThreshold=10485760;
-
对于
JOIN中存在数据倾斜的 KEY 进行打散处理。SELECT category_name, SUM(sale_quantity) AS sale_quantity FROM ( SELECT IF(sku_id IN (0000, 9999), CONCAT(sku_id, '_', CEIL(RAND() * 10)), sku_id) AS sku_id, sale_quantity FROM sku_order WHERE dt = '20210523' ) AS sku_order_modified LEFT JOIN ( SELECT sku_id, category_name, FROM sku_info WHERE sku_id NOT IN (0000, 9999) UNION ALL SELECT CONCAT(sku_id, '_', suffix) AS sku_id, category_name FROM ( SELECT sku_id, SPLIT('1,2,3,4,5,6,7,8,9,10', ',') AS suffix_list, category_name FROM sku_info WHERE sku_id IN (0000, 9999) ) sku_info_tmp LATERAL VIEW EXPLODE(suffix_list) sku_info_suffix AS suffix ) sku_info_all ON sku_order_modified.sku_id = sku_info_all.sku_id GROUP BY category_name ; -
对于
GROUP BY导致的数据倾斜采用两步聚合。SELECT IF(sku_is_null = 1, NULL, sku_id) AS sku_id, SUM(sale_quantity) AS sale_quantity FROM ( SELECT sku_id, sku_is_null, SUM(sale_quantity) AS sale_quantity FROM ( SELECT IF(sku_id IS NULL, CONCAT(sku_id, CEIL(RAND() * 10)), sku_id) AS sku_id, IF(sku_id IS NULL, 1, 0) AS sku_is_null, sale_quantity FROM sku_order WHERE dt = '20210523' ) sku_order_modified GROUP BY sku_id, sku_is_null ) sku_order_group GROUP BY IF(sku_is_null = 1, NULL, sku_id) ; -
对于
DISTINCT导致的数据倾斜,可以改写为GROUP BY实现,从而通过多个 Task 计算避免数据倾斜。/* COUNT DISTINCT */ SELECT COUNT(DISTINCT sku_id) AS cnt FROM sku_order WHERE dt = '20210523' ; /* GROUP BY */ SELECT COUNT(1) AS cnt FROM ( SELECT sku_id FROM sku_order WHERE dt = '20210523' GROUP BY sku_id ) AS sku_stats ;
其他建议
-
使用 Common Table Expressions (CTEs) 而非子查询。
WITH语句产生的结果类似临时表,可以重复使用,从而避免相同逻辑业务重复计算。 -
使用
LEFT SEMI JOIN而非IN和子查询。Hive 在 0.13 后的版本中才在IN和NOT IN中支持子查询。/* BAD */ SELECT order_id, sku_id, sale_quantity FROM sku_order WHERE sku_id IN (SELECT sku_id FROM sku_info) ; /* GOOD */ SELECT order_id, sku_id, sale_quantity FROM sku_order LEFT SEMI JOIN sku_info ON sku_order.sku_id = sku_info.sku_id ;
参数调优
除了 SQL 本身逻辑的优化外,执行引擎的相关参数设置也会影响 SQL 的执行性能。本小节以 Spark 引擎为例,总结相关参数的设置及其影响。
动态分区
/* 以下 Hive 参数对 Spark 同样有效 */
/* 是否启用动态分区功能 */
set hive.exec.dynamic.partition=true;
/* strict 表示至少需要指定一个分区,nonstrict 表示可以全部动态指定分区 */
set hive.exec.dynamic.partition.mode=nonstrict;
/* 动态生成分区的最大数量 */
set hive.exec.max.dynamic.partitions=1000;
资源申请
/* 每个 Executor 中的核数 */
set spark.executor.cores=2;
/* Executor 的内存总量。YARN 中 Container 的内存限制为 spark.executor.memory + spark.yarn.executor.memoryOverhead <= 16G。 */
set spark.executor.memory=4G;
/* Executor 的堆外内存大小,由 YARN 控制,单位为 MB。YARN 中 Container 的内存限制为 spark.executor.memory + spark.yarn.executor.memoryOverhead <= 16G。 */
set spark.yarn.executor.memoryOverhead=1024;
/* Driver 的内存总量,主要用于存放任务执行过程中 Shuffle 元数据,以及任务中 Collect 的数据,Broadcast 的小表也会先存放在 Driver 中。YARN 中 Container 的内存限制为 spark.executor.memory + spark.yarn.executor.memoryOverhead <= 16G。 */
set spark.driver.memory=8G;
/* Driver 的堆外内存,由 YARN 控制,单位为 MB。YARN 中 Container 的内存限制为 spark.executor.memory + spark.yarn.executor.memoryOverhead <= 16G。 */
set spark.yarn.driver.memoryOverhead=1024;
/* storage memory + execution memory 占总内存(java heap-reserved memory)的比例。executor jvm 中内存分为 storage、execution 和 other 内存。storage 存放缓存 RDD 数据,execution 存放 Shuffle 过程的中间数据,other 存放用户定义的数据结构或 Spark 内部元数据。如果用户自定义数据结构较少,可以将该参数比例适当上调。 */
set spark.memory.fraction=0.7;
动态分配
开启动态分配,Spark 可以根据当前作业负载动态申请和释放资源:
set spark.dynamicAllocation.enabled=true;
同时需要设置同一时刻可以申请的最小和最大 Executor 数量:
set spark.dynamicAllocation.minExecutors=10;
set spark.dynamicAllocation.maxExecutors=100;
小文件合并
/* 小文件合并阈值,如果生成的文件平均大小低于阈值会额外启动一轮 Stage 进行小文件的合并,默认不合并小文件。 */
set spark.sql.mergeSmallFileSize=67108864;
/* 设置额外的合并 Job 时的 Map 端输入大小 */
set spark.sql.targetBytesInPartitionWhenMerge=67108864;
/* 设置 Map 端输入的合并文件大小 */
set spark.hadoopRDD.targetBytesInPartition=67108864;
在决定一个目录是否需要合并小文件时,会统计目录下的平均大小,然后和 spark.sql.mergeSmallFileSize 比较。在合并文件时,一个 Map Task 读取的数据量取决于下面三者的较大值:spark.sql.mergeSmallFileSize,spark.sql.targetBytesInPartitionWhenMerge,spark.hadoopRDD.targetBytesInPartition。
Shuffle 相关
当大表 JOIN 小表时,如果小表足够小,可以将小表广播到所有 Executor 中,在 Map 阶段完成 JOIN。如果该值设置太大,容易导致 Executor 出现 OOM。
/* 10 * 1024 * 1024, 10MB */
set spark.sql.autoBroadcastJoinThreshold=10485760;
设置 Reduce 阶段的分区数:
set spark.sql.shuffle.partitions=1000;
设置过大可能导致很多 Reducer 同时向一个 Mapper 拉取数据,导致 Mapper 由于请求压力过大而挂掉或响应缓慢,从而 fetch failed。
一些其他 Shuffle 相关的配置如下:
/* 同一时刻一个 Reducer 可以同时拉取的数据量大小 */
set spark.reducer.maxSizeInFlight=25165824;
/* 同一时刻一个 Reducer 可以同时产生的请求数 */
set spark.reducer.maxReqsInFlight=10;
/* 同一时刻一个 Reducer 向同一个上游 Executor 拉取的最多 Block 数 */
set spark.reducer.maxBlocksInFlightPerAddress=1;
/* Shufle 请求的 Block 超过该阈值就会强制落盘,防止一大堆并发请求将内存占满 */
set spark.reducer.maxReqSizeShuffleToMem=536870911;
/* Shuffle 中连接超时时间,超过该时间会 fetch failed */
set spark.shuffle.io.connectionTimeout=120;
/* Shuffle 中拉取数据的最大重试次数 */
set spark.shuffle.io.maxRetries=3;
/* Shuffle 重试的等待间隔 */
set spark.shuffle.io.retryWait=5;
ORC 相关
ORC 文件的格式如下图所示:
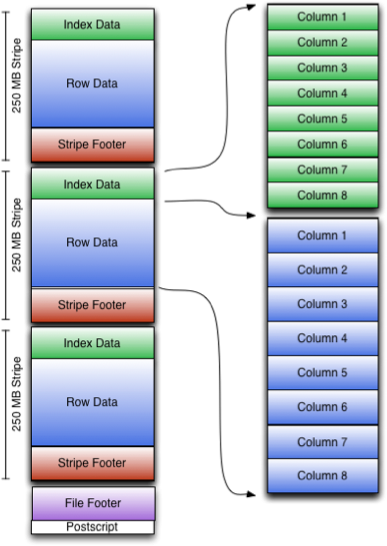
其中,Postscript 为文件描述信息,包括 File Footer 和元数据长度、文件版本、压缩格式等;File Footer 是文件的元数据信息,包括数据量、每列的统计信息等;文件中的数据为 Stripe,每个 Stripe 包括索引数据、行数据和 Stripe Footer。更多有关 ORC 文件格式的信息请参见 ORC Specification v1 。
在读取 ORC 压缩表时,可以控制生成 Split 的策略,包括:
- BI:以文件为力度进行 Split 划分
- ETL:将文件进行切分,多个 Stripe 组成一个 Split
- HYBRID:当文件的平均大小大于 Hadoop 最大 Split 值时使用 ETL 策略,否则使用 BI 策略
对于一些较大的 ORC 表,可能其 Footer 较大,ETL 策略可能会导致从 HDFS 拉取大量的数据来切分 Split,甚至会导致 Driver 端 OOM,因此这类表的读取建议采用 BI 策略。对于一些较小,尤其是有数据倾斜的表(即大量 Stripe 存储于少数文件中),建议使用 ETL 策略。
一些其他 ORC 相关的配置如下:
/* ORC 谓词下推,默认是关闭 */
set spark.sql.orc.filterPushdown=true;
/* 开启后,在 Split 划分时会使用 Footer 信息 */
set spark.sql.orc.splits.include.file.footer=true;
/* 设置每个 Stripe 可以缓存的大小 */
set spark.sql.orc.cache.stripe.details.size=10000;
/* 当为 true 时,Spark SQL 的谓语将被下推到 Hive Metastore 中,更早的消除不匹配的分区。 */
set spark.sql.hive.metastorePartitionPruning=true;
/* 读 ORC 表时,设置小文件合并的阈值,低于该值的 Split 会合并在一个 Task 中执行 */
set spark.hadoop.mapreduce.input.fileinputformat.split.minsize=67108864;
/* 读 ORC 表时,设置一个 Split 的最大阈值,大于该值的 Split 会切分成多个 Split。 */
set spark.hadoop.mapreduce.input.fileinputformat.split.maxsize=268435456;
/* 文件提交到HDFS上的算法:1. version=1 是按照文件提交。2. version=2 是批量按照目录进行提交,可以极大节约文件提交到 HDFS 的时间,减轻 NameNode 压力。 */
set spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=2;
自适应执行
/* 开启动态执行 */
set spark.sql.adaptive.enabled=true;
当自适应执行开启后,调整 spark.sql.adaptive.shuffle.targetPostShuffleInputSize,当 Mapper 端两个 Partition 的数据合并后小于该值时,Spark 会将两个 Partition 合并到一个 Reducer 进行处理。
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize=67108864;
当自适应执行开启后,有时会导致过多分区被合并,为了防止分区过少影响性能,可以设置如下参数:
set spark.sql.adaptive.minNumPostShufflePartitions=10;
一些其他自适应执行相关的配置如下:
/* 开启动态调整 Join */
set spark.sql.adaptive.join.enabled=true;
/* 设置 SortMergeJoin 转 BroadcastJoin 的阈值,如果不设置该参数,该阈值和 spark.sql.autoBroadcastJoinThreshold 值相等。 */
set spark.sql.adaptiveBroadcastJoinThreshold=33554432;
/* 是否允许为了优化 Join 而增加 Shuffle,默认是 false */
set spark.sql.adaptive.allowAddititionalShuffle=false;
/* 开启自动处理 Join 时的数据倾斜 */
set spark.sql.adaptive.skewedJoin.enabled=true;
/* 控制处理一个倾斜 Partition 的 Task 个数上限,默认值是 5 */
set spark.sql.adaptive.skewedPartitionMaxSplits=100;
/* 设置一个 Partition 被视为倾斜 Partition 的行数下限,行数低于该值的 Partition 不会被当做倾斜 Partition 处理。 */
set spark.sql.adaptive.skewedPartitionRowCountThreshold=10000000;
/* 设置一个 Partition 被视为倾斜 Partition 的大小下限,大小小于该值的 Partition 不会被当做倾斜 Partition 处理。 */
set spark.sql.adaptive.skewedPartitionSizeThreshold=536870912;
/* 设置倾斜因子,当一个 Partition 满足以下两个条件之一,就会被视为倾斜 Partition:1. 大小大于 spark.sql.adaptive.skewedPartitionSizeThreshold 的同时大于各 Partition 大小中位数与该因子的乘积。2. 行数大于 spark.sql.adaptive.skewedRowCountThreshold 的同时大于各 Partition 行数中位数与该因子的乘积。*/
set spark.sql.adaptive.skewedPartitionFactor=10;
推测执行
/* Spark 推测执行开关,默认是 true */
set spark.speculation=true;
/* 开启推测执行后,每隔该值时间会检测是否有需要推测执行的 Task */
set spark.speculation.interval=1000ms;
/* 当成功 Task 占总 Task 的比例超过 spark.speculation.quantile,统计成功 Task 运行时间中位数乘以 spark.speculation.multiplier 得到推测执行阈值,当在运行的任务超过这个阈值就会启动推测执行。当资源充足时,可以适当减小这两个值。 */
set spark.speculation.quantile=0.99;
set spark.speculation.multiplier=3;