文学编程
文学式编程(Literate Programming)是由高德纳提出的编程方法,希望能用来取代结构化编程范型。正如高德纳所构想的那样,文学编程范型不同于传统的由计算机强加的编写程序的方式和顺序,而代之以让程序员用他们自己思维内在的逻辑和流程所要求的顺序开发程序。文学编程自由地表达逻辑,而且它用人类日常使用的语言写出来,就好像一篇文章一样,文章里包括用来隐藏抽象的巨集和传统的源代码。文学编程工具用来从文学源文件中获得两种表达方式,一种用于计算机进一步的编译和执行,称作“绕出”(tangled)的代码,一种用于格式化文档,称作从文学源代码中“织出”(woven)。虽然第一代文学编程工具特定于计算机语言,但后来的工具可以不依赖具体语言,并且存在于比编程语言更高的层次中 1。
如高德纳在论文 2 中所示,相同的源文件经过“tangle”可以编译为机器代码,经过“weave”可以编译为文档。
文学编程历史
从高德纳提出文学编程的概念后,各家各派都在将这个编程范式付诸实践。我接触文学编程已经比较晚了,算是从 R Markdown 和 knitr 开始,开始时写写分析报告和做做幻灯片,慢慢的在更多场景我发现这很适合。
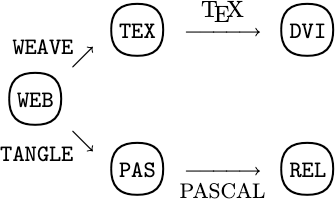
WEB, CWEB & noweb
WEB 是一种计算机编程语言系统,它由高德纳设计,是第一种实现他称作“文学编程”的语言。WEB 包含了 2 个主要程序:TANGLE,从源文本生成可编译的 Pascal 代码,以及 WEAVE,使用 TeX 生成格式漂亮可打印的文档。CWEB 是 WEB 的 C 语言新版本,noweb 是另外一种借鉴了 WEB 的文学编程工具,同时与语言无关 3。
以 wc.nw 为例,其为 Unix 单词统计程序 wc 的 noweb 版本重写,原始的 CWEB 版本可以在高德纳的《文学编程》一书中找到。noweb 源代码中包含 TeX 代码和 C 语言代码,每个 C 语言代码片段都以一个 <<代码片段名称>>= 开头,以 @ 结尾,程序的入口为 <<*>>=。在某个代码片段中调用其他代码片段只需要输入 <<代码片段名称>> 即可。
安装 noweb,通过如下命令可以将 wc.nw 编译为 C 语言代码 wc.c:
notangle -L wc.nw > wc.c
通过如下命令可以将 wc.nw 编译为 TeX 源代码:
noweave -autodefs c -index wc.nw > wc.tex
Org Mode
Org Mode 是由 Carsten Dominik 于 2003 年发明的用于文本编辑器 Emacs 的一种支持内容分级显示的编辑模式。这种模式下可以创建待办列表,日志管理,做笔记,做工程计划或者写网页。Org Mode 通常启用于后缀名为 org 的纯文本文件,使用星号标记有层次的内容(如文章大纲、话题与子话题、嵌套代码),并提供一组函数用于读取并展示这类标记以及操纵内容(如折叠大纲内容、移动元素、更改待办项状态)4。
在 Org Mode 中使用 #+BEGIN_SRC 和 #+END_SRC 来标记代码块,在 #+BEGIN_SRC 后指定嵌入的代码类型,例如嵌入 C 语言源代码:
#+BEGIN_SRC c
int main(void) {
return 0;
}
#+END_SRC
更多关于在 Org Mode 中的文学编程应用可以参见 lujun9972/emacs-document。
Sweave & knitr
Sweave 是 R 语言的 WEB 实现,为什么是 Sweave 而不是 Rweave,没有仔细去找解释,但我猜测是由于 R 语言的前身为 S 语言吧。既然有了 Sweave 为什么没有 Stangle 呢?也是猜测,或许 Sweave 的作者在创作之初就更侧重于将 R 代码及其运行结果嵌入,“织出”最终阅读友好的文档吧。当然,由于 R 是一门统计分析语言,将所有 R 代码提取出来编译成可执行文件并不是它的优势,我猜这应该也是没有 Stangle 的一个原因吧。当然,也并不是没有人打算这么做,fusen 是一个基于 R Markdown 直接生成 R 扩展包的扩展包,从一定程度上应该算是 tangle 的理念实现吧。
Sweave 是基于 R 和 LaTeX 的实现,但 LaTeX 的学习曲线相对比较陡峭,knitr 的出现拓展了 Sweave 的功能,例如:内容方面增加支持了 Markdown 等,代码方面增加支持了 Python 等。除此之外,也衍生出了多种多样的文档格式,例如:幻灯片(xaringan),图书(bookdown)和博客(blogdown)等等。
在 R Markdown 中使用如下方式嵌入代码,在 {} 中指定嵌入代码的类型,例如嵌入并执行 R 语言源代码:
```{r}
add <- function(a, b) {
return(a + b)
}
print(add(1, 1))
```
在同一个 R Markdown 文件中可以同时插入 R 和 Python 等多种不同语言的源代码,通过 reticulate 甚至可以实现 R 和 Python 之间的数据交互。
Jupyter
Jupyter 是从 IPython Notebook 发展而来,基于 Python 语言的强大优势,其在业界迅速占领了一大片应用市场,后来 Jupyter 也逐渐支持其他语言。虽然现在 R Markdown 也支持在 RStuido 等编辑器中逐行运行,但个人认为 Jupyter 的最大优势就在于边写边运行,这也使得 Jupyter 在教育等需要实时运行的领域应用最为广泛。
Jupyter 仍以 .ipynb 为扩展名,其底层为 JSON 格式的文本文件。原生 Jupyter 针对一个文件仅支持一种 Kernel,即运行一种类型的代码,当通过一些技巧也可以实现同时运行多种类型的代码。
Quarto
Quarto 是 Posit(RStudio 的新公司名)开发的一个基于 Pandoc 的开源技术出版系统。Quarto 的目标是改进科学和技术文档的创建和协作过程,其希望将 R Markdown、bookdown、distill、xaringan 等功能统一到一个系统中。
Quarto 的工作流程同 R Markdown 类似,如下图所示:

所以,Quarto 的到来是否意味着 R Markdown 的消失呢?官方 FAQ 给到了否定的答案。不过我认为 Quarto 「一统天下」的野心还是有的,只是基于现状可能这条路还需要再走一阵子。如下是我从当先(2023 年初)现状和个人的一些需求,认为 Quarto 和 R Markdown 之间存在的一些区别:
- 博客方面,个人需要动态输出的场景不多,blogdown 是基于 Hugo 的实现,动态文档是利用 knitr 将 R Markdown 直接渲染为 HTML 再交由 Hugo 处理。支持 Hugo 的自动化部署(例如:Cloudflare Pages,Netlify,Vercel 等)对比 Quarto 的自动化部署选择要更多些。
- 幻灯片方面,xaringan 是基于 remark.js 实现的,Quarto 是基于 reveal.js。两者没有孰优孰劣,接触 remark.js 更久一些,更熟悉一些,可能就更偏好一些,不过 remark.js 目前处于非活跃开发状态,这可能是 Quarto 选择 reveal.js 的一个原因吧。
- 书籍方面,这个不得不说 Quarto 真的是赞了。我认为书籍输出格式是所有格式中最复杂的一个,这也使得在代码执行参数、扩展组件 等方面比 bookdown 支持更灵活的 Quarto 在实践中更好用些。
还是很希望 Quarto 在未来能够做更好的统一,这也会让我们面对不同输出场景中复用更多相同的知识和技巧。
当我谈文学编程时我谈些什么
高德纳提出了文学编程的理念,Peter Seibel 也存在不同的看法:编码并非文学。其实这两者并不是对立的,只是角度不同而已。我认为文学编程更适合数据分析型工程,针对功能系统型工程确实很难融入文学编程。以当下的实践来看,从 R Markdown,到 Jupyter,再到 Quarto,无一例外是针对技术和科学等场景提供数据分析功能,而针对系统工程开发,更多还是遵循着产品文档和工程代码分离。
文学编程是一种理念,类似一门新的语言,从客观上能解决一些特定领域的问题,也能在某些场景中提高效率。但整个生态的发展离不开真正「喜欢」的人参与,不断改善和大力推广才能保证生态的持续发展。除了商业团队的主推以外,我认为开源精神和社区参与也很重要,真正的繁华从来不是一家独大而是全民参与。
可重复性研究
可重复性研究的范畴要比文学编程更广泛,文学编程主要围绕计算机相关科学展开,可重复性研究则是面向全部科学的。可重复性研究指的是科学结果应该在其推论完全透明的方式记录下来 5。

上图生动地描述了可重复性研究的重要性。在此我们依旧围绕计算机相关科学讨论可重复性研究。文学编程通过将代码嵌入文档中实现了代码结果的可重复性动态生成,但除了代码之外,可重复性研究还需要关注代码的运行环境和使用的数据等,这些同样会影响研究的最终结果。
运行环境
硬件、内核、操作系统、语言、扩展包等代码运行环境都会对最终的研究结果产生影响,如下图所示:

硬件问题在苹果推出基于 arm 架构的 M1 芯片时一度带来了不少的麻烦,虽然 macOS 提供了转义工具,但在推出的早起仍出现大量软件兼容问题。不过随着这几年的发展,软件的兼容性问题已经得到了极大的改善,因此在硬件这一层几乎不再会有太多问题。
内核和操作系统可以粗略的认为是同一层级,这也是在日常研究中会经常遇到的问题。有时候在自己电脑系统上跑地好好的代码,拿到别人电脑上就会出现各种问题。在工程部署阶段,通过 docker 等虚拟化技术是可以保证代码运行的系统环境是相同的,但在分析研究阶段这并不好用。在这个层面感觉比较好的解决方案就是使用多系统兼容的软件、语言、扩展包等,如果确实需要使用指定系统的工具,在代码层面实现兼容或提示兼容问题会是不错的选择。
语言和扩展包层面的问题在真实场景中遇到的并不多,我们不必非要在 Python 和 R 中二选一,也不必非要在 PyTorch 和 Tensorflow 中二选一。但至少要保证使用相关研究领域中常用的工具、语言和扩展包,当然这些最好甚至应该是开源的,这样其他人才能够无障碍的获取相关代码依赖。
数据公开
在可重复性研究中,数据公开也很重要,没有研究的输入数据,哪怕分析代码全部公开,也无法得到相同的研究结果。最理想的情况就是完全公开所用的原始数据,但这个在涉及到私有域数据时往往又是不现实的。针对这个问题有多种可以尝试解决的方案:
- 数据脱敏。例如:针对涉及隐私的 ID 可以转换为无意义的 ID,一般情况不会对研究产生影响。例如:针对涉及商业机密的价格或销量可以添加扰动量或进行分箱处理,但这会对研究产生一定的影响。
- 人造数据。针对所需的数据格式完全人工创造虚拟数据,不过在复杂场景下其成本较高,甚至无法实现。
-
Knuth, Donald Ervin. “Literate programming.” The computer journal 27.2 (1984): 97-111. ↩︎