随着深度神经网络模型的复杂度越来越高,除了训练阶段需要大量算力外,模型推理阶段也较多的资源。在深度学习落地应用中,受部署环境的影响,尤其是在边缘计算场景中,有限的计算资源成为了复杂模型的应用壁垒。
复杂模型的部署问题突出表现在三个方面,如下图所示:

- 速度:实时响应效率的要求,过长的响应耗时会严重影响用户体验。
- 存储:有限的内存空间要求,无法加载超大模型的权重从而无法使用模型。
- 能耗:移动场景的续航要求,大量的浮点计算导致移动设备耗电过快。
针对上述三类问题,可以从模型压缩和推理加速两个角度出发,在保持一定模型精度的情况下,让模型速度更快、体积更小、能耗更低。
模型压缩
常用的模型压缩方法有如下几种类型:

剪裁
剪裁(Pruning)的核心思想是在尽量保持模型精度不受影响的前提下减少网络的参数量,例如减少网络中连接或神经元的数量,如下图所示:

剪裁最常用的步骤如下:
- 训练:在整个剪裁过程中,该步骤主要为预训练过程,同时为后续的剪裁工作做准备。
- 修剪:通过具体的方法对网络进行剪裁,并对网络重新进行评估以确定是否符合要求。
- 微调:通过微调恢复由于剪裁对模型带来的性能损耗。
对网络进行剪裁的具体方法可以分为非结构化剪裁和结构化剪裁。
非结构化剪裁是细粒度的剪裁方法,一般通过设定一个阈值,高于该阈值的权重得以保留,低于该阈值的权重则被去除。非结构化剪裁虽然方法简单、模型压缩比高,但也存在诸多问题。例如:全局阈值设定未考虑不同层级的差异性,剪裁信息过多有损模型精度且无法还原,剪裁后的稀疏权重矩阵需要硬件层支持方可实现压缩和加速的效果等。
结构化剪裁是粗粒度的剪裁方法,例如对网络层、通道、滤波器等进行剪裁。在滤波器剪裁中,通过评估每个滤波器的重要性(例如:Lp 范数)确定是否保留。结构化剪裁算法相对复杂、控制精度较低,但剪裁策略更为有效且不需要硬件层的支持,可以在现有深度学习框架上直接应用。
量化
神经网络中的计算通常采用浮点数(FP32)进行计算,量化(Quantization)的基本思想是将浮点计算替换为更低比特(例如:FP16,INT8 等)的计算,从而降低模型体积加快模型推理速度。
数值的量化可以看做一个近似过程,主要可以分为两类:
- 定点近似:通过缩小浮点数表示中指数部分和小数部分的位宽实现。映射过程不需要额外的参数,实现相对简单,但针对较大数值的精度损失较大。
- 范围近似:通过统计分析,经过缩放和平移映射浮点数。映射过程需要存储额外的参数,计算时需要先反量化,计算相对复杂,但精度更高。
范围近似又可以分为线性映射和非线性映射两种。
线性映射将浮点数映射到量化空间时采用如下计算公式:
$$ \begin{aligned} r &= S \left(q - Z\right) \\ q &= round \left(\dfrac{r}{S} + Z\right) \end{aligned} $$
其中,$r, q$ 分别表示量化前和量化后的值,$S, Z$ 为量化系数。一般化的非对称映射如下图所示:

其中,
$$ \begin{aligned} S &= \dfrac{r_{max} - r_{min}}{q_{max} - q_{min}} \\ Z &= q_{min} - \dfrac{r_{min}}{S} \end{aligned} $$
非线性映射考虑了数据本身的分布情况。以分位量化方法为例,其基本思想是通过分位点对数据进行划分,使得各个区间之间的数据量相等,然后将同一个区间的数据映射为相同值,从而实现量化。
量化粒度是指控制多少个待量化的参数共享一组量化系数,通常粒度越大,精度损失越大。以 Transformer 模型为例,不同粒度的量化方式如下图所示:
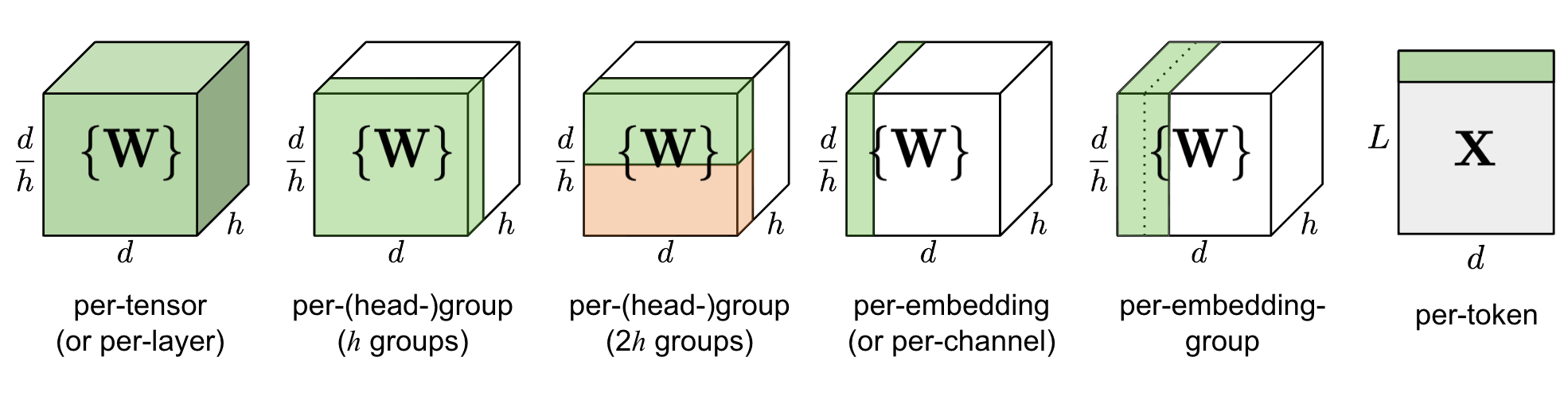
其中,$d$ 为模型大小与隐层维度之比,$h$ 为多头自注意中的头数。
模型量化分为两种:
- 权重量化:即对网络中的权重执行量化操作。数值范围与输入无关,量化相对容易。
- 激活量化:即对网络中不含权重的激活类操作进行量化。输出与输入有关,需要统计数据动态范围,量化相对困难。
根据是否进行训练可以将量化方法分为两大类,如下图所示:

- 训练后量化(Post Traning Quantization,PTQ):方法简单高效,无需重新训练模型。根据是否量化激活又分为:
- 动态:仅量化权重,激活在推理阶段量化,无需校准数据。
- 静态:量化权重和激活,需要校准数据。
- 量化感知训练(Quantization Aware Traning,QAT):方法相对复杂,需要在模型中添加伪量化节点模拟量化,需要重新训练模型。
三种不同量化方法之间的差异如下图所示:

神经结构搜索
神经结构搜索(Network Architecture Search,NAS)旨在以一种自动化的方式,解决高难度的复杂神经网络设计问题。根据预先定义的搜索空间,神经结构搜索算法在一个庞大的神经网络集合中评估结构性能并寻找到表现最佳的网络结构。整个架构如下图所示:

近年来基于权重共享的结构搜索方法受到广泛关注,搜索策略和性能评估高度相关,因此两者往往合为一体表示。
搜索空间包含了所有可搜索的网络结构,越大的搜索空间可以评估更多结构的性能,但不利于搜索算法的收敛。搜索空间从搜索方式角度分为两种:
- 全局搜索空间:通过链式、跳跃链接、分支等方式搜索整个网络结构。
- 基于结构单元的搜索空间:仅搜索结构单元,减少搜索代价,提高结构的可迁移性。
搜索策略即如何在搜索空间根据性能评估选择最优的网络结构。具体包含随机搜索、贝叶斯优化、进化算法、强化学习和基于梯度的方法。
性能评估最简单的方法就是对数据划分验证集,针对不同的网络结构重新训练并评估其在验证集上的表现。但这种方法所需的计算成本很高,无法在实践中落地应用。一些基于权重共享的结构搜索方法能够一定程度地加速搜索,因此考虑搜索策略和性能评估任务的相关性,在当前架构中往往将这两部分统一表述为搜索策略。
知识蒸馏
知识蒸馏(Knowledge Distillation,KD)是一种教师-学生(Teacher-Student)训练结构,通常是已训练好的教师模型提供知识,学生模型通过蒸馏训练来获取教师的知识。它能够以轻微的性能损失为代价将复杂教师模型的知识迁移到简单的学生模型中。
知识蒸馏架构如下图所示:

上半部分为教师模型,下半部分为学生(蒸馏)模型。将教师模型的输出作为软标签与学生模型的软预测计算蒸馏损失,将真实的硬标签与学生模型的硬预测计算学生损失,最终将两种损失结合训练学生模型。
论文 1 给出了软标签的计算公式:
$$ q_i = \dfrac{\exp \left(z_i / T\right)}{\sum_j \exp \left(z_j / T\right)} $$
其中,$T$ 为温度系数,用来控制输出概率的软化程度。不难看出当 $T = 1$ 时,公式的输出即为网络输出 $Softmax$ 的类概率。$T$ 越大,$Softmax$ 的类概率分布越平滑,这可以让学生模型学习到教师模型对负标签的归纳信息。
参考
可供使用的模型压缩库有:
- PyTorch:剪裁,量化,神经网络搜索,知识蒸馏
- TensorFlow:剪裁,量化
- PaddleSlim:支持剪裁、量化、神经网络搜索、知识蒸馏,适配 PaddlePaddle 框架。
- PocketFlow:支持剪裁、量化,适配 TensorFlow 框架。
- NNI:支持剪裁、量化、神经网络搜索,适配 TensorFlow、PyTorch 等框架。
- TinyNeuralNetwork:支持剪裁、量化,适配 PyTorch 框架。
- DeepSpeed:支持剪裁、量化,适配 PyTorch 框架。
- Intel Neural Compressor:支持剪裁、量化、知识蒸馏,适配 TensorFlow、PyTorch、ONNX 等框架。
- Neural Network Compression Framework:支持剪裁、量化,适配 TensorFlow、PyTorch、ONNX、OpenVINO 等框架。
推理加速

硬件加速
硬件加速是指将计算交由专门的硬件以获得更快的速度。在深度学习领域最简单的体现就是利用 GPU 进行推理会比利用 CPU 更快。除此之外,在给定的硬件环境中,利用针对性优化的推理框架可以更充分的利用硬件特性提升预测效率。
并行计算
并行计算是指将计算的过程分解成小部分,以并发方式运行实现计算效率的提升。在模型训练和推理阶段,主流的并行方式有:
- 数据并行(Data Parallel):将数据集切分为多份,每个设备负责其中一部分。
- 流水线并行(Pipeline Parallel):将模型纵向拆分,每个设备只包含模型的部分层,数据在一个设备完成计算后传递给下一个设备。
- 张量并行(Tensor Parallel):将模型横向拆分,将模型的每一层拆分至不同设备,每一层计算都需要多个设备合作完成。
参考
可供使用的推理加速库有:
| 库 | 平台 | CPU | GPU & NPU | 框架 | 系统 |
|---|---|---|---|---|---|
| TensorRT | 服务端 | 不支持 | CUDA | TensorFlow PyTorch ONNX 等 |
Windows Linux 等 |
| Triton | 服务端 | x86 ARM |
CUDA | TensorFlow PyTorch ONNX 等 |
Windows Linux 等 |
| OpenVINO | 服务端 | Intel ARM |
OpenCL | TensorFlow PyTorch PaddlePaddle ONNX 等 |
Windows Linux macOS 等 |
| Paddle Inference | 服务端 | x86 ARM |
CUDA | PaddlePaddle | Windows Linux macOS 等 |
| MNN | 服务端 移动端 |
x86 ARM |
CUDA OpenCL Vulkan Metal HiAI CoreML |
TensorFlow ONNX 等 |
Windows Linux macOS Android iOS 等 |
| TNN | 服务端 移动端 |
x86 ARM |
CUDA OpenCL Metal HiAI CoreML |
TensorFlow PyTorch ONNX 等 |
Windows Linux macOS Android iOS 等 |
| Tensorflow Lite | 移动端 | ARM | OpenCL Metal NNAPI Core ML |
Tensorflow | Android iOS 等 |
| PyTorch Mobile | 移动端 | ARM | Vulkan Metal NNAPI |
PyTorch | Android iOS 等 |
| Paddle Lite | 移动端 | x86 ARM |
OpenCL Metal NNAPI |
PaddlePaddle | Android iOS 等 |
| ncnn | 移动端 | x86 ARM |
Vulkan | TensorFlow PyTorch ONNX 等 |
Android iOS 等 |
本文未对模型压缩和推理加速进行深入展开,仅作为工业实践的基础概念解释。本文参考了大量前人之作,在此一并引用 2 3 4 5 6 7。
-
Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531. ↩︎
-
模型压缩概述:https://paddlepedia.readthedocs.io/en/latest/tutorials/model_compress/model_compress.html ↩︎
-
Large Transformer Model Inference Optimization:https://lilianweng.github.io/posts/2023-01-10-inference-optimization/ ↩︎
-
深度学习模型压缩方法:剪枝:https://zhuanlan.zhihu.com/p/609126518 ↩︎
-
模型量化原理与实践:https://robot9.me/ai-model-quantization-principles-practice/ ↩︎
-
李航宇, 王楠楠, 朱明瑞, 杨曦, & 高新波. (2021). 神经结构搜索的研究进展综述. 软件学报, 33(1), 129-149. ↩︎
-
黄震华, 杨顺志, 林威, 倪娟, 孙圣力, 陈运文, & 汤庸. (2022). 知识蒸馏研究综述. 计算机学报, 45(3). ↩︎