本文为《强化学习系列》文章
强化学习简介
强化学习(Reinforcement Learning,RL)是机器学习中的一个领域,是学习“做什么(即如何把当前的情景映射成动作)才能使得数值化的收益信号最大化”。学习者不会被告知应该采取什么动作,而是必须自己通过尝试去发现哪些动作会产生最丰厚的收益。
强化学习同机器学习领域中的有监督学习和无监督学习不同,有监督学习是从外部监督者提供的带标注训练集中进行学习(任务驱动型),无监督学习是一个典型的寻找未标注数据中隐含结构的过程(数据驱动型)。强化学习是与两者并列的第三种机器学习范式,强化学习带来了一个独有的挑战——“试探”与“开发”之间的折中权衡,智能体必须开发已有的经验来获取收益,同时也要进行试探,使得未来可以获得更好的动作选择空间(即从错误中学习)。

在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment):
- 智能体:可以感知环境的状态(State),并根据反馈的奖励(Reward)学习选择一个合适的动作(Action),来最大化长期总收益。
- 环境:环境会接收智能体执行的一系列动作,对这一系列动作进行评价并转换为一种可量化的信号反馈给智能体。

除了智能体和环境之外,强化学习系统有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
- 策略:定义了智能体在特定时间的行为方式。策略是环境状态到动作的映射。
- 回报函数:定义了强化学习问题中的目标。在每一步中,环境向智能体发送一个称为收益的标量数值。
- 价值函数:表示了从长远的角度看什么是好的。一个状态的价值是一个智能体从这个状态开始,对将来累积的总收益的期望。
- 环境模型:是一种对环境的反应模式的模拟,它允许对外部环境的行为进行推断。
强化学习是一种对目标导向的学习与决策问题进行理解和自动化处理的计算方法。它强调智能体通过与环境的直接互动来学习,而不需要可效仿的监督信号或对周围环境的完全建模,因而与其他的计算方法相比具有不同的范式。
强化学习使用马尔可夫决策过程的形式化框架,使用状态,动作和收益定义学习型智能体与环境的互动过程。这个框架力图简单地表示人工智能问题的若干重要特征,这些特征包含了对因果关系的认知,对不确定性的认知,以及对显式目标存在性的认知。
价值与价值函数是强化学习方法的重要特征,价值函数对于策略空间的有效搜索来说十分重要。相比于进化方法以对完整策略的反复评估为引导对策略空间进行直接搜索,使用价值函数是强化学习方法与进化方法的不同之处。
示例和应用
以经典的 Flappy Bird 游戏为例,智能体就是游戏中我们操作的小鸟,整个游戏中的天空和遮挡管道即为环境,动作为玩家单击屏幕使小鸟飞起的行为,如下图所示:

目前,强化学习在包括游戏,广告和推荐,对话系统,机器人等多个领域均展开了广泛的应用。
游戏
AlphaGo 1 是于 2014 年开始由英国伦敦 Google DeepMind 开发的人工智能围棋软件。AlphaGo 使用蒙特卡洛树搜索(Monte Carlo tree search),借助估值网络(value network)与走棋网络(policy network)这两种深度神经网络,通过估值网络来评估大量选点,并通过走棋网络选择落点。
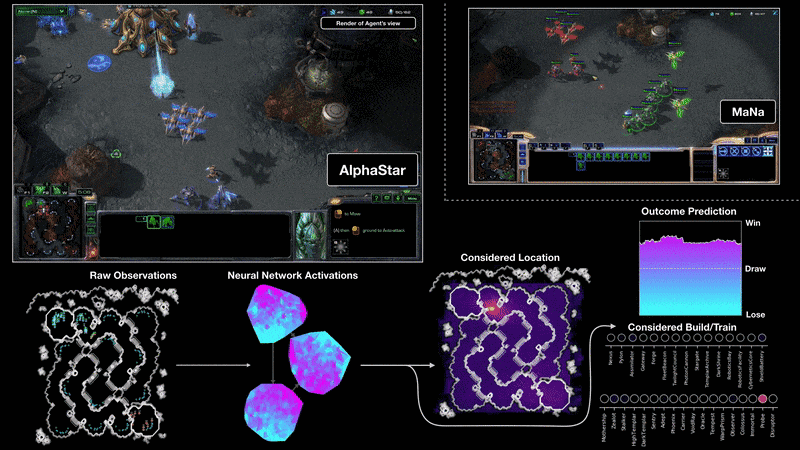
AlphaStar 2 3 是由 DeepMind 开发的玩 星际争霸 II 游戏的人工智能程序。AlphaStar 是由一个深度神经网路生成的,它接收来自原始游戏界面的输入数据,并输出一系列指令,构成游戏中的一个动作。
更具体地说,神经网路体系结构将 Transformer 框架运用于模型单元(类似于关系深度强化学习),结合一个深度 LSTM 核心、一个带有 pointer network 的自回归策略前端和一个集中的值基线。这种先进的模型将有助于解决机器学习研究中涉及长期序列建模和大输出空间(如翻译、语言建模和视觉表示)的许多其他挑战。
AlphaStar 还使用了一种新的多智能体学习算法。该神经网路最初是通过在 Blizzard 发布的匿名人类游戏中进行监督学习来训练的。这使得 AlphaStar 能够通过模仿学习星际争霸上玩家所使用的基本微观和宏观策略。这个初级智能体在 95% 的游戏中击败了内置的「精英」AI 关卡(相当于人类玩家的黄金级别)。
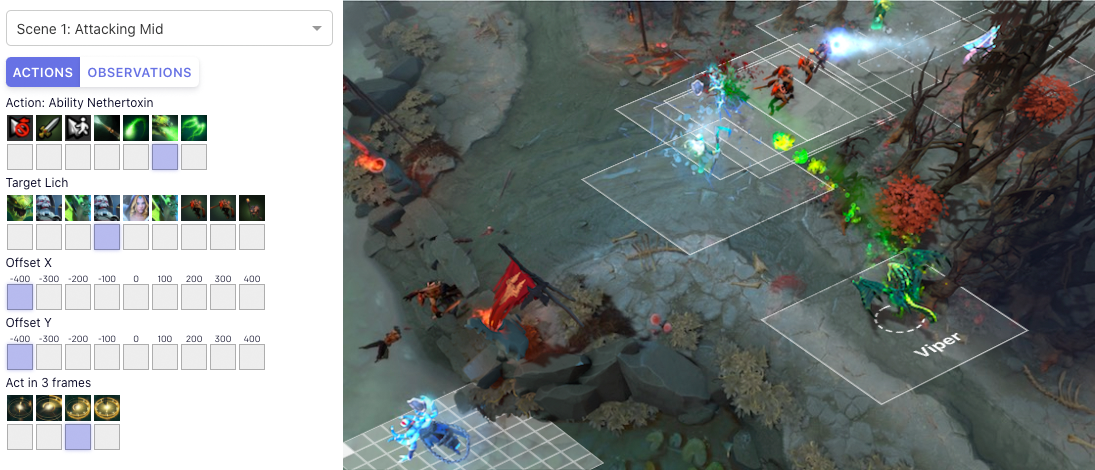
OpenAI Five 4 是一个由 OpenAI 开发的用于多人视频游戏 Dota 2 的人工智能程序。OpenAI Five 通过与自己进行超过 10,000 年时长的游戏进行优化学习,最终获得了专家级别的表现。
Pluribus 5 是由 Facebook 开发的第一个在六人无限注德州扑克中击败人类专家的 AI 智能程序,其首次在复杂游戏中击败两个人或两个团队。

广告和推荐

对话系统

机器人

开放资源
开源实验平台
开源框架
- deepmind/trfl/
- deepmind/open_spiel
- google/dopamine
- tensorflow/agents
- keras-rl/keras-rl
- tensorforce/tensorforce
- facebookresearch/ReAgent
- thu-ml/tianshou
- astooke/rlpyt
- NervanaSystems/coach
- PaddlePaddle/PARL
开源模型
其他资源
- ShangtongZhang/reinforcement-learning-an-introduction
- aikorea/awesome-rl
- openai/spinningup
- udacity/deep-reinforcement-learning
-
https://deepmind.com/research/case-studies/alphago-the-story-so-far ↩︎
-
https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii ↩︎
-
https://deepmind.com/blog/article/AlphaStar-Grandmaster-level-in-StarCraft-II-using-multi-agent-reinforcement-learning ↩︎
-
https://ai.facebook.com/blog/pluribus-first-ai-to-beat-pros-in-6-player-poker/ ↩︎