本文为《复杂网络系列》文章,本文内容主要参考自:《网络科学引论》
网络(network)也称为图(graph),是一个由多个顶点(vertex)及连接顶点的边(edge)组成的集合。在网络中,我们通常用 $n$ 表示顶点的数目,用 $m$ 表示边的数目。在大多数网络中两个顶点之间都只有一条边,极少数情况下,两个顶点之间有多条边,称之为重边(multiedge)。在极特殊情况下,还会存在连接到顶点自身的边,称之为自边(self-edge)。既没有自边也没有重边的图称之为简单网络(simple network)或简单图(simple graph),存在重边的网络称之为重图(multigraph)。相关概念示例如下:
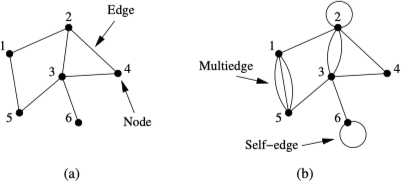
网络表示
无向网络
对于一个包含 $n$ 个顶点的无向图,可以用整数 $1$ 到 $n$ 对各个顶点进行标注。如果用 $\left(i, j\right)$ 表示顶点 $i$ 和顶点 $j$ 之间的边,那么通过给定 $n$ 的值及所有边的列表就能表示一个完整的网络,这种表示方法称之为边列表(edge list)。
相比于边列表,邻接矩阵(adjacency matrix)可以更好地表示网络。一个简单图的邻接矩阵 $\mathbf{A}$ 中元素 $A_{ij}$ 的含义如下:
$$ A_{ij}=\left\{\begin{array}{ll} 1 & \text{如果顶点 } i \text{ 和顶点 } j \text{ 之间存在一条边} \\ 0 & \text{其他} \end{array}\right. $$
对于一个没有自边的网络,其邻接矩阵有两个特点:
- 邻接矩阵对角线上的元素取值均为零。
- 邻接矩阵是对称的。
加权网络
对于加权网络(weighted network)和赋值网络(valued network)可以将邻接矩阵中对应元素的值设定为相应的权重的方式来进行表示。
有向网络
有向网络(directed network)或有向图(directed graph)有时简称为 digraph,在这类网络中,每条边都有方向,从一个顶点指向另一个顶点,称之为有向边(directed edge)。
提示
有向网络的邻接矩阵中元素 $A_{ij} = 1$ 时表示存在从顶点 $j$ 到顶点 $i$ 的边。虽然表示方法有些出人意料,但在数据计算上会带来极大的方便。
超图
在某些类型的网络中,一些边会同时连接多个顶点。例如:创建一个社会网络,用来表示一个大规模社区中的各个家庭。每个家庭都可能会有两名或多名成员,因此表示这些家庭之间关系的做好方法就是使用一种广义边来同时连接多个顶点。这样的边称之为超边(hyperedge),含有超边的网络称之为超图(hypergraph)。下图 (a) 表示一个小型超图,其中超边用环的形式表示。
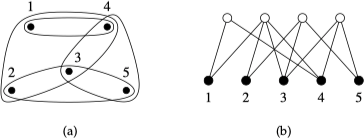
当一个网络中的顶点因为某种群组之间的关系被连接在一起时,可以使用超图来表示这个网络,在社会学中,这样的网络称之为隶属网络。对于超图,可于采用二分图的方式进行表示,通过引入 4 个新的顶点代表 4 个群组,在顶点及其所属群组之间通过边连接,如上图 (b) 所示。
二分网络
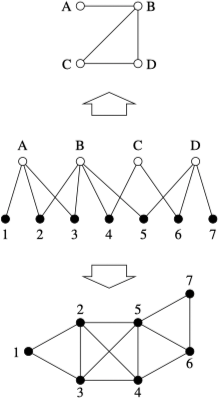
群组内成员之间的关系可以用超图中的超边表示,也可以等价地用更方便的二分图(bipartite network)表示。这种网络中有两类顶点,一类顶点代表原始顶点,另一类顶点则表示原始顶点所属的群组。
二分网络中,与邻接矩阵等价的是一个矩形矩阵,称之为关联矩阵(incidence matrix)。如果 $n$ 代表人数或网络中的成员数目,$g$ 是群组的数目,那么关联矩阵 $\mathbf{B}$ 是一个 $g \times n$ 的矩阵,其元素 $B_{ij}$ 的取值含义如下:
$$ B_{ij}=\left\{\begin{array}{ll} 1 & \text{如果顶点 } j \text{ 属于群组 } i \\ 0 & \text{其他} \end{array}\right. $$
研究统一类型顶点之间的直接联系可以通过对二分网络进行单模投影(one-mode projection),推导出同类顶点之间的直接联系,如下图所示。
树
树(tree)是连通的、无向的且不包含闭合循环的网络,如下图所示。
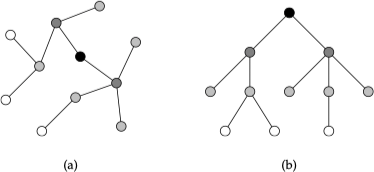
连通是指任意两个顶点之间都存在一条相互可达的路径。一个网络可能有两个或多个部分组成,每个部分相互之间不连通,如果任意单独的部分都为树,则称这个网络为森林(forest)。
由于树没有闭合循环,因此任意两个顶点之间有且只有一条相连的路径。如果一个树有 $n$ 个顶点,那么它有且仅有 $n - 1$ 条边。
度
图中顶点的度(degree)是指与其直接相连的边数目。将顶点 $i$ 的度表示为 $k_i$,对于有 $n$ 个顶点构成的无向图,可利用邻接矩阵将度表示为:
$$ k_i = \sum_{j=1}^{n} A_{ij} $$
在无向图中,每个边都有两端,如果一共有 $m$ 条边,那么就有 $2m$ 个边的端点。同时,边的端点数与所有顶点度的总和相等:
$$ 2m = \sum_{j=1}^{n} k_i $$
即
$$ m = \dfrac{1}{2} \sum_{i=1}^{n} k_i = \dfrac{1}{2} \sum_{ij} A_{ij} $$
无向图中顶点度的均值 $c$ 为:
$$ c = \dfrac{1}{n} \sum_{i=1}^{n} k_i $$
综上可得:
$$ c = \dfrac{2m}{n} $$
在一个简单图中,可能的边数的最大值是 $\dbinom{n}{2} = \dfrac{1}{2} n \left(n - 1\right)$ 个。图的连通度(connectance)或密度(density)$\rho$ 是所有图中实际出现的边的数目与边数最大值之间的比值:
$$ \rho = \dfrac{m}{\dbinom{n}{2}} = \dfrac{2m}{n \left(n - 1\right)} = \dfrac{c}{n - 1} $$
在有向图中,每个顶点有两个度:入度(in-degree)是连接到该顶点的入边的数目,出度(out-degree)是出边数目。当从顶点 $j$ 到 $i$ 有一条边时,邻接矩阵中对应的元素 $A_{ij} = 1$,则入度和出度记为:
$$ k_i^{\text{in}} = \sum_{j=1}^{n} A_{ij}, k_j^{\text{out}} = \sum_{i=1}^{n} A_{ij} $$
在有向图中,边的数目 $m$ 等于入边的端点数总和,也等于出边的端点数总和,有:
$$ m=\sum_{i=1}^{n} k_{i}^{\mathrm{in}}=\sum_{j=1}^{n} k_{j}^{\mathrm{out}}=\sum_{i j} A_{i j} $$
每个有向图的入度的均值 $c_{\text{in}}$ 和出度的均值 $c_{\text{out}}$ 是相等的:
$$ c_{\text {in }}=\frac{1}{n} \sum_{i=1}^{n} k_{i}^{\text {in }}=\frac{1}{n} \sum_{j=1}^{n} k_{j}^{\text {out }}=c_{\text {out }} $$
简化后有:
$$ c = \dfrac{m}{n} $$
路径
网络中的路径是指由一组顶点构成的序列,序列中每两个连续顶点都通过网络中的边连接在一起,路径长度等于该路径经过的边的数目(而非顶点的数目)。从顶点 $j$ 到顶点 $i$ 存在长度为 $r$ 的路径总数为:
$$ N_{ij}^{\left(r\right)} = \left[\mathbf{A}^r\right]_{ij} $$
其中,$\left[\cdots\right]_{ij}$ 表示矩阵中的第 $i$ 行、第 $j$ 列的元素。
测地路径(geodesic path),简称为最短路径(shortest path),即两个顶点间不存在更短路径的路径。图的直径(diameter)是指图中任意一对相互连接的顶点之间的最长测地路径长度。欧拉路径(Eulerian path)是经过网络中的所有边且每条边只经过一次的路径。哈密顿路径(Hamiltonian path)是访问网络的所有顶点且每个顶点只访问一次的路径。
分支
如果一个网络中两个顶点之间不存在路径,则称这个网络是非连通(disconnected)的,如果网络中任意两个顶点之间都能找到一条路径,则称这个网络是连通(connected)的。
网络中的子群称为分支(component)。分支是网络中顶点的子集,该子集中任何两个顶点之间至少存在一条路径,在保证该性质的前提下,网络中其他顶点都不能被添加到这个子集中。在保证一个给定性质的前提下,不能再向它添加其他顶点,就称其为最大子集(maximal subset)。
连通度
如果两条路经除了起点和终点外,不共享其他任何顶点,那么这两条路径是顶点独立(vertex-independent)的。如果两条路径是顶点独立的,那么也是边独立的,反之则不成立。
两个顶点之间的独立路径数称为顶点之间的连通度(connectivity),如果明确考虑边还是顶点,则需利用边连通度(edge connectivity)及顶点连通度(vertex connectivity)的概念。
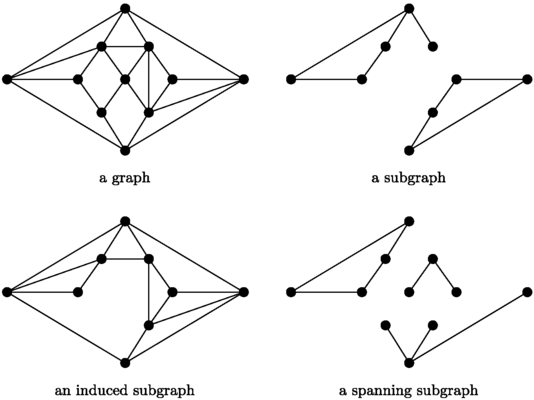
子图
令原图表示为 $G = \left(V, E\right)$,其中,$V$ 是图中所有顶点的集合,$E$ 是图中所有边的集合,有:
- 子图(subgraph):
$G'$中所有顶点和边均包含于原图$G$中,即$E' \in E, V' \in V$。 - 生成子图(spanning subgraph):
$G'$中顶点同原图$G$相同,且$E' \in E$。 - 导出子图(induced subgraph):
$G'$中,$V' \in V$,同时对于$V'$中任意一个顶点,只要在原图$G$中有对应的边,则也应包含在$E'$中。
Motif
Motif 1 被定义为反复出现的重要连接模式。这些模式在真实的网络中要比随机网络中出现的更加频繁,如下图所示:
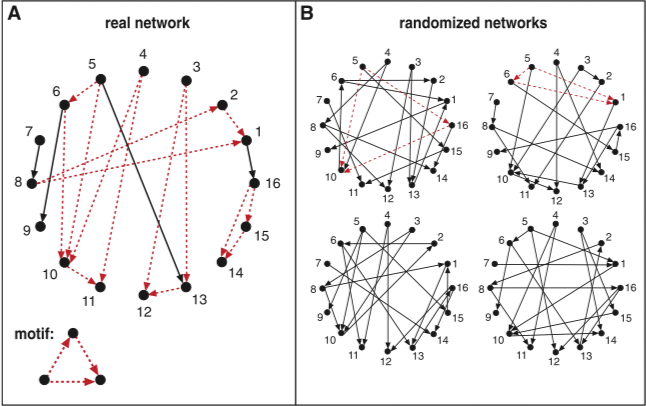
Motif 的显著性定义为:
$$ Z_i = \dfrac{N_i^{\text{real}} - \bar{N}_i^{\text{rand}}}{\text{std} \left(N_i^{\text{rand}}\right)} $$
其中,$N_i^{\text{real}}$ 为模式在真实图中出现的次数,$N_i^{\text{rand}}$ 为模式在随机图中出现的次数。
Graphlets
Graphlets 是对 Motif 的扩展,Motif 是从全局的角度发现模式,而 Graphlets 是从局部角度出发。Graphlets 是连接的非同构子图,这里要求子图为导出子图。下图展示了节点数为 2 至 5 的所有 Graphlets:
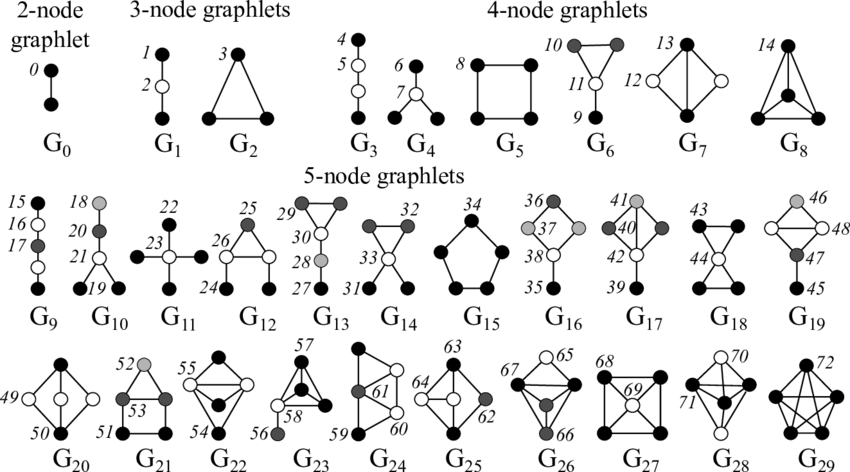
更多关于 Motif 和 Graphlets 的细节请参见 2 3 。
测度和度量
中心性
度中心性
中心性(centrality)是研究“网络中哪些顶点是最重要或最核心的?”这个问题的一个概念。网络中心性的最简单的测度是顶点的度,即与顶点相连的边的数量。有时为了强调度作为中心性测度的用途,在社会学中也称之为度中心性(degree centrality)。
特征向量中心性
度中心性可自然地扩展为特征向量中心性(eigenvector centrality)。可以将度中心性理解为给某顶点所有邻居顶点赋予一个“中心性值”,但并非所有连接顶点的值都是相同的。很多情况下,一个顶点会由于连接到一些本身很重要的点,而使自身的重要性得到提升,这就是特征向量中心性的本质。
对于每个顶点 $i$,假设其中心性为 $x_i$。对于所有 $i$,可以设其初始值 $x_i = 1$,利用该值可以计算出另一个更能体现中心性的值 $x'_i$,将 $x'_i$ 定义为 $i$ 所有邻居顶点的中心性之和:
$$ x'_i = \sum_{j} A_{ij} x_j $$
重复该过程可以得到更好的估计值,重复 $t$ 步后,中心性 $\mathbf{x} \left(t\right)$ 的计算公式如下:
$$ \mathbf{x} \left(t\right) = \mathbf{A}^t \mathbf{x} \left(0\right) $$
当 $t \to \infty$ 时,中心性向量的极限与邻接矩阵中的主特征向量成正比。因此,可以等价地认为中心性 $\mathbf{x}$ 满足:
$$ \mathbf{A} \mathbf{x} = \kappa_1 \mathbf{x} $$
其中,$\kappa_1$ 为矩阵 $\mathbf{A}$ 的特征值中的最大值。
特征向量中心性对于有向图和无向图都适用。在有向图中,邻接矩阵是非对称的,因此网络有两类特征向量,通常情况下我们选择右特征向量来定义中心性。因为在有向网络中,中心性主要是由指向顶点的顶点,而不是由顶点指向的顶点赋予的。
Katz 中心性
Katz 中心性解决了特征向量中心性中节点中心性可能为零的问题。通过为网络中每个顶点赋予少量的“免费”中心性,可以定义:
$$ x_i = \alpha \sum_{j} A_{ij} x_j + \beta $$
其中,$\alpha$ 和 $\beta$ 是正常数。使用矩阵表示可以写成:
$$ \mathbf{x} = \alpha \mathbf{A} \mathbf{x} + \beta \mathbf{1} $$
其中,$\mathbf{1}$ 代表向量 $\left(1, 1, 1, \cdots\right)$。重新整理有 $\mathbf{x} = \beta \left(\mathbf{I} - \alpha \mathbf{A}\right)^{-1} \mathbf{1}$,由于只关心相对值,通常可以设置 $\beta = 1$,则有:
$$ \mathbf{x} = \left(\mathbf{I} - \alpha \mathbf{A}\right)^{-1} \mathbf{1} $$
PageRank
Katz 中心性有一个不足,被一个 Katz 中心性较高的顶点指向的顶点具有较高的 Katz 中心性,但如果这个中心性较高的顶点指向大量顶点,那么这些大量被指向的顶点也会拥有较高的中心性,但这种估计并非总是恰当的。在新的中心性中,那些指向很多其他顶点的顶点,即使本身的中心性很高,但也只能传递给它指向的每个顶点少量的中心性,定义为:
$$ x_{i}=\alpha \sum_{j} A_{i j} \frac{x_{j}}{k_{j}^{\text {out }}}+\beta $$
其中,$k_j^{\text{out}}$ 为顶点的出度,当 $k_j^{\text{out}} = 0$ 时可以将其设定为任何一个非零值,都不会影响计算结果。利用矩阵的形式,可以表示为:
$$ \mathbf{x}=\alpha \mathbf{AD}^{-1} \mathbf{x}+\beta \mathbf{1} $$
其中,$\mathbf{D}$ 为对角矩阵,$D_{ii} = \max \left(k_j^{\text{out}}, 1\right)$。同之前一样,$\beta$ 只是整个公式的因子,设置 $\beta = 1$,有:
$$ \mathbf{x}=\left(\mathbf{I}-\alpha \mathbf{A} \mathbf{D}^{-1}\right)^{-1} \mathbf{1} $$
该中心性即为 PageRank。
上述 4 种中心性的区别和联系如下表所示:
| 带有常数项 | 不带常数项 | |
|---|---|---|
| 除以出度 | $\mathbf{x} = \left(\mathbf{I}-\alpha \mathbf{A} \mathbf{D}^{-1}\right)^{-1} \mathbf{1}$PageRank |
$\mathbf{x} = \mathbf{A} \mathbf{D}^{-1} \mathbf{x}$度中心性 |
| 不除出度 | $\mathbf{x} = \left(\mathbf{I} - \alpha \mathbf{A}\right)^{-1} \mathbf{1}$Katz 中心性 |
$\mathbf{x} = \kappa_1^{-1} \mathbf{A} \mathbf{x}$特征向量中心性 |
接近度中心性
接近度中心性(closeness centrality)用于度量一个顶点到其他顶点的平均距离。
$$ C_{i}=\frac{1}{\ell_{i}}=\frac{n}{\sum_{j} d_{i j}} $$
其中,$d_{i j}$ 表示从顶点 $i$ 到 $j$ 的测地路径长度,即路径中边的总数,$\ell_{i}$ 表示从 $i$ 到 $j$ 的平均测地距离。在大多数网络中,顶点之间的测地距离一般都较小,并且随着网络规模的增长,该值只是以对数级别速度缓慢增长。
在不同分支中的两个顶点之间的测地距离定义为无穷大,则 $C_i$ 为零。为了解决这个问题,最常见的方法是只计算同一分支内部的顶点的平均测地距离。新的定义使用顶点之间的调和平均测地距离:
$$ C_{i}^{\prime}=\frac{1}{n-1} \sum_{j(\neq i)} \frac{1}{d_{i j}} $$
公式中排除了 $j = i$ 的情况,因为 $d_{ii} = 0$。结果也称之为调和中心性(harmonic centrality)。
介数中心性
介数中心性(betweenness centrality)描述了一个顶点在其他顶点之间路径上的分布程度。假设在网络中每两个顶点之间,在每个单位时间内以相等的概率交换信息,信息总是沿着网络中最短测地路径传播,如果有多条最短测地路径则随机选择。由于消息是沿着最短路径以相同的速率传播,因此经过某个顶点的消息数与经过该顶点的测地路径数成正比。测地路径数就是所谓的介数中心性,简称介数。
定义 $n_{st}^i$ 为从 $s$ 到 $t$ 经过 $i$ 的测地路径数量,定义 $g_{st}$ 为从 $s$ 到 $t$ 的测地路径总数,那么顶点 $i$ 的介数中心性可以表示为:
$$ x_{i}=\sum_{s t} \frac{n_{s t}^{i}}{g_{s t}} $$
高介数中心性的顶点由于控制着其他顶点之间的消息传递,在网络中有着很强的影响力。删除介数最高的顶点,也最有可能破坏其他顶点之间的通信。
不同中心性的可视化如下图所示:
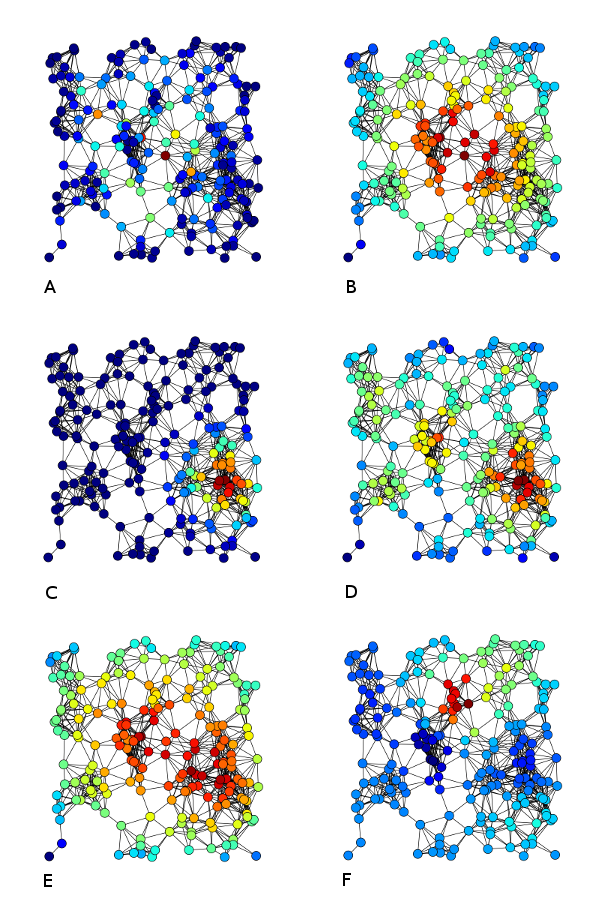
其中,A:介数中心性;B:接近度中心性;C:特征向量中心性;D:度中心性;E:调和中心性;F:Katz 中心性。
传递性
传递性(transitivity)在社会网络中的重要性要比其他网络中重要得多。在数学上,对于关系“$\circ$”,如果 $a \circ b$ 和 $b \circ c$,若能推出 $a \circ c$,则称 $\circ$ 具有传递性。
完全传递性值出现在每一个分支都是全连通的子图或团的网络中。团(clique)是指无向图网络中的一个最大顶点子集,在该子集中任何两个顶点之间都有一条边直接连接。完全传递性没有太多的实际意义,而部分传递性却很有用。在很多网络中,$u$ 认识 $v$ 且 $v$ 认识 $w$,并不能保证 $u$ 认识 $w$,但两者之间相互认识的概率很大。
如果 $u$ 也认识 $w$,则称该路径是闭合的。在社会网络术语中,称 $u, v, w$ 这 3 个顶点形成一个闭合三元组(closed triad)。我们将聚类系数(clustering coefficient)定义为网络中所有长度为 2 的路径中闭合路径所占的比例:
$$ C = \dfrac{\text{长度为 2 的路径中闭合路径数}}{\text{长度为 2 的路径数}} $$
其取值范围在 0 到 1 之间。社会网络的聚类系数比其他网络偏高。
对于顶点 $i$,定地单个顶点的聚类系数为:
$$ C_i = \dfrac{\text{顶点 i 的邻居顶点中直接相连的顶点对数}}{\text{顶点 i 的邻居顶点对总数}} $$
$C_i$ 也称为局部聚类系数(local clustering coefficient),该值代表了 $i$ 的朋友之间互为朋友的平均概率。
相互性
聚类系数观察的是长度为 3 的循环,长度为 2 的循环的频率通过相互性(reciprocity)来度量,该频率描述了两个顶点之间相互指向的概率。
相似性
社会网络分析的另一个核心概念是顶点之间的相似性。构造网络相似性的测度有两种基本方法:结构等价(structural equivalence)和规则等价(regular equivalence),如下图所示:
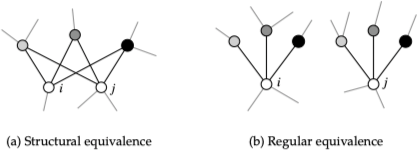
结构等价
针对无向网络中,最简单和最显而易见的结构等价测度就是计算两个顶点的共享邻居顶点数。在无向网络中,顶点 $i$ 和 $j$ 的共享邻居顶点数表示为 $n_{ij}$,有:
$$ n_{ij} = \sum_{k} A_{ik} A_{kj} $$
利用余弦相似度可以更好的对其进行度量。将邻接矩阵的第 $i$ 和第 $j$ 行分别看成两个向量,然后将这两个向量之间的夹角余弦值用于相似性度量,有:
$$ \sigma_{i j}=\cos \theta=\frac{\sum_{k} A_{i k} A_{k j}}{\sqrt{\sum_{k} A_{i k}^{2}} \sqrt{\Sigma_{k} A_{j k}^{2}}} $$
假设网络是不带权重的简单图,上式可以化简为:
$$ \sigma_{i j}=\frac{\sum_{k} A_{i k} A_{k j}}{\sqrt{k_{i}} \sqrt{k_{j}}}=\frac{n_{i j}}{\sqrt{k_{i} k_{j}}} $$
其中,$k_i$ 是顶点 $i$ 的度。余弦相似度的取值范围为从 0 到 1,1 表示两个顶点之间拥有完全相同的邻居节点。
皮尔逊相关系数通过同随机选择邻居顶点条件下共享邻居顶点数的期望值进行比较的方式进行计算,得到的标准的皮尔逊相关系数为:
$$ r_{i j}=\frac{\sum_{k}\left(A_{i k}-\left\langle A_{i}\right\rangle\right)\left(A_{j k}-\left\langle A_{j}\right\rangle\right)}{\sqrt{\sum_{k}\left(A_{i k}-\left\langle A_{i}\right\rangle\right)^{2}} \sqrt{\sum_{k}\left(A_{j k}-\left\langle A_{j}\right\rangle\right)^{2}}} $$
上式的取值范围从 -1 到 1,数值越大表明两者之间越相似。
规则等价
规则等价的顶点不必共享邻居顶点,但是两个顶点的邻居顶点本身要具有相似性。一些简单的代数测度思想如下:定义一个相似性值 $\sigma_{ij}$,若顶点 $i$ 和 $j$ 各自的邻居顶点 $k$ 和 $l$ 本身具有较高的相似性,则 $i$ 和 $j$ 的相似性也较高。对于无向网络,有以下公式:
$$ \sigma_{i j}=\alpha \sum_{k l} A_{i k} A_{j l} \sigma_{k l} $$
或者利用矩阵性质表示为 $\mathbf{\sigma} = \alpha \mathbf{A \sigma A}$。
同质性
在社会网络中,人们倾向于选择那些他们认为与其自身在某些方面相似的人作为朋友,这种倾向性称为同质性(homophily)或同配混合(assortative mixing)。
依据枚举特征的同配混合
假设有一个网络,其顶点根据某个枚举特征(例如:国籍、种族、性别等)分类,且该特征的取值是一个有限集合。如果网络中连接相同类型顶点之间的边所占比例很大,那么该网络就是同配的。量化同配性简单的方法是观测这部分边占总边数的比例,但这并不是很好的度量方法,因为如果所有顶点都是同一个类型,那么测度值就是 1。
好的测度可以通过首先找出连接同类顶点的边所占的比例,然后减去在不考虑顶点类型时,随机连接的边中,连接两个同类顶点的边所占比例的期望值的方式得到。常用的测度为模块度(modularity):
$$ Q=\frac{1}{2 m} \sum_{i j}\left(A_{i j}-\frac{k_{i} k_{j}}{2 m}\right) \delta_{g_{i} g_{i}} $$
其中,$k_i$ 为顶点 $i$ 的度,$g_i$ 为顶点 $i$ 的类型,$m$ 为总边数,$\delta_{ij}$ 为克罗内克函数。该值严格小于 1,如果同类顶点之间边数的实际值大于随机条件下的期望值,则该值为正数,否则为负数,值为正说明该网络是同配混合的。
依据标量特征的同配混合
如果根据标量特征(例如:年龄、收入等)来度量网络中的同质性。由于该类特征具有确定的顺序,因此根据标量的数值,不仅可以指出两个顶点在什么情况下是完全相同的,也可以指出它们在真么情况下是近似相同的。
令 $x_i$ 为顶点 $i$ 的标量值,$\left(x_i, x_j\right)$ 为网络中每一条边 $\left(i, j\right)$ 的两个端点的值,利用协方差可以得到同配系数:
$$ r=\frac{\sum_{i j}\left(A_{i j}-k_{i} k_{j} / 2 m\right) x_{i} x_{j}}{\sum_{i j}\left(k_{i} \delta_{i j}-k_{i} k_{j} / 2 m\right) x_{i} x_{j}} $$
该系数在全同配混合网络中取最大值 1,在全异配混合网络中取最小值 -1,值 0 意味着边两端的顶点值是非相关的。
依据度的同配混合
依据度的同配混合是依据标量特征的同配混合的一个特例。依据度的同配混合网络中,高度数顶点倾向于与其他高度数顶点相连,而低度数顶点倾向于与其他低度数顶点相连。
在同配网络中,度大的顶点倾向于聚集在一起的网络中,我们希望得到网络中这些度大的顶点构成的顶点块或核,它们周围是一些度小的顶点构成的低密度边缘(periphery)。这种核心/边缘结构(core/periphery structure)是社会网络的普遍特征。
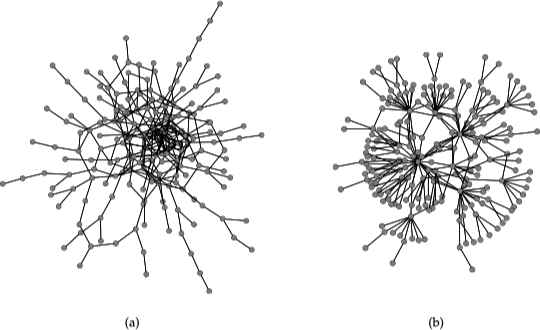
上图 (a) 给出了一个小型的同配混合网络,其核心/边缘结构明显,上图 (b) 给出了一个小型异配混合网络,通常不具备核心/边缘结构,但顶点的分布更加均匀。
-
Milo, R., Shen-Orr, S., Itzkovitz, S., Kashtan, N., Chklovskii, D., & Alon, U. (2002). Network motifs: simple building blocks of complex networks. Science, 298(5594), 824-827. ↩︎
-
Jain, D., & Patgiri, R. (2019, April). Network Motifs: A Survey. In International Conference on Advances in Computing and Data Sciences (pp. 80-91). Springer, Singapore. ↩︎
-
Henderson, K., Gallagher, B., Eliassi-Rad, T., Tong, H., Basu, S., Akoglu, L., … & Li, L. (2012, August). Rolx: structural role extraction & mining in large graphs. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 1231-1239). ↩︎