CNN 的缺陷
卷积神经网络(CNN)在图像领域取得了很大的成功,但同时也存在一定的缺陷。卷积层中的卷积核对输入图像利用卷积运算提取其中的特征。卷积核以一个较小的尺寸并以一定的步长在图像上移动得到特征图。步长越大,特征图的尺寸就越小,过大的步长会丢失部分图像中的特征。池化层作用于产生的特征图上,使得 CNN 可以在不同形式的图像中识别出相同的物体,为 CNN 引入了空间不变性。
CNN 最大的缺陷就是忽略了不同特征之间的相对位置,从而无法从图像中识别出姿势、纹理和变化。CNN 中的池化操作使得模型具有空间不变性,因此模型就不具备等变性。以下图为例,CNN 会把第一幅和第二幅识别为人脸,而将第三幅方向翻转的图识别为不是人脸。池化操作造成了部分信息的丢失,因此需要更多的训练数据来补偿这些损失。

等变和不变
对于一个函数 $f$ 和一个变换 $g$,如果有:
$$ f \left(g \left(x\right)\right) = g \left(f \left(x\right)\right) $$
则称 $f$ 对变换 $g$ 有等变性。
例如,变换 $g$ 为将图像向左平移若干像素,函数 $f$ 表示检测一个人脸的位置。则 $f \left(g \left(x\right)\right)$ 表示先将图片左移,我们将在原图的左侧检测到人脸;$g \left(f \left(x\right)\right)$ 表示先检测人脸位置,然后将人脸位置左移。这两者的输出结果是一样的,与我们施加变换的顺序无关。CNN 中的卷积操作使得它对平移操作具有等变性。
对于一个函数 $f$ 和一个变换 $g: g \left(x\right) = x'$,如果有:
$$ f \left(x\right) = f \left(x'\right) = f \left(g \left(x\right)\right) $$
则称 $f$ 对变换 $g$ 有不变性。
例如,变换 $g$ 为旋转或平移,函数 $f$ 表示检测图中是否有黑色,那么这些变换不会对函数结果有任何影响,可以说函数对该变换具有不变性。CNN 中的池化操作对平移操作具有近似不变性。
逆图形
计算机图形学根据几何数据的内部层次结构来构造可视图像,该表示的结构将对象的相对位置考虑在内。软件采用层次的表示方式将其渲染为屏幕上的图像。人类大脑的工作原理则与渲染过程相反,我们称其为逆图形。大脑中对象的表示并不依赖于视角。
例如下图,人眼可以很容易的分辨出是自由女神像,只是角度不同,但 CNN 却很难做到,因为它不理解 3D 空间的内在。

胶囊网络
胶囊
在引入“胶囊”这个概念的第一篇文献 Transforming Auto-encoders 1 中,Hinton 等人对胶囊概念理解如下:
人工神经网络不应当追求“神经元”活动中的视角不变性(使用单一的标量输出来总结一个局部池中的重复特征检测器的活动),而应当使用局部的“胶囊”,这些胶囊对其输入执行一些相当复杂的内部计算,然后将这些计算的结果封装成一个包含信息丰富的输出的小向量。每个胶囊学习辨识一个有限的观察条件和变形范围内隐式定义的视觉实体,并输出实体在有限范围内存在的概率及一组“实例参数”,实例参数可能包括相对这个视觉实体的隐式定义的典型版本的精确的位姿、照明条件和变形信息。当胶囊工作正常时,视觉实体存在的概率具有局部不变性——当实体在胶囊覆盖的有限范围内的外观流形上移动时,概率不会改变。实例参数却是“等变的”——随着观察条件的变化,实体在外观流形上移动时,实例参数也会相应地变化,因为实例参数表示实体在外观流形上的内在坐标。
人造神经元输出单个标量。对于 CNN 卷积层中的每个卷积核,对整个输入图复制同一个内核的权重输出一个二维矩阵。矩阵中每个数字是该卷积核对输入图像一部分的卷积,这个二维矩阵看作是重复特征检测器的输出。所有卷积核的二维矩阵堆叠在一起得到卷积层的输出。CNN 利用最大池化实现不变性,但最大池化丢失了有价值的信息,也没有编码特征之间的相对空间关系。
胶囊将特征检测的概率作为其输出向量的长度进行编码,检测出的特征的状态被编码为该向量指向的方向。当检测出的特征在图像中移动或其状态发生变化时,概率仍然保持不变(向量的长度没有改变),但它的方向改变了。
下表总结了胶囊和神经元的不同:
| Capsule | Traditional Neuron | ||
|---|---|---|---|
| Input from low-level capsule/neuron | $\text{vector}\left(\mathbf{u}_i\right)$ | $\text{scalar}\left(x_i\right)$ | |
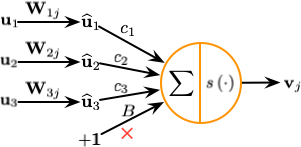
| Operration | Affine Transform | $\widehat{\mathbf{u}}_{j \mid i}=\mathbf{W}_{i j} \mathbf{u}_{i}$ | - |
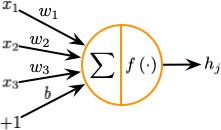
| Weighting | $\mathbf{s}_{j}=\sum_{i} c_{i j} \widehat{\mathbf{u}}_{j \mid i}$ | $a_{j}=\sum_{i} w_{i} x_{i}+b$ | |
| Sum | |||
| Nonlinear Activation | $\mathbf{v}_{j}=\dfrac{\left\|\mathbf{s}_{j}\right\|^{2}}{1+\left\|\mathbf{s}_{j}\right\|^{2}} \dfrac{\mathbf{s}_{j}}{\left\|\mathbf{s}_{j}\right\|}$ | $h_{j}=f\left(a_{j}\right)$ | |
| Output | $\text{vector}\left(\mathbf{v}_j\right)$ | $\text{scalar}\left(h_j\right)$ | |
 |
 |
||
人造神经元包含如下 3 个计算步骤:
- 输入标量的加权
- 加权标量的求和
- 求和标量到输出标量的非线性变换
胶囊可以理解为上述 3 个步骤的向量版,同时增加了对输入的仿射变换:
- 输入向量的矩阵乘法:胶囊接受的输入向量编码了低层胶囊检测出的相应对象的概率,向量的方向编码了检测出的对象的一些内部状态。接着将这些向量乘以相应的权重矩阵
$\mathbf{W}$,$\mathbf{W}$编码了低层特征(例如:眼睛、嘴巴和鼻子)和高层特征(例如:面部)之间的空间关系和其他重要关系。 - 向量的标量加权:这个步骤同人造神经元对应的步骤类似,但神经元的权重是通过反向传播学习的,而胶囊则使用动态路由。
- 加权向量的求和:这个步骤同人造神经元对应的步骤类似。
- 求和向量到输出向量的非线性变换:胶囊神经网络的非线性激活函数接受一个向量,然后在不改变方向的前提下,将其长度压缩到 1 以下。
动态路由
胶囊网络使用动态路由算法进行训练,算法过程如下 2:
\begin{algorithm}
\caption{Routing 算法}
\begin{algorithmic}
\PROCEDURE{Routing}{$\widehat{\mathbf{u}}_{j | i}, r, l$}
\STATE for all capsule $i$ in layer $l$ and capsule $j$ in layer $\left(l + 1\right)$: $b_{ij} \gets 0$
\FOR{$r$ iterations}
\STATE for all capsule $i$ in layer $l$: $\mathbf{c}_i \gets \text{softmax} \left(\mathbf{b}_i\right)$
\STATE for all capsule $j$ in layer $\left(l + 1\right)$: $\mathbf{s}_j \gets \sum_{i} c_{ij} \widehat{\mathbf{u}}_{j | i}$
\STATE for all capsule $j$ in layer $\left(l + 1\right)$: $\mathbf{v}_j \gets \text{squash} \left(\mathbf{s}_j\right)$
\STATE for all capsule $i$ in layer $l$ and capsule $j$ in layer $\left(l + 1\right)$: $b_{ij} \gets b_{ij} + \widehat{\mathbf{u}}_{j | i} \cdot \mathbf{v}_j$
\ENDFOR
\RETURN $\mathbf{v}_j$
\ENDPROCEDURE
\end{algorithmic}
\end{algorithm}
- 第 1 行表示算法的输入为:低层
$l$中所有胶囊的输出$\widehat{\mathbf{u}}$,以及路由迭代计数$r$。 - 第 2 行中的
$b_{ij}$为一个临时变量,其值在迭代过程中更新,算法运行完毕后其值被保存在$c_{ij}$中。 - 第 3 行表示如下步骤将会被重复
$r$次。 - 第 4 行利用
$\mathbf{b}_i$计算低层胶囊的权重向量$\mathbf{c}_i$。$\text{softmax}$确保了所有权重为非负数,且和为一。第一次迭代后,所有系数$c_{ij}$的值相等,随着算法的继续,这些均匀分布将发生改变。 - 第 5 行计算经前一步确定的路由系数
$c_{ij}$加权后的输入向量的线性组合。该步缩小输入向量并将他们相加,得到输出向量$\mathbf{s}_j$。 - 第 6 行对前一步的输出向量应用
$\text{squash}$非线性函数。这确保了向量的方向被保留下来,而长度被限制在 1 以下。 - 第 7 行通过观测低层和高层的胶囊,根据公式更新相应的权重
$b_{ij}$。胶囊$j$的当前输出与从低层胶囊$i$处接收到的输入进行点积,再加上旧的权重作为新的权重。点积检测胶囊输入和输出之间的相似性。 - 重复
$r$次,计算出所有高层胶囊的输出,并确立路由权重。之后正向传导就可以推进到更高层的网络。
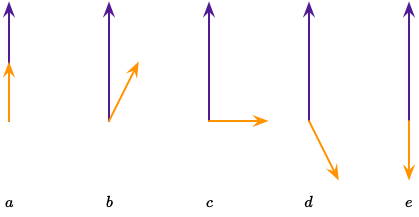
点积运算接收两个向量,并输出一个标量。对于给定长度但方向不同的两个向量而言,点积有几种情况:$a$ 最大正值;$b$ 正值;$c$ 零;$d$ 负值;$e$ 最小负值,如下图所示:
我们用紫色向量 $\mathbf{v}_1$ 和 $\mathbf{v}_2$ 表示高层胶囊,橙色向量表示低层胶囊的输入,其他黑色向量表示接收自其他低层胶囊的输入,如下图所示:
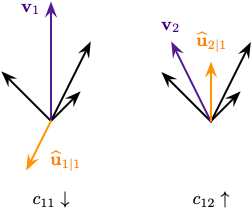
左侧的紫色输出 $\mathbf{v}_1$ 和橙色输入 $\widehat{\mathbf{u}}_{1|1}$ 指向相反的方向,这意味着他们的点积是一个负数,从而路由系数 $c_{11}$ 减少;右侧的紫色输出 $\mathbf{v}_2$ 和橙色输入 $\widehat{\mathbf{u}}_{2|1}$ 指向相同的方向,从而路由系数 $c_{12}$ 增加。在所有高层胶囊及其所有输入上重复该过程,得到一个路由系数集合,达成了来自低层胶囊的输出与高层胶囊的输出的最佳匹配。
网络架构
胶囊网络由 6 层神经网络构成,前 3 层是编码器,后 3 层是解码器:
- 卷积层
- PrimaryCaps(主胶囊)层
- DigitCaps(数字胶囊)层
- 第一全连接层
- 第二全连接层
- 第三全连接层
编码器
编码器部分如下图所示:
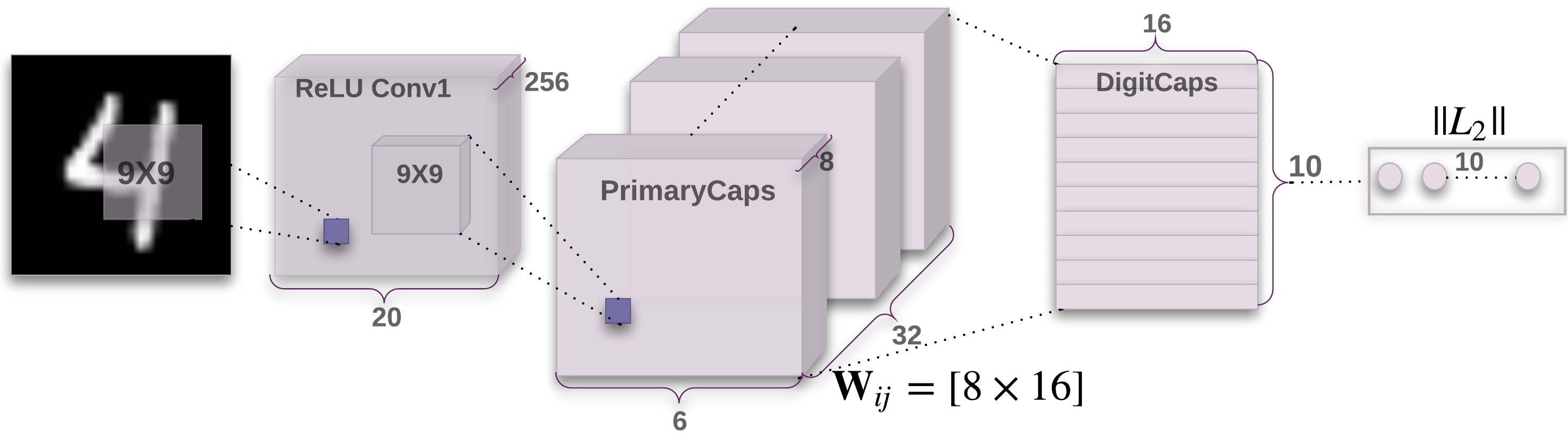
卷积层用于检测 2D 图像的基本特征。PrimaryCaps 层包含 32 个主胶囊,接收卷积层检测到的基本特征,生成特征的组合。DigitCaps 层包含 10 个数字胶囊,每个胶囊对应一个数字。
对于 $k$ 个类别的数字,我们希望最高层的胶囊当且仅当一个数字出现在图像中时具有一个长的实例化向量。为了允许多个数字,对于每个 DigitCap 使用一个独立的损失函数:
$$ L_{k}=T_{k} \max \left(0, m^{+}-\left\|\mathbf{v}_{k}\right\|\right)^{2}+\lambda\left(1-T_{k}\right) \max \left(0,\left\|\mathbf{v}_{k}\right\|-m^{-}\right)^{2} $$
DigitCaps 层的输出为 10 个 16 维的向量,根据上面的公式计算每个向量的损失值,然后将 10 个损失值相加得到最终损失。
在损失函数中,当正确的标签与特定 DigitCap 的数字对应时 $T_k$ 为 1,否则为 0。加号前一项用于计算正确 DigitCap 的损失,当概率值大于 $m^{+} = 0.9$ 时为 0,当概率值小于 $m^{+} = 0.9$ 时为非零值;加号后一项用于计算错误 DigitCap 的损失,当概率值小于 $m^{-} = 0.1$ 时值为 0,当概率值大于 $m^{-} = 0.1$ 时为非零值。公式中的 $\lambda = 0.5$ 用于确保训练中数值的稳定性。
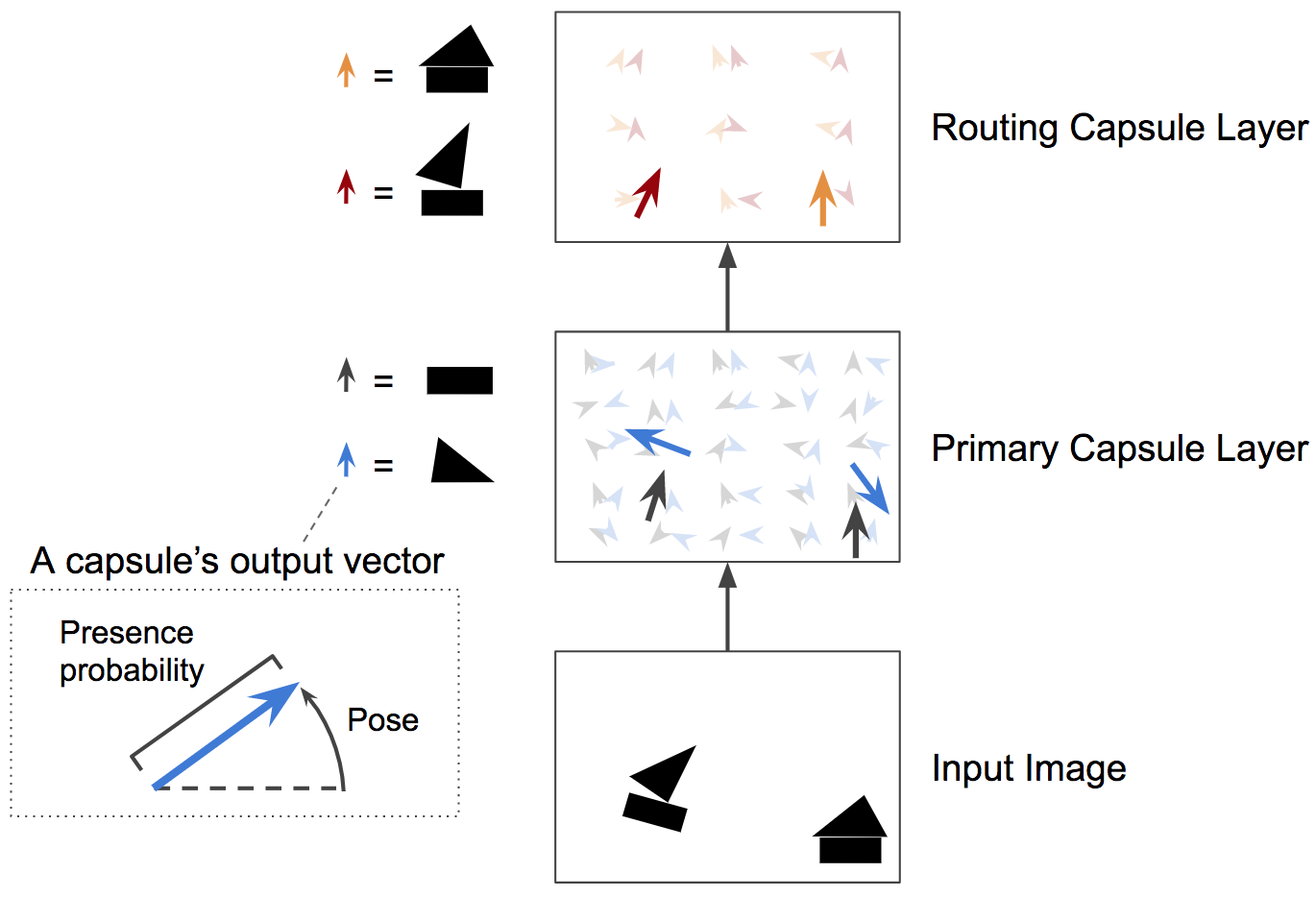
简单来说,低层的胶囊用于检测一些特定模式的出现概率和姿态,高层的胶囊用于检测更加复杂的图像,如下图所示:
解码器
解码器部分如下图所示:
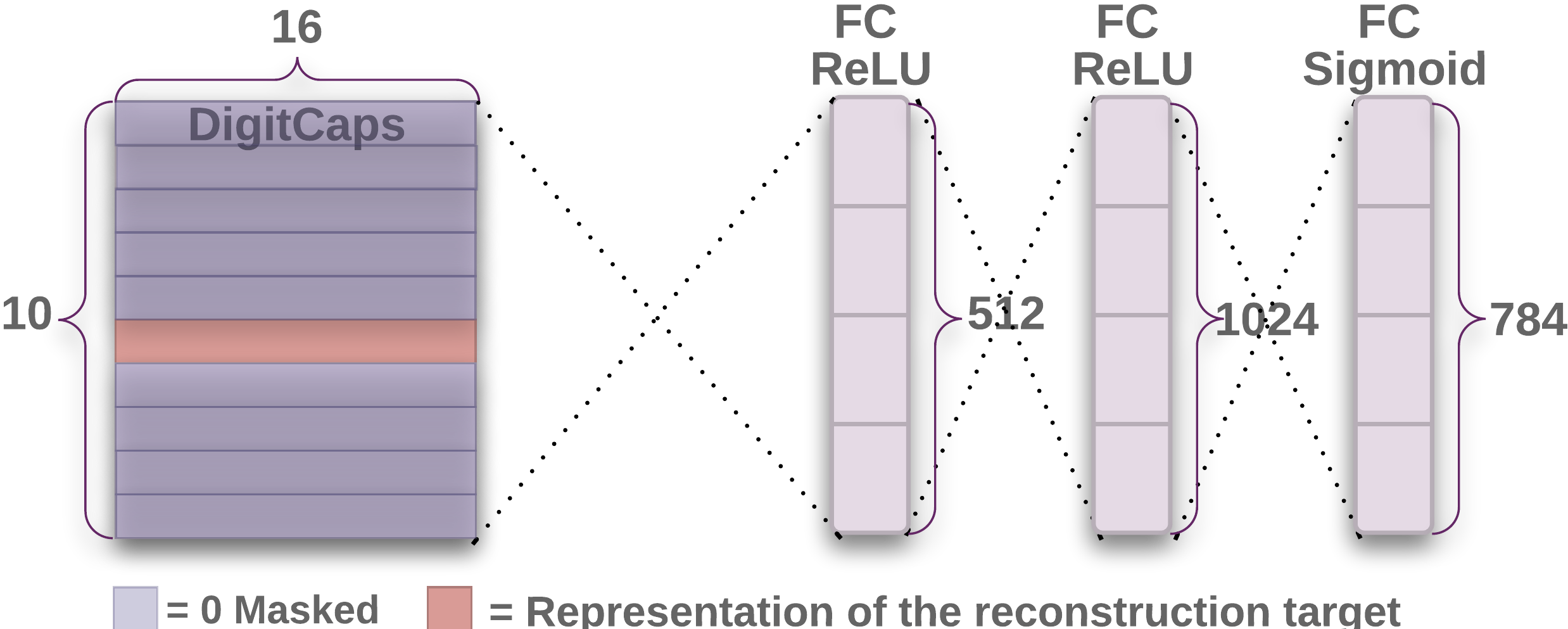
解码器从正确的 DigitCap 中接收一个 16 维向量,并学习将其解码为数字图像。解码器接收正确的 DigitCap 的输出作为输入,并学习重建一张 $28 \times 28$ 像素的图像,损失函数为重建图像与输入图像之间的欧式距离。
-
Hinton, G. E., Krizhevsky, A., & Wang, S. D. (2011, June). Transforming auto-encoders. In International conference on artificial neural networks (pp. 44-51). Springer, Berlin, Heidelberg. ↩︎
-
Sabour, S., Frosst, N., & Hinton, G. E. (2017, December). Dynamic routing between capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems (pp. 3859-3869). ↩︎