在之前的博客「投票公平合理吗?」中已经得到了一个令人沮丧的结论:只有道德上的相对民主,没有制度上的绝对公平。投票是对不同选项或个体的排序,在投票中我们关注更多是相对位置这样定性的结论,例如:积分前三名的同学才能进入下一环节。但有的时候我们不光想知道不同选项之间的先后顺序,还想了解不同选项之间的差异大小,这时我们就需要设计更精细的方法进行定量分析。
基础评分和排名
直接评分
从小到大被评分最多的应该就是考试了,100,120 或是 150,这三个数字应该从小学一年级一直“陪”我们走过十几载青春。考试的评分算法简单且容易区分,整个系统设置了一个总分,根据不同的表现进行加分或扣分,统计最终得分作为最后的评分。一般情况下成绩是一个近似正态分布的偏态分布,如下图所示。
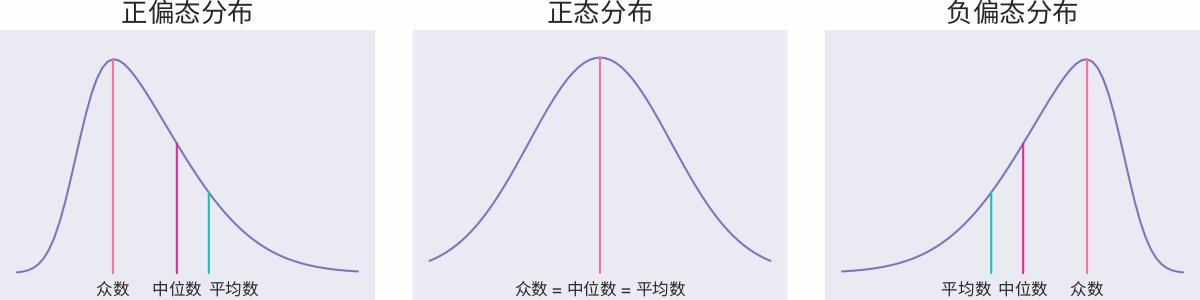
如果成绩近似正态分布(如上图-中),则说明本次考试难度分布较为均衡;如果成绩分布整体向左偏(如上图-左),则说明本次考试较为困难,学生成绩普遍偏低;如果成绩分布整体向右偏(如上图-右),则说明本次考试较为容易,学生成绩普遍偏高。
除此之外,也可能出现双峰分布,以及峰的陡峭和平缓都能反应考试的不同问题,在此就不再一一展开说明。一般情况下,考试的最终成绩已经能够很好地对学生的能力进行区分,这也正是为什么一般情况我们不会对考试分数做二次处理,而是直接使用。
加权评分
在现实生活中,不同的问题和任务难易程度不同,为了保证「公平」,我们需要赋予困难的任务更多的分数。这一点在试卷中也会有体现,一般而言判断题会比选择题分数更低,毕竟随机作答,判断题仍有 50% 的概率回答正确,但包含四个选项的选择题却仅有 25% 概率回答正确。
加权评分在问题和任务的难易程度与分值之间通过权重进行平衡,但权重的制定并不是一个容易的过程,尤其是在设置一个兼顾客观、公平、合理等多维度的权重时。
考虑时间的评分和排名
Delicious
最简单直接的方法是在一定的时间内统计投票的数量,得票数量高的则为更好的项目。在旧版的 Delicious 中,热门书签排行榜则是根据过去 60 分钟内被收藏的次数进行排名,每 60 分钟重新统计一次。

这种算法的优点是:简单、容易部署、更新快;缺点是:一方面,排名变化不够平滑,前一个小时还排名靠前的内容,往往第二个小时就一落千丈,另一方面,缺乏自动淘汰旧项目的机制,某些热门内容可能会长期占据排行榜前列。
Hacker News
Hacker News 是一个可以发布帖子的网络社区,每个帖子前面有一个向上的三角形,如果用户觉得这个内容好,点击一下即可投票。根据得票数,系统自动统计出热门文章排行榜。
Hacker News 使用分数计算公式如下:
$$ Score = \dfrac{P - 1}{\left(T + 2\right)^G} \label{eq:hacker-news} $$
其中,$P$ 表示帖子的得票数,减去 $1$ 表示忽略发帖人的投票;$T$ 表示当前距离发帖的时间(单位为小时),加上 $2$ 是为了防止最新的帖子分母过小;$G$ 为重力因子,即将帖子排名被往下拉的力量,默认值为 $1.8$。
在其他条件不变的情况下,更多的票数可以获得更高的分数,如果不希望“高票数”帖子和“低票数”帖子之间差距过大,可以在式 $\ref{eq:hacker-news}$ 的分子中添加小于 $1$ 的指数,例如:$\left(P - 1\right)^{0.8}$。在其他条件不变的情况下,随着时间不断流逝,帖子的分数会不断降低,经过 24 小时后,几乎所有帖子的分数都将小于 $1$。重力因子对于分数的影响如下图所示:
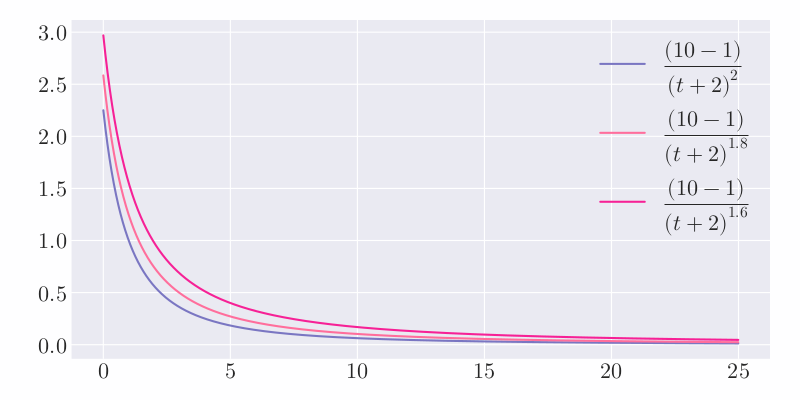
不难看出,$G$ 值越大,曲线越陡峭,排名下降的速度越快,意味着排行榜的更新速度越快。
不同于 Hacker News,Reddit 中的每个帖子前面都有向上和向下的箭头,分别表示"赞成"和"反对"。用户点击进行投票,Reddit 根据投票结果,计算出最新的热点文章排行榜。
Reddit 关于计算分数的代码可以简要总结如下:
from datetime import datetime, timedelta
from math import log
epoch = datetime(1970, 1, 1)
def epoch_seconds(date):
td = date - epoch
return td.days * 86400 + td.seconds + (float(td.microseconds) / 1000000)
def score(ups, downs):
return ups - downs
def hot(ups, downs, date):
s = score(ups, downs)
order = log(max(abs(s), 1), 10)
sign = 1 if s > 0 else -1 if s < 0 else 0
seconds = epoch_seconds(date) - 1134028003
return round(order + sign * seconds / 45000, 7)
分数的计算过程大致如下:
- 计算赞成票和反对票的差值,即:
$$ s = ups - downs $$ - 利用如下公式计算中间分数,即:
$$ order = \log_{10} \max\left(\left|s\right|, 1\right) $$其中,取 $\left|s\right|$ 和 $1$ 的最大值是为了避免当 $s = 0$ 时,无法计算 $\log_{10}{\left|s\right|}$。赞成票与反对票差值越大,得分越高。取以 $10$ 为底的对数,表示当 $s = 10$ 时,这部分为 $1$,只有 $s = 100$ 时才为 $2$,这样设置是为了减缓差值增加对总分的影响程度。 - 确定分数的方向,即:
$$ sign = \begin{cases} 1 & \text{如果} \ s > 0 \\ 0 & \text{如果} \ s = 0 \\ -1 & \text{如果} \ s < 0 \end{cases} $$ - 计算发贴时间距离 2005 年 12 月 8 日 7:46:43(Reddit 的成立时间?)的秒数,即:
$$ seconds = \text{timestamp}\left(date\right) - 1134028003 $$ - 计算最终分数,即:
$$ score = order + sign \times \dfrac{seconds}{45000} $$将时间除以 $45000$ 秒(即 12.5 个小时),也就是说当前天的帖子会比昨天的帖子多约 $2$ 分。如果昨天的帖子想要保持住之前的排名,则 $s$ 值需要增加 $100$ 倍才可以。
Reddit 评分排名算法决定了 Reddit 是一个符合大众口味的社区,而不是一个适合展示激进想法的地方。因为评分中使用的是赞成票和反对票的差值,也就是说在其他条件相同的情况下,帖子 A 有 1 票赞成,0 票反对;帖子 B 有 1000 票赞成,1000 票反对,但讨论火热的帖子 B 的得分却比 帖子 A 要少。
Stack Overflow
Stack Overflow 是世界排名第一的程序员问答社区。用户可以在上面提出各种关于编程的问题,等待别人回答;可以对问题进行投票(赞成票或反对票),表示这个问题是不是有价值;也可以对这个回答投票(赞成票或反对票),表示这个回答是不是有价值。
在 Stack Overflow 的页面上,每个问题前面有三个数字,分别为问题的得分、回答的数量和问题的浏览次数。
创始人之一的 Jeff Atwood 公布的评分排名的计算公式如下:
$$ \dfrac{4 \times \log_{10}{Q_{views}} + \dfrac{Q_{answers} \times Q_{score}}{5} + \sum \left(A_{scores}\right)}{\left(\left(Q_{age} + 1\right) - \left(\dfrac{Q_{age} - Q_{updated}}{2}\right)\right)^{1.5}} $$
其中:
$4 \times \log_{10}{Q_{views}}$表示问题的浏览次数越多,得分越高,同时利用$\log_{10}$减缓了随着浏览量增大导致得分变高的程度。$\dfrac{Q_{answers} \times Q_{score}}{5}$表示问题的得分(赞成票和反对票之差)越高,回答的数量越多,分数越高。采用乘积的形式意味着即使问题本身的分数再高,没有人回答的问题也算不上热门问题。$\sum \left(A_{scores}\right)$表示问题回答的总分数。回答总分采用了简单的加和,但实际上一个正确的回答要胜过多个无用的回答,简答的加和无法很好的区分这两种不同的情况。$\left(\left(Q_{age} + 1\right) - \left(\dfrac{Q_{age} - Q_{updated}}{2}\right)\right)^{1.5}$可以改写为$\left(\dfrac{Q_{age}}{2} + \dfrac{Q_{updated}}{2} + 1\right)^{1.5}$,$Q_{age}$和$Q_{updated}$分别表示问题和最近一次回答的时间(单位为小时),也就是说问题时间越久远,最近一次回答时间约久远,分母就会越大,从而得分就会越小。
Stack Overflow 的评分排名算法考虑了参与程度(问题浏览次数和回答次数)、质量(问题分数和回答分数)、时间(问题时间和最近一次回答时间)等多个维度。
不考虑时间的评分和排名
上文中介绍的评分和排名方法多适用于具有时效性的信息,但是对于图书、电影等无需考虑时间因素的情况而言,则需要其他方法进行衡量。
威尔逊区间算法
在不考虑时间的情况下,以「赞成」和「反对」两种评价方式为例,通常我们会有两种最基础的方法计算得分。第一种为绝对分数,即:
$$ \text{评分} = \text{赞成票} - \text{反对票} $$
但这种计算方式有时会存在一定问题,例如:A 获得 60 张赞成票,40 张反对票;B 获得 550 张赞成票,450 张反对票。根据上式计算可得 A 的评分为 20,B 的评分为 100,所以 B 要优于 A。但实际上,B 的好评率仅有 $\dfrac{550}{550 + 450} = 55\%$,而 A 的好评率为 $\dfrac{60}{60 + 40} = 60\%$,因此实际情况应该是 A 优于 B。
这样,我们就得到了第二种相对分数,即:
$$ \text{评分} = \dfrac{\text{赞成票}}{\text{赞成票} + \text{反对票}} $$
这种方式在总票数比较大的时候没有问题,但总票数比较小时就容易产生错误。例如:A 获得 2 张赞成票,0 张反对票;B 获得 100 张赞成票,1 张反对票。根据上式计算可得 A 的评分为 $100\%$,B 的评分为 $99\%$。但实际上 B 应该是优于 A 的,由于 A 的总票数太少,数据不太具有统计意义。
对于这个问题,我们可以抽象出来:
- 每个用户的投票都是独立事件。
- 用户只有两个选择,要么投赞成票,要么投反对票。
- 如果投票总人数为
$n$,其中赞成票为$k$,则赞成票的比例$p = \dfrac{k}{n}$。
不难看出,上述过程是一个二项实验。$p$ 越大表示评分越高,但是 $p$ 的可信性取决于投票的人数,如果人数太少,$p$ 就不可信了。因此我们可以通过计算 $p$ 的置信区间对评分算法进行调整如下:
- 计算每个项目的好评率。
- 计算每个好评率的置信区间。
- 根据置信区间的下限值进行排名。
置信区间的本质就是对可信度进行修正,弥补样本量过小的影响。如果样本足够多,就说明比较可信,则不需要很大的修正,所以置信区间会比较窄,下限值会比较大;如果样本比较少,就说明不一定可信,则需要进行较大的修正,所以置信区间会比较宽,下限值会比较小。
二项分布的置信区间有多种计算公式,最常见的「正态区间」方法对于小样本准确性较差。1927 年,美国数学家 Edwin Bidwell Wilson 提出了一个修正公式,被称为「威尔逊区间」,很好地解决了小样本的准确性问题。置信区间定义如下:
$$ \frac{1}{1+\frac{z^{2}}{n}}\left(\hat{p}+\frac{z^{2}}{2 n}\right) \pm \frac{z}{1+\frac{z^{2}}{n}} \sqrt{\frac{\hat{p}(1-\hat{p})}{n}+\frac{z^{2}}{4 n^{2}}} $$
其中,$\hat{p}$ 表示样本好评率,$n$ 表示样本大小,$z$ 表示某个置信水平的 z 统计量。
贝叶斯平均算法
在一些榜单中,有时候会出现排行榜前列总是那些票数最多的项目,新项目或者冷门的项目很难有出头机会,排名可能会长期靠后。以世界最大的电影数据库 IMDB 为例,观众可以对每部电影投票,最低为 1 分,最高为 10 分,系统根据投票结果,计算出每部电影的平均得分。
这就出现了一个问题:热门电影与冷门电影的平均得分,是否真的可比?例如一部好莱坞大片有 10000 个观众投票,一部小成本的文艺片可能只有 100 个观众投票。如果使用威尔逊区间算法,后者的得分将被大幅拉低,这样处理是否公平,是否能反映电影的真正质量呢?在 Top 250 榜单中,IMDB 给到的评分排名计算公式如下:
$$ WR = \dfrac{v}{v + m} R + \dfrac{m}{v + m} C $$
其中,$WR$ 为最终的加权得分,$R$ 为该电影用户投票的平均得分,$v$ 为该电影的投票人数,$m$ 为排名前 250 电影的最低投票数,$C$ 为所有电影的平均得分。
从公式中可以看出,分量 $m C$ 可以看作为每部电影增加了评分为 $C$ 的 $m$ 张选票。然后再根据电影自己的投票数量 $v$ 和投票平均分 $R$ 进行修正,得到最终的分数。随着电影投票数量的不但增加 $\dfrac{v}{v + m} R$ 占的比重将越来越大,加权得分也会越来越接近该电影用户投票的平均分。
将公式写为更一般的形式,有:
$$ \bar{x}=\frac{C m+\sum_{i=1}^{n} x_{i}}{C+n} $$
其中,$C$ 为需要扩充的投票人数规模,可以根据投票人数总量设置一个合理的常数,$n$ 为当前项目的投票人数,$x$ 为每张选票的值,$m$ 为总体的平均分。这种算法称为「贝叶斯平均」。在这个公式中,$m$ 可以视为“先验概率”,每新增一次投票,都会对最终得分进行修正,使其越来越接近真实的值。
比赛评分和排名
Kaggle 积分
Kaggle 是一个数据建模和数据分析竞赛平台。企业和研究者可在其上发布数据,统计学者和数据挖掘专家可在其上进行竞赛以产生最好的模型。用户以团队形式参加 Kaggle 的比赛,团队可以仅包含自己一人,根据在每场比赛中的排名不断获取积分,用做 Kaggle 网站中的最终排名。
早期 Kaggle 对于每场比赛的积分按如下方式计算:
$$ \left[\dfrac{100000}{N_{\text {teammates }}}\right]\left[\text{Rank}^{-0.75}\right]\left[\log _{10}\left(N_{\text {teams }}\right)\right]\left[\dfrac{2 \text { years - time }}{2 \text { years }}\right] $$
在 2015 年对新的排名系统做了调整,新的比赛积分计算公式调整为:
$$ \left[\dfrac{100000}{\sqrt{N_{\text {teammates }}}}\right]\left[\text{Rank}^{-0.75}\right]\left[\log _{10}\left(1+\log _{10}\left(N_{\text {teams }}\right)\right)\right]\left[e^{-t / 500}\right] $$
其中,$N_{\text{teammates}}$ 为团队成员的数量,$\text{Rank}$ 为比赛排名,$N_{\text{teams}}$ 为参赛的团队数量,$t$ 为从比赛结束之日起过去的时间。
第一部分可以视为基础分,团队成员越少,所获得的基础分越多。从调整的文档来看,Kaggle 认为团队合作每个人的贡献程度会大于 $1 / N_{\text {teammates}}$,为了鼓励大家团队合作,Kaggle 减少了对团队人数的基础分惩罚力度。
第二部分则是根据用户在比赛中的排名得到一个小于等于 1 的系数。下图显示了不同的指数以及 $1 / \text{Rank}$ 之间的区别:
![]()
从图中可以看出,通过调节指数的大小可以控制系数随排名下降而下降的速度。整体来说,Kaggle 更加重视前几名,对于 10 名开外的选手,系数均小于 $0.2$,且差异不大。
第三部分可以理解为通过参赛的队伍数量来衡量比赛的受欢迎程度(或是在众多参赛队伍中脱颖而出的难易程度)。以 100 和 1000 支参赛队伍对比为例,根据之前的计算公式,这一部分为:
$$ \begin{equation} \begin{aligned} \log_{10} \left(100\right) &= 2 \\ \log_{10} \left(1000\right) &= 3 \end{aligned} \end{equation} $$
但随着 Kaggle 本身比赛流行度越来越高,官方认为赢得一场 1000 人的比赛并不需要比赢得一场 100 人的比赛需要多 $50\%$ 的技能,因此通过调整后的算法,这个比例调整至大约为 $25\%$。
$$ \begin{equation} \begin{aligned} \log_{10} \left(\log_{10} \left(100\right) + 1\right) &\approx 0.47 \\ \log_{10} \left(\log_{10} \left(1000\right) + 1\right) &\approx 0.6 \end{aligned} \end{equation} $$
第四部份为时间衰减项,调整为新的计算公式后可以消除原来通过设置 2 年时限导致的积分断崖。如果任何一对个体都没有采取任何进一步的行动,那么排名不应该在任何一对个体之间发生变化。换句话说,如果整个 Kaggle 用户群停止参加比赛,他们的相对排名应该随着时间的推移保持不变。选择 $1 / 500$ 的原因是可以将旧的 2 年断崖延长到更长的时间范围,并且永远不会变为 0。
Elo 评分系统
Elo 评分系统(Elo Rating System)是由匈牙利裔美国物理学家 Arpad Elo 创建的一个衡量各类对弈活动水平的评价方法,是当今对弈水平评估公认的权威标准,且被广泛用于国际象棋、围棋、足球、篮球等运动。网络游戏的竞技对战系统也常采用此评分系统。
Elo 评分系统是基于统计学的一个评估棋手水平的方法。Elo 模型原先采用正态分布,但实践显明棋手的表现并非正态分布,所以现在的评分计分系统通常使用的是逻辑分布。
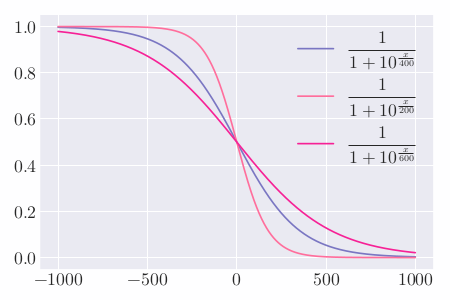
假设棋手 A 和 B 的当前评分分别为 $R_A$ 和 $R_B$,则按照逻辑分布,A 对 B 的胜率期望值为:
$$ E_{A}=\frac{1}{1+10^{\left(R_{B}-R_{A}\right) / 400}} $$
类似的有 B 对 A 的胜率期望值为:
$$ E_{B}=\frac{1}{1+10^{\left(R_{A}-R_{B}\right) / 400}} $$
假如一位棋手在比赛中的真实得分 $S_{A}$(胜 1 分,和 0.5 分,负 0 分)和他的胜率期望值 $E_{A}$ 不同,则他的评分要作相应的调整:
$$ R_{A}^{\prime} = R_{A} + K\left(S_{A}-E_{A}\right) $$
公式中 $R_{A}$ 和 $R_{A}^{\prime }$ 分别为棋手调整前后的评分。$K$ 值是一个极限值,代表理论上最多可以赢一个玩家的得分和失分,$K / 2$ 就是相同等级的玩家其中一方胜利后所得的分数。国际象棋大师赛中,$K = 16$;在大部分的游戏规则中,$K = 32$。通常水平越高的比赛中其 $K$ 值越小,这样做是为了避免少数的几场比赛就能改变高端顶尖玩家的排名。$E_A$ 和 $E_B$ 中的 $400$ 是让多数玩家积分保持标准正态分布的值,在 $K$ 相同的情况下,分母位置的值越大,积分变化值越小。
Glicko 评分系统
Glicko 评分系统(Glicko Rating System)及 Glicko-2 评分系统(Glicko-2 Rating System)是评估选手在比赛中(如国际象棋及围棋)的技术能力方法之一。此方法由马克·格利克曼发明,原为国际象棋评分系统打造,后作为评分评分系统的改进版本广泛应用 1。
Elo 评分系统的问题在于无法确定选手评分的可信度,而 Glicko 评分系统正是针对此进行改进。假设两名评分均为 1700 的选手 A 和 B 在进行一场对战后 A 获得胜利,在美国国际象棋联赛的 Elo 评分系统下,A 选手评分将增长 16,对应的 B 选手评分将下降 16。但是假如 A 选手是已经很久没玩,但 B 选手每周都会玩,那么在上述情况下 A 选手的 1700 评分并不能十分可信地用于评定其实力,而 B 选手的 1700 评分则更为可信。
Glicko 算法的主要贡献是“评分可靠性”(Ratings Reliability),即评分偏差(Ratings Deviation)。若选手没有评分,则其评分通常被设为 1500,评分偏差为 350。新的评分偏差($RD$)可使用旧的评分偏差($RD_0$)计算:
$$ RD = \min \left(\sqrt{RD_0^2 + c^2 t}, 350\right) $$
其中,$t$ 为自上次比赛至现在的时间长度(评分期),常数 $c$ 根据选手在特定时间段内的技术不确定性计算而来,计算方法可以通过数据分析,或是估算选手的评分偏差将在什么时候达到未评分选手的评分偏差得来。若一名选手的评分偏差将在 100 个评分期间内达到 350 的不确定度,则评分偏差为 50 的玩家的常数 $c$ 可通过解 $350 = \sqrt{50^2 + 100 c^2}$,则有 $c = \sqrt{\left(350^2 - 50^2\right) / 100} \approx 34.6$。
在经过 $m$ 场比赛后,选手的新评分可通过下列等式计算:
$$ r=r_{0}+\frac{q}{\frac{1}{R D^{2}}+\frac{1}{d^{2}}} \sum_{i=1}^{m} g\left(R D_{i}\right)\left(s_{i}-E\left(s \mid r_{0}, r_{i}, R D_{i}\right)\right) $$
其中:
$$ \begin{equation*} \begin{aligned} & g\left(R D_{i}\right) = \frac{1}{\sqrt{1+\frac{3 q^{2}\left(R D_{i}^{2}\right)}{\pi^{2}}}} \\ & E\left(s \mid r, r_{i}, R D_{i}\right) = \frac{1}{1+10\left(\frac{g\left(R D_{i}\right)\left(r_{0}-r_{i}\right)}{-400}\right)} \\ & q = \frac{\ln (10)}{400}=0.00575646273 \\ & d^{2} = \frac{1}{q^{2} \sum_{i=1}^{m}\left(g\left(R D_{i}\right)\right)^{2} E\left(s \mid r_{0}, r_{i}, R D_{i}\right)\left(1-E\left(s \mid r_{0}, r_{i}, R D_{i}\right)\right)} \end{aligned} \end{equation*} $$
$r_i$ 表示选手个人评分,$s_i$ 表示每场比赛后的结果。胜利为 $1$,平局为 $1 / 2$,失败为 $0$。
原先用于计算评分偏差的函数应增大标准差值,进而反应模型中一定非观察时间内,玩家的技术不确定性的增长。随后,评分偏差将在几场游戏后更新:
$$ R D^{\prime}=\sqrt{\left(\frac{1}{R D^{2}}+\frac{1}{d^{2}}\right)^{-1}} $$
Glicko-2 评分系统
Glicko-2 算法与原始 Glicko 算法类似,增加了一个评分波动率 $\sigma$,它根据玩家表现的不稳定程度来衡量玩家评分的预期波动程度。例如:当一名球员的表现保持稳定时,他们的评分波动性会很低,如果他们在这段稳定期之后取得了异常强劲的成绩,那么他们的评分波动性就会增加 1。
Glicko-2 算法的简要步骤如下:
计算辅助量
在一个评分周期内,当前评分为 $\mu$ 和评分偏差为 $\phi$ 的玩家与 $m$ 个评分为 $\mu_1, \cdots, \mu_m$ 和评分偏差为 $\phi_1, \cdots, \phi_m$ 的玩家比赛,获得的分数为 $s_1, \cdots, s_m$,我们首先需要计算辅助量 $v$ 和 $\Delta$:
$$ \begin{aligned} v &= \left[\sum_{j=1}^{m} g\left(\phi_{j}\right)^{2} E\left(\mu, \mu_{j}, \phi_{j}\right)\left\{s_{j}-E\left(\mu, \mu_{j}, \phi_{j}\right)\right\}\right]^{-1} \\ \Delta &= v \sum_{j=1}^{m} g\left(\phi_{j}\right)\left\{s_{j}-E\left(\mu, \mu_{j}, \phi_{j}\right)\right\} \end{aligned} $$
其中:
$$ \begin{equation*} \begin{aligned} &g(\phi)=\frac{1}{\sqrt{1+3 \phi^{2} / \pi^{2}}}, \\ &E\left(\mu, \mu_{j}, \phi_{j}\right)=\frac{1}{1+\exp \left\{-g\left(\phi_{j}\right)\left(\mu-\mu_{j}\right)\right\}} \end{aligned} \end{equation*} $$
确定新的评分波动率
选择一个小的常数 $\tau$ 来限制时间的波动性,例如:$\tau = 0.2$(较小的 $\tau$ 值可以防止剧烈的评分变化),对于:
$$ f(x)=\frac{1}{2} \frac{e^{x}\left(\Delta^{2}-\phi^{2}-v^{2}-e^{x}\right)}{\left(\phi^{2}+v+e^{x}\right)^{2}}-\frac{x-\ln \left(\sigma^{2}\right)}{\tau^{2}} $$
我们需要找到满足 $f\left(A\right) = 0$ 的值 $A$。解决此问题的一种有效方法是使用 Illinois 算法,一旦这个迭代过程完成,我们将新的评级波动率 $\sigma'$ 设置为:
$$ \sigma' = e^{\frac{A}{2}} $$
确定新的评分偏差和评分
之后得到新的评分偏差:
$$ \phi^{\prime} = \dfrac{1}{\sqrt{\dfrac{1}{\phi^{2}+\sigma^{\prime 2}}+\dfrac{1}{v}}} $$
和新的评分:
$$ \mu^{\prime} = \mu+\phi^{\prime 2} \sum_{j=1}^{m} g\left(\phi_{j}\right)\left\{s_{j}-E\left(\mu, \mu_{j}, \phi_{j}\right)\right\} $$
需要注意这里的评分和评分偏差与原始 Glicko 算法的比例不同,需要进行转换才能正确比较两者。
TrueSkill 评分系统
TrueSkill 评分系统是基于贝叶斯推断的评分系统,由微软研究院开发以代替传统 Elo 评分系统,并成功应用于 Xbox Live 自动匹配系统。TrueSkill 评分系统是 Glicko 评分系统的衍伸,主要用于多人游戏中。TrueSkill 评分系统考虑到了个别玩家水平的不确定性,综合考虑了各玩家的胜率和可能的水平涨落。当各玩家进行了更多的游戏后,即使个别玩家的胜率不变,系统也会因为对个别玩家的水平更加了解而改变对玩家的评分 2。
在电子竞技游戏中,特别是当有多名选手参加比赛的时候需要平衡队伍间的水平,让游戏比赛更加有意思。这样的一个参赛选手能力平衡系统通常包含以下三个模块:
- 一个包含跟踪所有玩家比赛结果,记录玩家能力的模块。
- 一个对比赛成员进行配对的模块。
- 一个公布比赛中各成员能力的模块。
能力计算和更新
TrueSkill 评分系统是针对玩家能力进行设计的,以克服现有排名系统的局限性,确保比赛双方的公平性,可以在联赛中作为排名系统使用。TrueSkill 评分系统假设玩家的水平可以用一个正态分布来表示,而正态分布可以用两个参数:平均值和方差来完全描述。设 Rank 值为 $R$,代表玩家水平的正态分布的两个参数平均值和方差分别为 $\mu$ 和 $\sigma$,则系统对玩家的评分即 Rank 值为:
$$ R = \mu - k \times \sigma $$
其中,$k$ 值越大则系统的评分越保守。
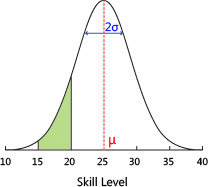
上图来自 TrueSkill 网站,钟型曲线为某个玩家水平的可能分布,绿色区域是排名系统的信念,即玩家的技能在 15 到 20 级之间。
下表格给出了 8 个新手在参与一个 8 人游戏后 $\mu$ 和 $\sigma$ 的变化。
| 姓名 | 排名 | 赛前 $\mu$ |
赛前 $\sigma$ |
赛后 $\mu$ |
赛后 $\sigma$ |
|---|---|---|---|---|---|
| Alice | 1 | 25 | 8.3 | 36.771 | 5.749 |
| Bob | 2 | 25 | 8.3 | 32.242 | 5.133 |
| Chris | 3 | 25 | 8.3 | 29.074 | 4.943 |
| Darren | 4 | 25 | 8.3 | 26.322 | 4.874 |
| Eve | 5 | 25 | 8.3 | 23.678 | 4.874 |
| Fabien | 6 | 25 | 8.3 | 20.926 | 4.943 |
| George | 7 | 25 | 8.3 | 17.758 | 5.133 |
| Hillary | 8 | 25 | 8.3 | 13.229 | 5.749 |
第 4 名 Darren 和第 5 名 Eve,他们的 $\sigma$ 是最小的,换句话说系统认为他们能力的可能起伏是最小的。这是因为通过这场游戏我们对他们了解得最多:他们赢了3 和 4 个人,也输给了 4 和 3 个人。而对于第 1 名 Alice,我们只知道她赢了 7 个人。
定量分析可以先考虑最简单的两人游戏情况:
$$ \begin{aligned} &\mu_{\text {winner }} \longleftarrow \mu_{\text {winner }}+\frac{\sigma_{\text {winner }}^{2}}{c} * v\left(\frac{\mu_{\text {winner }}-\mu_{\text {loser }}}{c}, \frac{\varepsilon}{c}\right) \\ &\mu_{\text {loser }} \longleftarrow \mu_{\text {loser }}-\frac{\sigma_{\text {loser }}^{2}}{c} * v\left(\frac{\mu_{\text {winner }}-\mu_{\text {loser }}}{c}, \frac{\varepsilon}{c}\right) \\ &\sigma_{\text {winner }}^{2} \longleftarrow \sigma_{\text {uninner }}^{2} *\left[1-\frac{\sigma_{\text {winner }}^{2}}{c} * w\left(\frac{\mu_{\text {winner }}-\mu_{\text {loser }}}{c}, \frac{\varepsilon}{c}\right)\right. \\ &\sigma_{\text {loser }}^{2} \longleftarrow \sigma_{\text {loser }}^{2} *\left[1-\frac{\sigma_{\text {loser }}^{2}}{c} * w\left(\frac{\mu_{\text {winner }}-\mu_{\text {loser }}}{c}, \frac{\varepsilon}{c}\right)\right. \\ &c^{2}=2 \beta^{2}+\sigma_{\text {winner }}^{2}+\sigma_{\text {loser }}^{2} \end{aligned} $$
其中,系数 $\beta^2$ 代表的是所有玩家的平均方差,$v$ 和 $w$ 是两个函数,比较复杂,$\epsilon$ 是平局参数。简而言之,个别玩家赢了 $\mu$ 就增加,输了 $\mu$ 减小;但不论输赢,$\sigma$ 都是在减小,所以有可能出现输了涨分的情况。
对手匹配
势均力敌的对手能带来最精彩的比赛,所以当自动匹配对手时,系统会尽可能地为个别玩家安排可能水平最为接近的对手。TrueSkill 评分系统采用了一个值域为 $(0, 1)$ 的函数来描述两个人是否势均力敌:结果越接近 0 代表差距越大,越接近 1 代表水平越接近。
假设有两个玩家 A 和 B,他们的参数为 $(\mu_A, \sigma_A)$ 和 $(\mu_B, \sigma_B)$,则函数对这两个玩家的返回值为:
$$ e^{-\frac{\left(\mu_{A}-\mu_{B}\right)^{2}}{2 c^{2}}} \sqrt{\frac{2 \beta^{2}}{c^{2}}} $$
$c$ 的值由如下公式给出:
$$ c^{2}=2 \beta^{2}+\mu_{A}^{2}+\mu_{B}^{2} $$
如果两人有较大几率被匹配在一起,仅是平均值接近还不行,还需要方差也比较接近才可以。
在 Xbox Live 上,系统为每个玩家赋予的初值是 $\mu = 25$,$\sigma = \dfrac{25}{3}$ 和 $k = 3$。所以玩家的起始 Rank 值为:
$$ R=25-3 \frac{25}{3}=0 $$
相较 Elo 评价系统,TrueSkill 评价系统的优势在于:
- 适用于复杂的组队形式,更具一般性。
- 有更完善的建模体系,容易扩展。
- 继承了贝叶斯建模的优点,如模型选择等。
本文主要参考了阮一峰的系列文章「基于用户投票的排名算法」和钱魏的「游戏排名算法:Elo、Glicko、TrueSkill」。