隐马尔可夫
隐马尔可夫模型(Hidden Markov Model,HMM)是一个描述包含隐含未知参数的马尔可夫过程的统计模型。马尔可夫过程(Markov Process)是因俄国数学家安德雷·安德耶维齐·马尔可夫(Андрей Андреевич Марков)而得名一个随机过程,在该随机过程中,给定当前状态和过去所有状态的条件下,其下一个状态的条件概率分布仅依赖于当前状态,通常具备离散状态的马尔可夫过程称之为马尔可夫链(Markov Chain)。因此,马尔可夫链可以理解为一个有限状态机,给定了当前状态为 $S_i$ 时,下一时刻状态为 $S_j$ 的概率,不同状态之间变换的概率称之为转移概率。下图描述了 3 个状态 $S_a, S_b, S_c$ 之间转换状态的马尔可夫链。
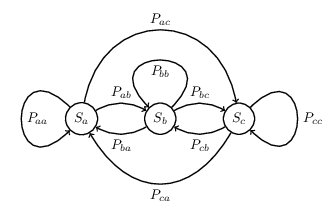
隐马尔可夫模型中包含两种序列:随机生成的状态构成的序列称之为状态序列(state sequence),状态序列是不可被观测到的;每个状态对应的观测值组成的序列称之为观测序列(observation sequence)。令 $I = \left(i_1, i_2, \cdots, i_T\right)$ 为状态序列,其中 $i_t$ 为第 $t$ 时刻系统的状态值,对应的有 $O = \left(o_1, o_2, \cdots, o_T\right)$ 为观测序列,其中 $o_t$ 为第 $t$ 时刻系统的观测值,系统的所有可能的状态集合为 $Q = \{q_1, q_2, \cdots, q_N\}$,所有可能的观测集合为 $V= \{v_1, v_2, \cdots, v_M\}$。
隐马尔可夫模型主要由三组参数构成:
- 状态转移矩阵:
$$ A = \left[a_{ij}\right]_{N \times N} $$其中,$$ a_{ij} = P \left(i_{t+1} = q_j | i_t = q_i\right), 1 \leq i, j \leq N $$表示$t$时刻状态为$q_i$的情况下,在$t+1$时刻状态转移到$q_j$的概率。 - 观测概率矩阵:
$$ B = \left[b_j \left(k\right)\right]_{N \times M} $$其中,$$ b_j \left(k\right) = P \left(o_t = v_k | i_t = q_j\right), k = 1, 2, \cdots, M, j = 1, 2, \cdots, N $$表示$t$时刻状态为$q_i$的情况下,观测值为$v_k$的概率。 - 初始状态概率向量:
$$ \pi = \left(\pi_i\right) $$其中,$$ \pi_i = P \left(i_1 = q_i\right), i = 1, 2, \cdots, N $$表示$t = 1$时刻,系统处于状态$q_i$的概率。
初始状态概率向量 $\pi$ 和状态转移矩阵 $A$ 决定了状态序列,观测概率矩阵 $B$ 决定了状态序列对应的观测序列,因此马尔可夫模型可以表示为:
$$ \lambda = \left(A, B, \pi\right) $$
对于马尔可夫模型 $\lambda = \left(A, B, \pi\right)$,通过如下步骤生成观测序列 $\{o_1, o_2, \cdots, o_T\}$:
- 按照初始状态分布
$\pi$产生状态$i_1$. - 令
$t = 1$。 - 按照状态
$i_t$的观测概率分布$b_{i_t} \left(k\right)$生成$o_t$。 - 按照状态
$i_t$的状态转移概率分布$\left\{a_{i_t i_{t+1}}\right\}$产生状态$i_{t+1}$,$i_{t+1} = 1, 2, \cdots, N$。 - 令
$t = t + 1$,如果$t < T$,转步骤 3;否则,终止。
马尔可夫模型在应用过程中有 3 个基本问题 1:
- 概率计算问题。给定模型
$\lambda = \left(A, B, \pi\right)$和观测序列$O = \{o_1, o_2, \cdots, o_T\}$,计算在模型$\lambda$下观测序列$O$出现的概率$P\left(O | \lambda \right)$。 - 学习问题。已知观测序列
$O = \{o_1, o_2, \cdots, o_T\}$,估计模型$\lambda = \left(A, B, \pi\right)$参数,使得在该模型下观测序列概率$P\left(X | \lambda \right)$最大。即用极大似然估计的方法估计参数。 - 预测问题,也称为解码(decoding)问题。已知模型
$\lambda = \left(A, B, \pi\right)$和观测序列$O = \{o_1, o_2, \cdots, o_T\}$,求对给定观测序列条件概率$P \left(I | O\right)$最大的状态序列$I = \{i_1, i_2, \cdots, i_T\}$。即给定观测序列,求最有可能的对应的状态序列。
概率计算
直接计算法
给定模型 $\lambda = \left(A, B, \pi \right)$ 和观测序列 $O = \{o_1, o_2, ..., o_T\}$,计算在模型 $\lambda$ 下观测序列 $O$ 出现的概率 $P\left(O | \lambda \right)$。最简单的办法就是列举出左右可能的状态序列 $I = \{i_1, i_2, ..., i_T\}$,再根据观测概率矩阵 $B$,计算每种状态序列对应的联合概率 $P \left(O, I | \lambda\right)$,对其进行求和得到概率 $P\left(O | \lambda \right)$。
状态序列 $I = \{i_1, i_2, ..., i_T\}$ 的概率是:
$$ P \left(I | \lambda \right) = \pi_{y_1} \prod_{t = 1}^{T - 1} a_{{i_t}{i_{t+1}}} $$
对于固定的状态序列 $I = \{i_1, i_2, ..., i_T\}$,观测序列 $O = \{o_1, o_2, ..., o_T\}$ 的概率是:
$$ P \left(O | I, \lambda \right) = \prod_{t = 1}^{T} b_{i_t} \left(o_t\right) $$
$O$ 和 $I$ 同时出现的联合概率为:
$$ \begin{split} P \left(O, I | \lambda \right) &= P \left(O | I, \lambda \right) P \left(I | \lambda \right) \\ &= \pi_{y_1} \prod_{t = 1}^{T - 1} a_{{i_t}{i_{t+1}}} \prod_{t = 1}^{T} b_{i_t} \left(o_t\right) \end{split} $$
然后,对于所有可能的状态序列 $I$ 求和,得到观测序列 $O$ 的概率 $P \left(O | \lambda\right)$,即:
$$ \begin{split} P\left(O | \lambda \right) &= \sum_{I} P \left(O | I, \lambda \right) P \left(I | \lambda \right) \\ &= \sum_{i_1, i_2, \cdots, i_T} \pi_{y_1} \prod_{t = 1}^{T - 1} a_{{i_t}{i_{t+1}}} \prod_{t = 1}^{T} b_{i_t} \left(o_t\right) \end{split} $$
但利用上式的计算量很大,是 $O \left(T N^T\right)$ 阶的,这种算法不可行。
前向算法
前向概率:给定马尔可夫模型 $\lambda$,给定到时刻 $t$ 部分观测序列为 $o_1, o_2, \cdots, o_t$ 且状态为 $q_i$ 的概率为前向概率,记作:
$$ \alpha_t \left(i\right) = P \left(o_1, o_2, \cdots, o_t, i_t = q_i | \lambda\right) $$
可以递推地求得前向概率 $\alpha_t \left(i\right)$ 及观测序列概率 $P \left(O | \lambda\right)$,前向算法如下:
- 初值
$$ \alpha_{1}(i)=\pi_{i} b_{i}\left(o_{1}\right), \quad i=1,2, \cdots, N $$ - 递推,对
$t = 1, 2, \cdots, T-1$$$ \alpha_{t+1}(i)=\left[\sum_{j=1}^{N} \alpha_{t}(j) a_{j i}\right] b_{i}\left(o_{t+1}\right), \quad i=1,2, \cdots, N $$ - 终止
$$ P(O | \lambda)=\sum_{i=1}^{N} \alpha_{T}(i) $$
后向算法
后向概率:给定隐马尔可夫模型 $\lambda$,给定在时刻 $t$ 状态为 $q_i$ 的条件下,从 $t+1$ 到 $T$ 的部分观测序列为 $o_{t+1}, o_{t+2}, \cdots, o_T$ 的概率为后向概率,记作:
$$ \beta_{t}(i)=P\left(o_{t+1}, o_{t+2}, \cdots, o_{T} | i_{t}=q_{i}, \lambda\right) $$
可以递推地求得后向概率 $\alpha_t \left(i\right)$ 及观测序列概率 $P \left(O | \lambda\right)$,后向算法如下:
- 初值
$$ \beta_{T}(i)=1, \quad i=1,2, \cdots, N $$ - 递推,对
$t = T-1, T-2, \cdots, 1$$$ \beta_{t}(i)=\sum_{j=1}^{N} a_{i j} b_{j}\left(o_{t+1}\right) \beta_{t+1}(j), \quad i=1,2, \cdots, N $$ - 终止
$$ P(O | \lambda)=\sum_{i=1}^{N} \pi_{i} b_{i}\left(o_{1}\right) \beta_{1}(i) $$
学习算法
监督学习算法
假设以给训练数据包含 $S$ 个长度相同的观测序列和对应的状态序列 $\left\{\left(O_1, I_1\right), \left(O_2, I_2\right), \cdots, \left(O_S, I_S\right)\right\}$,那么可以利用极大似然估计法来估计隐马尔可夫模型的参数。
设样本中时刻 $t$ 处于状态 $i$ 时刻 $t+1$ 转移到状态 $j$ 的频数为 $A_{ij}$,那么转移概率 $a_{ij}$ 的估计是:
$$ \hat{a}_{i j}=\frac{A_{i j}}{\sum_{j=1}^{N} A_{i j}}, \quad i=1,2, \cdots, N ; \quad j=1,2, \cdots, N $$
设样本中状态为 $j$ 并观测为 $k$ 的频数是 $B_{jk}$,那么状态为 $j$ 观测为 $k$ 的概率 $b_j \left(k\right)$ 的估计是:
$$ \hat{b}_{j}(k)=\frac{B_{j k}}{\sum_{k=1}^{M} B_{j k}}, \quad j=1,2, \cdots, N ; \quad k=1,2, \cdots, M $$
初始状态概率 $\pi_i$ 的估计 $\hat{\pi}_i$ 为 $S$ 个样本中初始状态为 $q_i$ 的频率。
无监督学习算法
假设给定训练数据值包含 $S$ 个长度为 $T$ 的观测序列 $\left\{O_1, O_2, \cdots, O_S\right\}$ 而没有对应的状态序例,目标是学习隐马尔可夫模型 $\lambda = \left(A, B, \pi\right)$ 的参数。我们将观测序列数据看做观测数据 $O$,状态序列数据看作不可观测的隐数据 $I$,那么马尔可夫模型事实上是一个含有隐变量的概率模型:
$$ P(O | \lambda)=\sum_{I} P(O | I, \lambda) P(I | \lambda) $$
它的参数学习可以由 EM 算法实现。EM 算法在隐马尔可夫模型学习中的具体实现为 Baum-Welch 算法:
- 初始化。对
$n = 0$,选取$a_{i j}^{(0)}, b_{j}(k)^{(0)}, \pi_{i}^{(0)}$,得到模型$\lambda^{(0)}=\left(A^{(0)}, B^{(0)}, \pi^{(0)}\right)$。 - 递推。对
$n = 1, 2, \cdots$:$$ \begin{aligned} a_{i j}^{(n+1)} &= \frac{\sum_{t=1}^{T-1} \xi_{t}(i, j)}{\sum_{t=1}^{T-1} \gamma_{t}(i)} \\ b_{j}(k)^{(n+1)} &= \frac{\sum_{t=1, o_{t}=v_{k}}^{T} \gamma_{t}(j)}{\sum_{t=1}^{T} \gamma_{t}(j)} \\ \pi_{i}^{(n+1)} &= \gamma_{1}(i) \end{aligned} $$右端各按照观测$O=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$和模型$\lambda^{(n)}=\left(A^{(n)}, B^{(n)}, \pi^{(n)}\right)$计算,$$ \begin{aligned} \gamma_{t}(i) &= \frac{\alpha_{t}(i) \beta_{t}(i)}{P(O | \lambda)}=\frac{\alpha_{t}(i) \beta_{t}(i)}{\sum_{j=1}^{N} \alpha_{t}(j) \beta_{t}(j)} \\ \xi_{t}(i, j) &= \frac{\alpha_{t}(i) a_{i j} b_{j}\left(o_{t+1}\right) \beta_{t+1}(j)}{\sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{t}(i) a_{i j} b_{j}\left(o_{t+1}\right) \beta_{t+1}(j)} \end{aligned} $$ - 终止。得到模型参数
$\lambda^{(n+1)}=\left(A^{(n+1)}, B^{(n+1)}, \pi^{(n+1)}\right)$。
预测算法
近似算法
近似算法的思想是,在每个时刻 $t$ 选择在该时刻最有可能出现的状态 $i_t^*$,从而得到一个状态序列 $I^{*}=\left(i_{1}^{*}, i_{2}^{*}, \cdots, i_{T}^{*}\right)$,将它作为预测的结果。给定隐马尔可夫模型 $\lambda$ 和观测序列 $O$,在时刻 $t$ 处于状态 $q_i$ 的概率 $\gamma_t \left(i\right)$ 是:
$$ \gamma_{t}(i)=\frac{\alpha_{t}(i) \beta_{t}(i)}{P(O | \lambda)}=\frac{\alpha_{t}(i) \beta_{t}(i)}{\sum_{j=1}^{N} \alpha_{t}(j) \beta_{t}(j)} $$
在每一时刻 $t$ 最有可能的状态 $i_t^*$ 是:
$$ i_{t}^{*}=\arg \max _{1 \leqslant i \leqslant N}\left[\gamma_{t}(i)\right], \quad t=1,2, \cdots, T $$
从而得到状态序列 $I^{*}=\left(i_{1}^{*}, i_{2}^{*}, \cdots, i_{T}^{*}\right)$。
近似算法的优点是计算简单,其缺点是不能保证预测的状态序列整体是最有可能的状态序列,因为预测的状态序列可能有实际不发生的部分。事实上,上述方法得到的状态序列中有可能存在转移概率为0的相邻状态,即对某些 $i, j, a_{ij} = 0$ 。尽管如此,近似算法仍然是有用的。
维特比算法
维特比算法(Viterbi Algorithm)实际是用动态规划(Dynamic Programming)解隐马尔可夫模型预测问题,即用动态规划求概率最大路径(最优路径)。这时一条路径对应着一个状态序列。
首先导入两个变量 $\sigma$ 和 $\Psi$。定义在时刻 $t$ 状态为 $i$ 的所有单个路径 $\left(i_1, i_2, \cdots, i_t\right)$ 中概率最大值为:
$$ \delta_{t}(i)=\max _{i_{1}, i_{2}, \cdots, i_{t-1}} P\left(i_{t}=i, i_{t-1}, \cdots, i_{1}, o_{t}, \cdots, o_{1} | \lambda\right), \quad i=1,2, \cdots, N $$
由定义可得变量 $\sigma$ 的递推公式:
$$ \begin{aligned} \delta_{t+1}(i) &=\max _{i_{1}, i_{2}, \cdots, i_{t}} P\left(i_{t+1}=i, i_{t}, \cdots, i_{1}, o_{t+1}, \cdots, o_{1} | \lambda\right) \\ &=\max _{1 \leqslant j \leqslant N}\left[\delta_{t}(j) a_{j i}\right] b_{i}\left(o_{t+1}\right), \quad i=1,2, \cdots, N ; \quad t=1,2, \cdots, T-1 \end{aligned} $$
定义在时刻 $t$ 状态为 $i$ 的所有单个路径 $\left(i_1, i_2, \cdots, i_{t-1}, i\right)$ 中概率最大的路径的第 $t - 1$ 个结点为:
$$ \Psi_{t}(i)=\arg \max _{1 \leqslant j \leqslant N}\left[\delta_{t-1}(j) a_{j i}\right], \quad i=1,2, \cdots, N $$
维特比算法流程如下:
- 初始化
$$ \begin{array}{c} \delta_{1}(i)=\pi_{i} b_{i}\left(o_{1}\right), \quad i=1,2, \cdots, N \\ \Psi_{1}(i)=0, \quad i=1,2, \cdots, N \end{array} $$ - 递推。对
$t = 2, 3, \cdots, T$$$ \begin{array}{c} \delta_{t}(i)=\max _{1 \leqslant j \leqslant N}\left[\delta_{t-1}(j) a_{j i}\right] b_{i}\left(o_{t}\right), \quad i=1,2, \cdots, N \\ \Psi_{t}(i)=\arg \max _{1 \leqslant j \leqslant N}\left[\delta_{t-1}(j) a_{j i}\right], \quad i=1,2, \cdots, N \end{array} $$ - 终止。
$$ \begin{array}{c} P^{*}=\max _{1 \leqslant i \leqslant N} \delta_{T}(i) \\ i_{T}^{*}=\arg \max _{1 \leqslant i \leqslant N}\left[\delta_{T}(i)\right] \end{array} $$ - 最优路径回溯。对
$t = T - 1, T - 2, \cdots, 1$$$ i_{t}^{*}=\Psi_{t+1}\left(i_{t+1}^{*}\right) $$
求的最优路径 $I^{*}=\left(i_{1}^{*}, i_{2}^{*}, \cdots, i_{T}^{*}\right)$。
条件随机场
概率无向图模型(Probabilistic Undirected Graphical Model)又称为马尔可夫随机场(Markov Random Field),是一个可以由无向图表示的联合概率分布。概率图模型(Probabilistic Graphical Model)是由图表示的概率分布,设有联合概率分布 $P \left(Y\right), Y \in \mathcal{Y}$ 是一组随机变量。由无向图 $G = \left(V, E\right)$ 表示概率分布 $P \left(Y\right)$,即在图 $G$ 中,结点 $v \in V$ 表示一个随机变量 $Y_v, Y = \left(Y_v\right)_{v \in V}$,边 $e \in E$ 表示随机变量之间的概率依赖关系。
成对马尔可夫性:设 $u$ 和 $v$ 是无向图 $G$ 中任意两个没有边连接的结点,结点 $u$ 和 $v$ 分别对应随机变量 $Y_u$ 和 $Y_v$。其他所有结点为 $O$,对应的随机变量组是 $Y_O$。成对马尔可夫是指给定随机变量组 $Y_O$ 的条件下随机变量 $Y_u$ 和 $Y_v$ 是条件独立的,即:
$$ P\left(Y_{u}, Y_{v} | Y_{O}\right)=P\left(Y_{u} | Y_{O}\right) P\left(Y_{v} | Y_{O}\right) $$
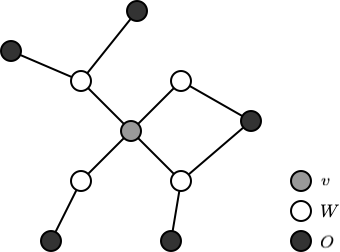
局部马尔可夫性:设 $v \in V$ 是无向图 $G$ 中任意一个结点,$W$ 是与 $v$ 有边连接的所有结点,$O$ 是 $v$ 和 $W$ 以外的其他所有结点。$v$ 表示的随机变量是 $Y_v$,$W$ 表示的随机变量组是 $Y_W$,$O$ 表示的随机变量组是 $Y_O$。局部马尔可夫性是指在给定随机变量组 $Y_W$ 的条件下随机变量 $Y_v$ 与随机变量组 $Y_O$ 是独立的,即:
$$ P\left(Y_{v}, Y_{O} | Y_{W}\right)=P\left(Y_{v} | Y_{W}\right) P\left(Y_{O} | Y_{W}\right) $$
在 $P \left(Y_O | Y_W\right) > 0$ 时,等价地:
$$ P\left(Y_{v} | Y_{W}\right)=P\left(Y_{v} | Y_{W}, Y_{O}\right) $$
局部马尔可夫性如下图所示:
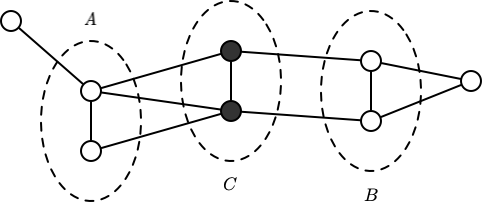
全局马尔可夫性:设结点结合 $A, B$ 是在无向图 $G$ 中被结点集合 $C$ 分开的任意结点集合,如下图所示。结点集合 $A, B$ 和 $C$ 所对应的随机变量组分别是 $Y_A, Y_B$ 和 $Y_C$。全局马尔可夫性是指给定随机变量组 $Y_C$ 条件下随机变量组 $Y_A$ 和 $Y_B$ 是条件独立的,即:
$$ P\left(Y_{A}, Y_{B} | Y_{C}\right)=P\left(Y_{A} | Y_{C}\right) P\left(Y_{B} | Y_{C}\right) $$
概率无向图模型定义为:设有联合概率分布 $P \left(Y\right)$,由无向图 $G = \left(V, E\right)$ 表示,在图 $G$ 中,结点表示随机变量,边表示随机变量之间的依赖关系。如果联合概率分布 $P \left(Y\right)$ 满足成对、局部或全局马尔可夫性,就称此联合概率分布为概率无向图模型(Probabilistic Undirected Graphical Model),或马尔可夫随机场(Markov Random Field)。
团与最大团:无向图 $G$ 中任何两个结点均有边连接的结点子集称为团(Clique)。若 $C$ 是无向图 $G$ 的一个团,并且不能再加进任何一个 $G$ 的结点时期成为一个更大的团,则称此 $C$ 为最大团(Maximal Clique)。

上图表示 4 个结点组成的无向图。图中有 2 个结点组成的团有 5 个:$\left\{Y_1, Y_2\right\}$,$\left\{Y_2, Y_3\right\}$,$\left\{Y_3, Y_4\right\}$,$\left\{Y_4, Y_2\right\}$ 和 $\left\{Y_1, Y_3\right\}$。有 2 个最大团:$\left\{Y_1, Y_2, Y_3\right\}$ 和 $\left\{Y_2, Y_3, Y_4\right\}$。而 $\left\{Y_1, Y_2, Y_3, Y_4\right\}$ 不是一个团,因为 $Y_1$ 和 $Y_4$ 没有边连接。
将概率无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为概率无向图模型的因子分解。给定无向图模型,设其无向图为 $G$,$C$ 为 $G$ 上的最大团,$Y_C$ 表示 $C$ 对应的随机变量。那么概率无向图模型的联合概率分布 $P \left(Y\right)$ 可以写作图中所有最大团 $C$ 上的函数 $\Psi_C \left(Y_C\right)$ 的乘积形式,即:
$$ P(Y)=\frac{1}{Z} \prod_{C} \Psi_{C}\left(Y_{C}\right) $$
其中,$Z$ 是规范化因子:
$$ Z=\sum_{Y} \prod_{C} \Psi_{C}\left(Y_{C}\right) $$
规范化因子保证 $P \left(Y\right)$ 构成一个概率分布。函数 $\Psi_C \left(Y_C\right)$ 称为势函数,这里要求势函数 $\Psi_C \left(Y_C\right)$ 是严格正的,通常定义为指数函数:
$$ \Psi_{C}\left(Y_{C}\right)=\exp \left\{-E\left(Y_{C}\right)\right\} $$
概率无向图模型的因子分解由这个 Hammersley-Clifford 定理来保证。
条件随机场(Conditional Random Field)是给定随机变量 $X$ 条件下,随机变量 $Y$ 的马尔可夫随机场。设 $X$ 与 $Y$ 是随机变量,$P \left(Y | X\right)$ 是给定 $X$ 的条件下 $Y$ 的条件概率分布。若随机变量 $Y$ 构成一个有无向图 $G = \left(V, E\right)$ 表示的马尔可夫随机场,即:
$$ P\left(Y_{v} | X, Y_{w}, w \neq v\right)=P\left(Y_{v} | X, Y_{w}, w \sim v\right) $$
对任意结点 $v$ 成立,则称条件概率分布 $P \left(Y | X\right)$ 为条件随机场。其中,$w \sim v$ 表示在图 $G = \left(V, E\right)$ 中与结点 $v$ 有边连接的所有结点 $w$,$w \neq v$ 表示结点 $v$ 以外的所有结点,$Y_v, Y_u$ 与 $Y_w$ 为结点 $v, u$ 和 $w$ 对应的随机变量。
定义中并没有要求 $X$ 和 $Y$ 具有相同的结构,一般假设 $X$ 和 $Y$ 有相同的图结构,下图展示了无向图的线性链情况,即:
$$ G=(V=\{1,2, \cdots, n\}, E=\{(i, i+1)\}), \quad i=1,2, \cdots, n-1 $$


此情况下,$X=\left(X_{1}, X_{2}, \cdots, X_{n}\right), Y=\left(Y_{1}, Y_{2}, \cdots, Y_{n}\right)$,最大团是相邻两个结点的集合。
线性链条件随机场:设 $X=\left(X_{1}, X_{2}, \cdots, X_{n}\right), Y=\left(Y_{1}, Y_{2}, \cdots, Y_{n}\right)$ 均为线性链表示的随机变量序列,若在给定随机变量序列 $X$ 的条件下,随机变量序列 $Y$ 的条件概率分布 $P \left(Y | X\right)$ 构成条件随机场,即满足马尔可夫性:
$$ \begin{array}{c} P\left(Y_{i} | X, Y_{1}, \cdots, Y_{i-1}, Y_{i+1}, \cdots, Y_{n}\right)=P\left(Y_{i} | X, Y_{i-1}, Y_{i+1}\right) \\ i=1,2, \cdots, n \quad (\text { 在 } i=1 \text { 和 } n \text { 时只考虑单边 }) \end{array} $$
则称 $P \left(Y | X\right)$ 为线性链条件随机场。在标注问题中,$X$ 表示输入观测序列,$Y$ 表示对应的输出标记序列或状态序列。
根据 Hammersley-Clifford 定理,设 $P \left(Y | X\right)$ 为线性链条件随机场,则在随机变量 $X$ 取值为 $x$ 的条件下,随机变量 $Y$ 取值为 $y$ 的条件概率有如下形式:
$$ P(y | x)=\frac{1}{Z(x)} \exp \left(\sum_{i, k} \lambda_{k} t_{k}\left(y_{i-1}, y_{i}, x, i\right)+\sum_{i, l} \mu_{l} s_{l}\left(y_{i}, x, i\right)\right) $$
其中,
$$ Z(x)=\sum_{y} \exp \left(\sum_{i, k} \lambda_{k} t_{k}\left(y_{i-1}, y_{i}, x, i\right)+\sum_{i, l} \mu_{l} s_{l}\left(y_{i}, x, i\right)\right) $$
其中,$t_k$ 和 $s_l$ 是特征函数,$\lambda_k$ 和 $\mu_l$ 是对应的权值。$Z \left(x\right)$ 是规范化因子,求和是在所有可能的输出序列上进行的。
条件随机场的概率计算,学习算法和预测算法类似隐马尔可夫模型,在此不进行过多赘述,有兴趣的同学可以参见 1。
综上所述,隐马尔可夫模型和条件随机场的主要联系和区别如下:
- HMM 是概率有向图,CRF 是概率无向图
- HMM 是生成模型,CRF 是判别模型

如上图所示,上面部分为生成式模型,下面部分为判别式模型,生成式模型尝试构建联合分布 $P \left(Y, X\right)$,而判别模型则尝试构建条件分布 $P \left(Y | X\right)$。
序列标注
序列标注(Sequence Labeling)是自然语言处理中的一项重要任务,对于给定的文本序列需要给出对应的标注序列。常见的序列标注任务包含:组块分析(Chunking),词性标注(Part-of-Speech,POS)和命名实体识别(Named Entity Recognition,NER)。

上图为一段文本的词性标注和命名实体识别的结果。
词性标注
词性标注是指为分词结果中的每个单词标注一个正确的词性,即确定每个词是名词、动词、形容词或其他词性的过程。
一些常用中文标注规范如下:
- 北京大学现代汉语语料库基本加工规范 2
- 北大语料库加工规范:切分·词性标注·注音 3
- 计算所汉语词性标记集 3.0(ICTPOS 3.0)4
- The Part-Of-Speech Tagging Guidelines for the Penn Chinese Treebank (3.0) 5
- 中文文本标注规范(微软亚洲研究院)6
命名实体识别
命名实体识别,又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文本中的实体指称的边界和类别。
常用的标注标准有 IO,BIO,BIOES,BMEWO 和 BMEWO+ 等。(参考自:Coding Chunkers as Taggers: IO, BIO, BMEWO, and BMEWO+)
- IO 标注标准是最简单的标注方式,对于命名实体类别 X 标注为
I_X,其他则标注为O。由于没有标签界线表示,这种方式无法表示两个相邻的同类命名实体。 - BIO 标注标准将命名实体的起始部分标记为
B_X,其余部分标记为I_X。 - BIOES 标注标准将命名实体的起始部分标记为
B_X,中间部分标记为I_X,结尾部分标记为E_X,对于单个字符成为命名实体的情况标记为S_X。 - BMEWO 标注标准将命名实体的起始部分标记为
B_X,中间部分标记为M_X,结尾部分标记为E_X,对于单个字符成为命名实体的情况标记为W_X。 - BMEWO+ 标注标准在 BMEWO 的基础上针对不同情况的非命名实体标签的标注进行了扩展,同时增加了一个句外(out-of-sentence)标签
W_OOS,句子起始标签BB_O_OOS和句子结束标签WW_O_OOS,如 下表 所示:
| 标签 | 描述 | 可能上接的标签 | 可能下接的标签 |
|---|---|---|---|
B_X |
命名实体类型 X 的起始 | E_Y, W_Y, EE_O_X, WW_O_X |
M_X, W_X |
M_X |
命名实体类型 X 的中间 | B_X, M_X |
M_X, W_X |
E_X |
命名实体类型 X 的结尾 | B_X, M_X |
B_Y, W_Y, BB_O_X, WW_O_X |
W_X |
命名实体类型 X 的单个字符 | E_Y, W_Y, EE_O_X, WW_O_X |
B_Y, W_Y, BB_O_X, WW_O_X |
BB_O_X |
非命名实体的起始,上接命名实体类型 X | E_X, W_X |
MM_O, EE_O_Y |
MM_O |
非命名实体的中间 | BB_O_Y, MM_O |
MM_O, EE_O_Y |
EE_O_X |
非命名实体的结尾,下接命名实体类型 X | BB_O_Y, MM_O |
B_X, W_X |
WW_O_X |
非命名实体,上接命名实体,下接命名实体类型 X | E_X, W_X |
B_Y, W_Y |
不同标注标准的差别示例如下:
| 字符 | IO | BIO | BIOES | BMEWO | BMEWO+ |
|---|---|---|---|---|---|
W_OOS |
|||||
| Yesterday | O |
O |
O |
O |
BB_O_OOS |
| afternoon | O |
O |
O |
O |
MM_O |
| , | O |
O |
O |
O |
EE_O_PER |
| John | I_PER |
B_PER |
B_PER |
B_PER |
B_PER |
| J | I_PER |
I_PER |
I_PER |
M_PER |
M_PER |
| . | I_PER |
I_PER |
I_PER |
M_PER |
M_PER |
| Smith | I_PER |
I_PER |
E_PER |
E_PER |
E_PER |
| traveled | O |
O |
O |
O |
BB_O_PER |
| to | O |
O |
O |
O |
EE_O_LOC |
| Washington | I_LOC |
B_LOC |
S_LOC |
W_LOC |
W_LOC |
| . | O |
O |
O |
O |
WW_O_OOS |
W_OOS |
不同标准的标签数量如下表所示:
| 标注标准 | 标签数量 | N=1 | N=3 | N=20 |
|---|---|---|---|---|
| IO | N+1 | 2 | 4 | 21 |
| BIO | 2N+1 | 3 | 7 | 41 |
| BIOES | 4N+1 | 5 | 13 | 81 |
| BMEWO | 4N+1 | 5 | 13 | 81 |
| BMEWO+ | 7N+3 | 10 | 24 | 143 |
其中,N 为命名实体类型的数量。
BiLSTM CRF 7
本小节内容参考和修改自 CRF-Layer-on-the-Top-of-BiLSTM。
Huang 等人提出了一种基于 BiLSTM 和 CRF 的神经网络模型用于序例标注。整个网络如下图所示:
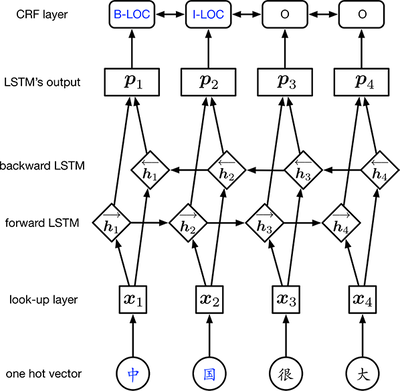
关于模型中的 BiLSTM 部分在此不过多赘述,相关细节可以参见之前的博客:循环神经网络 (Recurrent Neural Network, RNN) 和 预训练自然语言模型 (Pre-trained Models for NLP)。BiLSTM-CRF 模型的输入是词嵌入向量,输出是对应的预测标注标签,如下图所示:
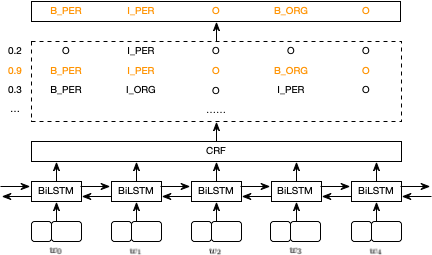
BiLSTM 层的输出为每个标签的分数,对于 $w_0$,BiLSTM 的输出为 1.5 (B_PER),0.9 (I_PER),0.1 (B_ORG),0.08 (I_ORG) 和 0.05 (O),这些分数为 CRF 层的输入,如下图所示:
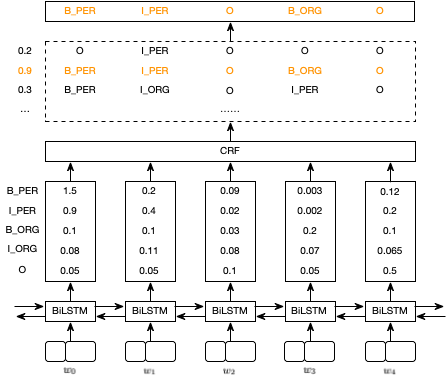
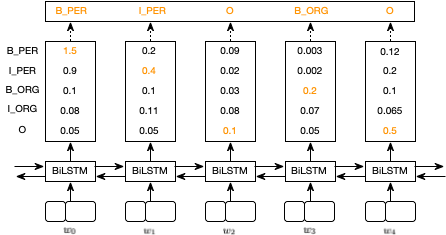
经过 CRF 层后,具有最高分数的预测序列被选择为最优预测结果。如果没有 CRF 层,我们可以直接选择 BiLSTM 层输出分数的最大值对应的序列为预测结果。例如,对于 $w_0$,最高分数为 1.5,对应的预测标签则为 B_PER,类似的 $w_1, w_2, w_3, w_4$ 对应的预测标签为 I_PER, O, B_ORG, O,如下图所示:
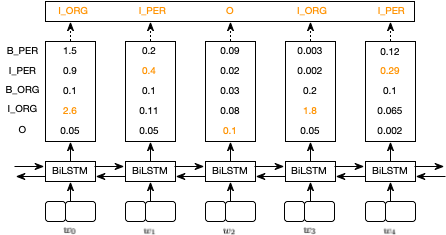
虽然我们在上例中得到了正确的结果,但通常情况下并非如此。对于如下的示例,预测结果为 I_ORG, I_PER, O, I_ORG, I_PER,这显然是不正确的。
CRF 层在进行预测时可以添加一些约束,这些约束可以在训练时被 CRF 层学习得到。可能的约束有:
- 句子的第一个词的标签可以是
B_X或O,而非I_X。 B_X, I_X是有效的标签,而B_X, I_Y是无效的标签。- 一个命名实体的起始标签应为
B_X而非I_X。
CRF 层的损失包含两部分,这两部分构成了 CRF 层的关键:
- 发射分数(Emission Score)
发射分数即为 BiLSTM 层的输出分数,例如 $w_0$ 对应的标签 B_PER 的分数为 1.5。为了方便起见,对于每类标签给定一个索引:
| 标签 | 索引 |
|---|---|
B_PER |
0 |
I_PER |
1 |
B_ORG |
2 |
I_ORG |
3 |
O |
4 |
我们利用 $x_{i y_{j}}$ 表示发射分数,$i$ 为词的索引,$y_i$ 为标注标签的索引。例如:$x_{i=1, y_{j}=2} = x_{w_1, \text{B\_ORG}} = 0.1$,表示 $w_1$ 为 B_ORG 的分数为 0.1。
- 转移分数(Transition Score)
我们利用 $t_{y_i, y_j}$ 表示转移分数,例如 $t_{\text{B\_PER}, \text{I\_PER}} = 0.9$ 表示由标签 B_PER 转移到 I_PER 的分数为 0.9。因此,需要一个转移分数矩阵用于存储所有标注标签之间的转移分数。为了使得转移分数矩阵更加鲁棒,需要添加两个标签 START 和 END,分别表示一个句子的开始和结束。下表为一个转移分数矩阵的示例:
START |
B-PER |
I-PER |
B-ORG |
I-ORG |
O |
END |
|
|---|---|---|---|---|---|---|---|
START |
0 | 0.8 | 0.007 | 0.7 | 0.0008 | 0.9 | 0.08 |
B_PER |
0 | 0.6 | 0.9 | 0.2 | 0.0006 | 0.6 | 0.009 |
I_PER |
-1 | 0.5 | 0.53 | 0.55 | 0.0003 | 0.85 | 0.008 |
B_ORG |
0.9 | 0.5 | 0.0003 | 0.25 | 0.8 | 0.77 | 0.006 |
I_ORG |
-0.9 | 0.45 | 0.007 | 0.7 | 0.65 | 0.76 | 0.2 |
O |
0 | 0.65 | 0.0007 | 0.7 | 0.0008 | 0.9 | 0.08 |
END |
0 | 0 | 0 | 0 | 0 | 0 | 0 |
转移分数矩阵作为 BiLSTM-CRF 模型的一个参数,随机初始化并通过模型的训练不断更新,最终学习得到约束条件。
CRF 层的损失函数包含两个部分:真实路径分数和所有可能路径的总分数。假设每个可能的路径有一个分数 $P_i$,共 $N$ 种可能的路径,所有路径的总分数为:
$$ P_{\text {total}}=P_{1}+P_{2}+\ldots+P_{N}=e^{S_{1}}+e^{S_{2}}+\ldots+e^{S_{N}} $$
则损失函数定义为:
$$ \text{Loss} = \dfrac{P_{\text{RealPath}}}{\sum_{i=1}^{N} P_i} $$
对于 $S_i$,共包含两部分:发射分数和转移分数。以路径 START -> B_PER -> I_PER -> O -> B_ORG -> O -> END 为例,发射分数为:
$$ \begin{aligned} \text{EmissionScore} = \ &x_{0, \text{START}} + x_{1, \text{B\_PER}} + x_{2, \text{I\_PER}} \\ &+ x_{3, \text{O}} + x_{4, \text{B\_ORG}} + x_{5, \text{O}} + x_{6, \text{END}} \end{aligned} $$
其中 $x_{i, y_j}$ 表示第 $i$ 个词标签为 $y_j$ 的分数,为 BiLSTM 的输出,$x_{0, \text{START}}$ 和 $x_{6, \text{END}}$ 可以设置为 0。转换分数为:
$$ \begin{aligned} \text{TransitionScore} = \ &t_{\text{START}, \text{B\_PER}} + t_{\text{B\_PER}, \text{I\_PER}} + t_{\text{I\_PER}, \text{O}} \\ &+ t_{\text{O}, \text{B\_ORG}} + t_{\text{B\_ORG}, \text{O}} + t_{\text{O}, \text{END}} \end{aligned} $$
其中 $t_{y_i, y_j}$ 表示标注标签由 $y_i$ 转移至 $y_j$ 的分数。
对于所有路径的总分数的计算过程采用了类似 动态规划 的思想,整个过程计算比较复杂,在此不再详细展开,详细请参见参考文章。
利用训练好的 BiLSTM-CRF 模型进行预测时,首先我们可以得到序列的发射分数和转移分数,其次用维特比算法可以得到最终的预测标注序列。
Lattice LSTM 8
Zhang 等人针对中文提出了一种基于 Lattice LSTM 的命名实体识别方法,Lattice LSTM 的结构如下图所示:
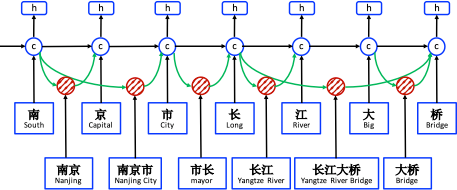
模型的基本思想是将句子中的词汇(例如:南京,长江大桥等)信息融入到基于字符的 LSTM 模型中,从而可以显性地利用词汇信息。
模型的输入为一个字符序列 $c_1, c_2, \cdots, c_m$ 和词汇表 $\mathbb{D}$ 中所有匹配的字符子序列,其中词汇表 $\mathbb{D}$ 利用大量的原始文本通过分词构建。令 $w_{b, e}^d$ 表示有以第 $b$ 个字符起始,以第 $e$ 个字符结尾的子序列,例如:$w_{1,2}^d$ 表示“南京
”,$w_{7,8}^d$ 表示“大桥”。
不同于一般的字符级模型,LSTM 单元的状态考虑了句子中的子序列 $w_{b,e}^d$,每个子序列 $w_{b,e}^d$ 表示为:
$$ \mathbf{x}_{b, e}^{w}=\mathbf{e}^{w}\left(w_{b, e}^{d}\right) $$
其中,$\mathbf{e}^{w}$ 为词向量查询表。一个词单元 $\mathbf{c}_{b,e}^w$ 用于表示 $\mathbf{x}_{b,e}^w$ 的循环状态:
$$ \begin{aligned} \left[\begin{array}{c} \mathbf{i}_{b, e}^{w} \\ \mathbf{f}_{b, e}^{w} \\ \widetilde{c}_{b, e}^{w} \end{array}\right] &=\left[\begin{array}{c} \sigma \\ \sigma \\ \tanh \end{array}\right]\left(\mathbf{W}^{w \top}\left[\begin{array}{c} \mathbf{x}_{b, e}^{w} \\ \mathbf{h}_{b}^{c} \end{array}\right]+\mathbf{b}^{w}\right) \\ \mathbf{c}_{b, e}^{w} &=\mathbf{f}_{b, e}^{w} \odot \mathbf{c}_{b}^{c}+\mathbf{i}_{b, e}^{w} \odot \widetilde{c}_{b, e}^{w} \end{aligned} $$
其中,$\mathbf{i}_{b, e}^{w}$ 和 $\mathbf{f}_{b, e}^{w}$ 分别为输入门和遗忘门。由于仅在字符级别上进行标注,因此对于词单元来说没有输出门。
对于 $\mathbf{c}_{j}^c$ 来说可能有多条信息流,例如 $\mathbf{c}_7^c$ 的输入包括 $\mathbf{x}_7^c$(桥),$\mathbf{c}_{6,7}^w$(大桥)和 $\mathbf{c}_{4,7}^w$(长江大桥)。论文采用了一个新的门 $\mathbf{i}_{b,e}^c$ 来控制所有子序列单元 $\mathbf{c}_{b,e}^w$ 对 $\mathbf{c}_{j}^c$ 的贡献:
$$ \mathbf{i}_{b, e}^{c}=\sigma\left(\mathbf{W}^{l \top}\left[\begin{array}{c} \mathbf{x}_{e}^{c} \\ \mathbf{c}_{b, e}^{w} \end{array}\right]+\mathbf{b}^{l}\right) $$
则单元状态 $\mathbf{c}_j^c$ 的计算变为:
$$ \mathbf{c}_{j}^{c}=\sum_{b \in\left\{b^{\prime} | w_{b^{\prime}, j} \in \mathbb{D}\right\}} \boldsymbol{\alpha}_{b, j}^{c} \odot \boldsymbol{c}_{b, j}^{w}+\boldsymbol{\alpha}_{j}^{c} \odot \widetilde{\boldsymbol{c}}_{j}^{c} $$
在上式中,$\mathbf{i}_{b,j}^c$ 和 $\mathbf{i}_j^c$ 标准化为 $\boldsymbol{\alpha}_{b, j}^{c}$ 和 $\boldsymbol{\alpha}_{j}^{c}$:
$$ \begin{aligned} \boldsymbol{\alpha}_{b, j}^{c} &=\frac{\exp \left(\mathbf{i}_{b, j}^{c}\right)}{\exp \left(\mathbf{i}_{j}^{c}\right)+\sum_{b^{\prime} \in\left\{b^{\prime \prime} | w_{b^{\prime \prime}, j}^{d} \in \mathbb{D}\right\}} \exp \left(\mathbf{i}_{b^{\prime}, j}^{c}\right)} \\ \boldsymbol{\alpha}_{j}^{c} &=\frac{\exp \left(\mathbf{i}_{j}^{c}\right)}{\exp \left(\mathbf{i}_{j}^{c}\right)+\sum_{b^{\prime} \in\left\{b^{\prime \prime} | w_{b^{\prime \prime}, j}^{d} \in \mathbb{D}\right\}} \exp \left(\mathbf{i}_{b^{\prime}, j}^{c}\right)} \end{aligned} $$
开放资源
标注工具
- synyi/poplar
- nlplab/brat
- doccano/doccano
- heartexlabs/label-studio
- deepwel/Chinese-Annotator
- jiesutd/YEDDA
开源模型,框架和代码
- pytorch/text
- flairNLP/flair
- PetrochukM/PyTorch-NLP
- allenai/allennlp
- fastnlp/fastNLP
- Stanford CoreNLP
- NeuroNER
- spaCy
- NLTK
- BrikerMan/Kashgari
- Hironsan/anago
- crownpku/Information-Extraction-Chinese
- thunlp/OpenNRE
- hankcs/HanLP
- jiesutd/NCRFpp
其他资源
-
俞士汶, 段慧明, 朱学锋, & 孙斌. (2002). 北京大学现代汉语语料库基本加工规范. 中文信息学报, 16(5), 51-66. ↩︎
-
俞士汶, 段慧明, 朱学锋, 孙斌, & 常宝宝. (2003). 北大语料库加工规范: 切分· 词性标注· 注音. 汉语语言与计算学报, 13(2), 121-158. ↩︎
-
Xia, F. (2000). The part-of-speech tagging guidelines for the Penn Chinese Treebank (3.0). IRCS Technical Reports Series, 38. ↩︎
-
Huang, C. N., Li, Y., & Zhu, X. (2006). Tokenization guidelines of Chinese text (v5.0, in Chinese). Microsoft Research Asia. ↩︎
-
Huang, Z., Xu, W., & Yu, K. (2015). Bidirectional LSTM-CRF models for sequence tagging. arXiv preprint arXiv:1508.01991. ↩︎
-
Zhang, Y., & Yang, J. (2018). Chinese NER Using Lattice LSTM. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1554-1564). ↩︎