本文为《强化学习系列》文章
本文内容主要参考自:
1.《强化学习》1
2. CS234: Reinforcement Learning 2
3. UCL Course on RL 3
蒙特卡洛算法仅需要经验,即从真实或者模拟的环境交互中采样得到的状态、动作、收益的序例。从真实经验中学习不需要关于环境动态变化规律的先验知识,却依然能够达到最优的行为;从模拟经验中学习尽管需要一个模型,但这个模型只需要能够生成状态转移的一些样本,而不需要像动态规划那样生成所有可能的转移概率分布。
蒙特卡洛预测
一个状态的价值是从该状态开始的期望回报,即未来的折扣收益累积值的期望。那么一个显而易见的方式是根据经验进行估计,即对所有经过这个状态之后产生的回报进行平均。随着越来越多的回报被观察到,平均值就会收敛到期望值,这就是蒙特卡洛算法的基本思想。
假设给定策略 $\pi$ 下途径状态 $s$ 的多幕数据,我们需要估计策略 $\pi$ 下状态 $s$ 的价值函数 $v_{\pi} \left(s\right)$。在同一幕中,$s$ 可能多次被访问,因此蒙特卡洛方法分为首次访问型 MC 算法和每次访问型 MC 算法,两者的区别在于更新时是否校验 $S_t$ 已经在当前幕中出现过。以首次访问型 MC 预测算法为例,算法流程如下:
\begin{algorithm}
\caption{首次访问型 MC 预测算法,用于估计 $V \approx v_{\pi}$}
\begin{algorithmic}
\REQUIRE 待评估策略 $\pi$
\STATE 对于所有 $s \in \mathcal{S}$,任意初始化 $V \left(s\right) \in \mathbb{R}$
\STATE 对于所有 $s \in \mathcal{S}$,$Returns \left(s\right) \gets \varnothing$
\WHILE{TRUE}
\STATE 根据 $\pi$ 生成一幕序列 $S_0, A_0, R_1, \cdots, S_{T-1}, A_{T-1}, R_T$
\STATE $G \gets 0$
\FOR{$t \in T-1, T-2, \cdots, 0$}
\STATE $G \gets \gamma G + R_{t+1}$
\IF{$S_t$ 在 $S_0, S_1, \cdots, S_{t-1}$ 中出现过}
\STATE $Returns \left(S_t\right) \gets Resurn \left(S_t\right) \cup G$
\STATE $V \left(S_t\right) \gets avg \left(Returns \left(S_t\right)\right)$
\ENDIF
\ENDFOR
\ENDWHILE
\end{algorithmic}
\end{algorithm}
以二十一点游戏为例,每一局可以看作一幕,胜、负、平分别获得收益 $+1, -1, 0$。每局游戏进行中的收益都为 $0$,并且不打折扣($\gamma = 1$),最终的收益即为整个游戏的回报。玩家的动作为要牌(Hit)或停牌(Stand),状态则取决于玩家的牌和庄家显示的牌。假设所有牌来自无穷多的一组牌(即每次取出的牌都会再放回牌堆)。如果玩家手上有一张 A,可以视作 11 而不爆掉,那么称这张 A 为可用的,此时这张牌总会被视作 11。因此,玩家做出的选择只会依赖于三个变量:他手牌的总和(12-31),庄家显示的牌(A-10),以及他是否有可用的 A,共计 200 个状态。
考虑如下策略,玩家在手牌点数之和小于 20 时均要牌,否则停牌。通过该策略多次模型二十一点游戏,并且计算每一个状态的回报的平均值。模拟结果如下:
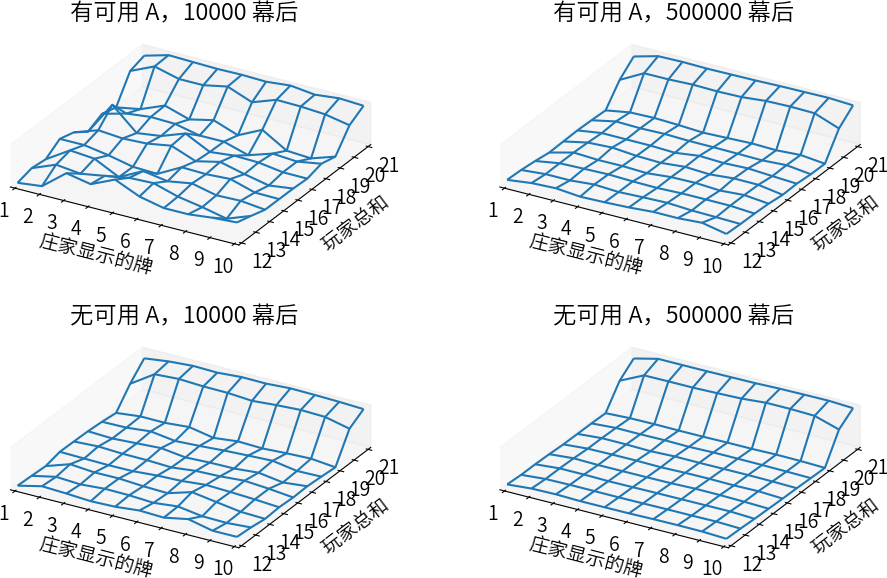
有可用 A 的状态的估计会更不确定、不规律,因为这样的状态更加罕见。无论哪种情况,在大于约 500000 局游戏后,价值函数都能很好地近似。
蒙特卡洛控制
如果无法得到环境的模型,那么计算动作的价值(“状态-动作”二元组的价值)比计算状态的价值更加有用。动作价值函数的策略评估的目标是估计 $q_{\pi} \left(s, a\right)$,即在策略 $\pi$ 下从状态 $s$ 采取动作 $a$ 的期望回报。只需将对状态的访问改为对“状态-动作”二元组的访问,蒙特卡洛算法就可以几乎和之前完全相同的方式解决该问题,唯一复杂之处在于一些“状态-动作”二元组可能永远不会被访问到。为了实现基于动作价值函数的策略评估,我们必须保证持续的试探。一种方式是将指定的“状态-动作”二元组作为起点开始一幕采样,同时保证所有“状态-动作”二元组都有非零的概率可以被选为起点。这样就保证了在采样的幕个数趋于无穷时,每一个“状态-动作”二元组都会被访问到无数次。我们把这种假设称为试探性出发。
策略改进的方法是在当前价值函数上贪心地选择动作。由于我们有动作价值函数,所以在贪心的时候完全不需要使用任何的模型信息。对于任意的一个动作价值函数 $q$,对应的贪心策略为:对于任意一个状态 $s \in \mathcal{S}$,必定选择对应动作价值函数最大的动作:
$$ \pi \left(s\right) = \arg\max_a q \left(s, a\right) $$
策略改进可以通过将 $q_{\pi_k}$ 对应的贪心策略作为 $\pi_{k+1}$ 来进行。这样的 $\pi_k$ 和 $\pi_{k+1}$ 满足策略改进定理,因为对于所有的状态 $s \in \mathcal{S}$:
$$ \begin{aligned} q_{\pi_{k}}\left(s, \pi_{k+1}(s)\right) &=q_{\pi_{k}}\left(s, \underset{a}{\arg \max } q_{\pi_{k}}(s, a)\right) \\ &=\max _{a} q_{\pi_{k}}(s, a) \\ & \geqslant q_{\pi_{k}}\left(s, \pi_{k}(s)\right) \\ & \geqslant v_{\pi_{k}}(s) \end{aligned} $$
对于蒙特卡洛策略迭代,可以逐幕交替进行评估与改进。每一幕结束后,使用观测到的回报进行策略评估,然后在该幕序列访问到的每一个状态上进行策略改进。使用这个思路的一个简单算法称为基于试探性出发的蒙特卡洛(蒙特卡洛 ES),算法流程如下:
\begin{algorithm}
\caption{蒙特卡洛 ES(试探性出发),用于估计 $\pi \approx \pi_*$}
\begin{algorithmic}
\STATE 对于所有 $s \in \mathcal{S}$,任意初始化 $\pi \left(s\right) \in \mathcal{A} \left(s\right)$
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,任意初始化 $Q \left(s, a\right) \in \mathbb{R}$
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,$Returns \left(s, a\right) \gets \varnothing$
\WHILE{TRUE}
\STATE 选择 $S_0 \in \mathcal{S}$ 和 $A_0 \in \mathcal{A} \left(S_0\right)$ 以使得所有“状态-动作”二元组的概率都 $> 0$
\STATE 从 $S_0, A_0$ 开始根据 $\pi$ 生成一幕序列 $S_0, A_0, R_1, \cdots, S_{T-1}, A_{T-1}, R_T$
\STATE $G \gets 0$
\FOR{$t \in T-1, T-2, \cdots, 0$}
\STATE $G \gets \gamma G + R_{t+1}$
\IF{$S_t, A_t$ 在 $S_0, A_0, S_1, A_1, \cdots, S_{t-1}, A_{t-1}$ 中出现过}
\STATE $Returns \left(S_t, A_t\right) \gets Resurn \left(S_t, A_t\right) \cup G$
\STATE $Q \left(S_t, A_t\right) \gets avg \left(Returns \left(S_t, A_t\right)\right)$
\STATE $\pi \left(S_t\right) \gets \arg\max_a Q \left(S_t, a\right)$
\ENDIF
\ENDFOR
\ENDWHILE
\end{algorithmic}
\end{algorithm}
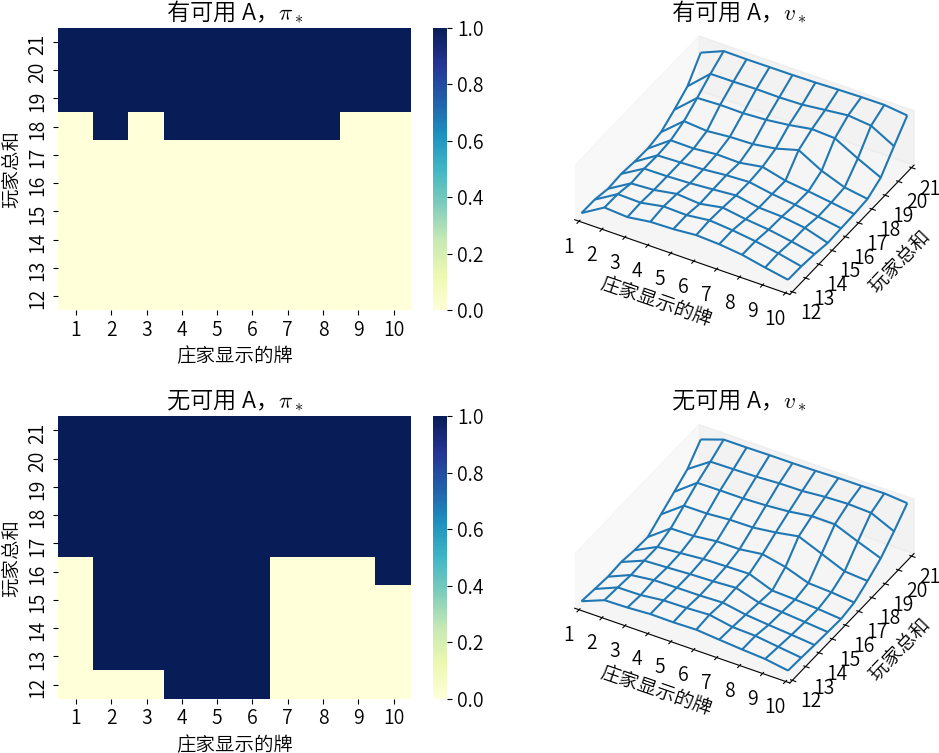
利用蒙特卡洛 ES 可以很直接地解决二十一点游戏,只需随机等概率选择庄家的扑克牌、玩家手牌的点数,以及确定是否有可用的 A 即可。令只在 20 或 21 点停牌为初始策略,初始动作价值函数全部为零,下图展示了蒙特卡洛 ES 得出的最优策略:
同轨策略和离轨策略
同轨策略
为了避免很难被满足的试探性出发假设,一般性的解法是智能体能够持续不断地选择所有可能的动作,有两种方法可以保证这一点,同轨策略(on-policy)和离轨策略(off-policy)。在同轨策略中,用于生成采样数据序列的策略和用于实际决策的待评估和改进的策略是相同的;而在离轨策略中,用于评估或改进的策略与生成采样数据的策略是不同的,即生成的数据“离开”了待优化的策略所决定的决策序列轨迹。
在同轨策略中,策略一般是“软性”的,即对于任意 $s \in \mathcal{S}$ 以及 $a \in \mathcal{A} \left(s\right)$,都有 $\pi \left(a | s\right) > 0$,但他们会逐渐地逼近一个确定性的策略。$\epsilon-$ 贪心策略是指在绝大多数时候都采取获得最大估计值的动作价值函数对应的动作,但同时以一个较小的概率 $\epsilon$ 随机选择一个动作。因此对于所有非贪心的动作都以 $\frac{\epsilon}{|\mathcal{A} \left(s\right)|}$ 的概率被选中,贪心动作则以 $1 - \epsilon + \frac{\epsilon}{|\mathcal{A} \left(s\right)|}$ 的概率被选中。同轨策略的蒙特卡洛控制
\begin{algorithm}
\caption{同轨策略的首次访问型 MC 控制算法(对于 $\epsilon-$ 软性策略),用于估计 $\pi \approx \pi_*$}
\begin{algorithmic}
\STATE $\pi \gets$ 一个任意的 $\epsilon-$ 软性策略
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,任意初始化 $Q \left(s, a\right) \in \mathbb{R}$
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,$Returns \left(s, a\right) \gets \varnothing$
\WHILE{TRUE}
\STATE 根据 $\pi$ 生成一幕序列 $S_0, A_0, R_1, \cdots, S_{T-1}, A_{T-1}, R_T$
\STATE $G \gets 0$
\FOR{$t \in T-1, T-2, \cdots, 0$}
\STATE $G \gets \gamma G + R_{t+1}$
\IF{$S_t, A_t$ 在 $S_0, A_0, S_1, A_1, \cdots, S_{t-1}, A_{t-1}$ 中出现过}
\STATE $Returns \left(S_t, A_t\right) \gets Resurn \left(S_t, A_t\right) \cup G$
\STATE $Q \left(S_t, A_t\right) \gets avg \left(Returns \left(S_t, A_t\right)\right)$
\STATE $A^* \gets \arg\max_a Q \left(S_t, a\right)$
\STATE 对于所有 $a \in \mathcal{A} \left(S_t\right)$,$\pi\left(a \mid S_{t}\right) \leftarrow\left\{\begin{array}{ll}
1-\varepsilon+\varepsilon /\left|\mathcal{A}\left(S_{t}\right)\right| & \text { if } a=A^{*} \\
\varepsilon /\left|\mathcal{A}\left(S_{t}\right)\right| & \text { if } a \neq A^{*}
\end{array}\right.$
\ENDIF
\ENDFOR
\ENDWHILE
\end{algorithmic}
\end{algorithm}
离轨策略
所有的学习控制方法都面临一个困境:它们希望学到的动作可以使随后的智能体行为是最优的,但是为了搜索所有的动作(以保证找到最优动作),它们需要采取非最优的行动。同轨策略采用一种妥协的方法,它并不学习最优策略的动作值,而是学习一个接近最优而且仍能进行试探的策略的动作值。一个更加直接的方法是采用两个策略,一个用来学习并成为最优策略,另一个更加有试探性,用来产生智能体的行动样本。用来学习的策略被称为目标策略,用于生成行动样本的策略被称为行动策略。在这种情况下,我们认为学习所用的数据“离开”了待学习的目标策略,因此整个过程称为离轨策略学习。
几乎所有的离轨策略方法都采用了重要度采样,重要度采样是一种在给定来自其他分布的样本的条件下,估计某种分布的期望值的通用方法。在离轨策略学习中,对回报值根据其轨迹在目标策略与行动策略中出现的相对概率进行加权,这个相对概率称为重要度采样比。给定起始状态 $S_t$,后续的“状态-动作”轨迹 $A_t, S_{t+1}, A_{t+1}, \cdots, S_T$ 在策略 $\pi$ 下发生的概率为:
$$ \begin{aligned} \operatorname{Pr}\left\{A_{t},\right.&\left.S_{t+1}, A_{t+1}, \ldots, S_{T} \mid S_{t}, A_{t: T-1} \sim \pi\right\} \\ &=\pi\left(A_{t} \mid S_{t}\right) p\left(S_{t+1} \mid S_{t}, A_{t}\right) \pi\left(A_{t+1} \mid S_{t+1}\right) \cdots p\left(S_{T} \mid S_{T-1}, A_{T-1}\right) \\ &=\prod_{k=t}^{T-1} \pi\left(A_{k} \mid S_{k}\right) p\left(S_{k+1} \mid S_{k}, A_{k}\right) \end{aligned} $$
其中,$p$ 为状态转移概率函数。因此,在目标策略和行动策略轨迹下的相对概率(重要度采样比)为:
$$ \rho_{t: T-1} \doteq \frac{\prod_{k=t}^{T-1} \pi\left(A_{k} \mid S_{k}\right) p\left(S_{k+1} \mid S_{k}, A_{k}\right)}{\prod_{k=t}^{T-1} b\left(A_{k} \mid S_{k}\right) p\left(S_{k+1} \mid S_{k}, A_{k}\right)}=\prod_{k=t}^{T-1} \frac{\pi\left(A_{k} \mid S_{k}\right)}{b\left(A_{k} \mid S_{k}\right)} $$
化简后,重要度采样比只与两个策略和样本序列数据相关,而与 MDP 的动态特性(状态转移概率)无关。我们希望估计目标策略下的期望回报(价值),但我们只有行动策略中的回报 $G_t$。直接使用行动策略中的回报进行估计是不准的,因此需要使用重要度采样比调整回报从而得到正确的期望值:
$$ \mathbb{E}\left[\rho_{t: T-1} G_{t} \mid S_{t}=s\right]=v_{\pi}(s) $$
定义所有访问过状态 $s$ 的时刻集合为 $\mathcal{T} \left(s\right)$,$T \left(t\right)$ 表示时刻 $t$ 后的首次终止,用 $G_t$ 表示在 $t$ 之后到达 $T \left(t\right)$ 时的回报值。则 $\left\{G_t\right\}_{t \in \mathcal{T} \left(s\right)}$ 就是状态 $s$ 对应的回报值,$\left\{\rho_{t:T \left(t\right) - 1}\right\}_{t \in \mathcal{T} \left(s\right)}$ 是相应的重要度采样比。则为了预测 $v_{\pi} \left(s\right)$,有:
$$ V(s) \doteq \frac{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1} G_{t}}{|\mathcal{T}(s)|} \label{eq:ordinary-importance-sampling} $$
为一种简单平均实现的重要度采样,称之为普通重要度采样。
$$ V(s) \doteq \frac{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1} G_{t}}{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1}} \label{eq:weighted-importance-sampling} $$
为一种加权的重要度采样,称之为加权重要度采样,如果分母为零,则式 $\ref{eq:weighted-importance-sampling}$ 的值也为零。式 $\ref{eq:ordinary-importance-sampling}$ 得到的结果在期望上是 $v_{\pi} \left(s\right)$ 的无偏估计,但其值可能变得很极端,式 $\ref{eq:weighted-importance-sampling}$ 的估计是有偏的,但其估计的方差可以收敛到 0。
我们对二十一点游戏的状态值进行离轨策略估计。评估的状态为玩家有一张 A,一张 2(或者等价情况,有三张 A),从这个状态开始等概率选择要牌或停牌得到采样数据,目标策略只在和达到 20 或 21 时停牌。
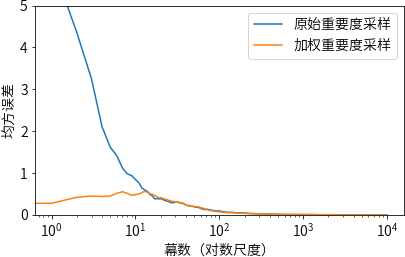
在目标策略中,这个状态的值大概为 -0.27726(利用目标策略独立生成 1 亿幕数据后对回报进行平均得到)。两种离轨策略方法在采样随机策略经过 1000 幕离轨策略数据采样后都很好地逼近了这个值,但加权重要度采样在开始时错误率明显较低,这也是实践中的典型现象。
假设一个回报序列 $G_1, G_2, \cdots, G_{n-1}$,它们都从相同的状态开始,且每一个回报都对应一个随机权重 $W_i$,我们希望获得如下式子的估计:
$$ V_{n} \doteq \frac{\sum_{k=1}^{n-1} W_{k} G_{k}}{\sum_{k=1}^{n-1} W_{k}}, \quad n \geq 2 $$
同时在获得一个额外的回报 $G_n$ 时能保持更新。为了能不断跟踪 $V_n$ 的变化,我们必须为每一个状态维护前 $n$ 个回报对应的权值的累加和 $C_n$。$V_n$ 的更新方法如下:
$$ \begin{array}{l} V_{n+1} \doteq V_{n}+\dfrac{W_{n}}{C_{n}}\left[G_{n}-V_{n}\right], \quad n \geq 1 \\ C_{n+1} \doteq C_{n}+W_{n+1} \end{array} $$
其中,$C_0 = 0$,$V_1$ 是任意值。一个完整的用于蒙特卡洛策略评估的逐幕增量算法如下:
\begin{algorithm}
\caption{离轨策略 MC 预测算法(策略评估),用于估计 $Q \approx q_{\pi}$}
\begin{algorithmic}
\REQUIRE 一个任意的目标策略 $\pi$
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,任意初始化 $Q \left(s, a\right) \in \mathbb{R}$
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,$C \left(s, a\right) \gets 0$
\WHILE{TRUE}
\STATE $b \gets$ 任何能包括 $\pi$ 的策略
\STATE 根据 $b$ 生成一幕序列 $S_0, A_0, R_1, \cdots, S_{T-1}, A_{T-1}, R_T$
\STATE $G \gets 0$
\STATE $W \gets 1$
\FOR{$t \in T-1, T-2, \cdots, 0$}
\STATE $G \gets \gamma G + R_{t+1}$
\STATE $C \left(S_t, A_t\right) \gets C \left(S_t, A_t\right) + W$
\STATE $Q \left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right)+\frac{W}{C\left(S_{t}, A_{t}\right)}\left[G-Q\left(S_{t}, A_{t}\right)\right]$
\STATE $W \leftarrow W \frac{\pi\left(A_{t} \mid S_{t}\right)}{b\left(A_{t} \mid S_{t}\right)}$
\IF{$W = 0$}
\BREAK
\ENDIF
\ENDFOR
\ENDWHILE
\end{algorithmic}
\end{algorithm}
在离轨策略中,策略的价值评估和策略的控制是分开的,用于生成行动数据的策略被称为行动策略,行动策略可能与实际上被评估和改善的策略无关,而被评估和改善的策略称为目标策略。这样分离的好处在于当行动策略能对所有可能的动作继续进行采样时,目标策略可以是确定的(贪心的)。
离轨策略蒙特卡洛控制方法要求行动策略对目标策略可能做出的所有动作都有非零的概率被选择。为了试探所有的可能性,要求行动策略是软性的。一个基于通用迭代策略(GPI)和重要度采样的离轨策略蒙特卡洛控制方法如下:
\begin{algorithm}
\caption{离轨策略 MC 控制算法,用于估计 $\pi \approx \pi_*$}
\begin{algorithmic}
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,任意初始化 $Q \left(s, a\right) \in \mathbb{R}$
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,$C \left(s, a\right) \gets 0$
\STATE 对于所有 $s \in \mathcal{S}, a \in \mathcal{A} \left(s\right)$,$\pi \left(s\right) \gets \arg\max_a Q \left(s, a\right)$
\STATE \COMMENT{出现平分情况选取方法应保持一致}
\WHILE{TRUE}
\STATE $b \gets$ 任意软性策略
\STATE 根据 $b$ 生成一幕序列 $S_0, A_0, R_1, \cdots, S_{T-1}, A_{T-1}, R_T$
\STATE $G \gets 0$
\STATE $W \gets 1$
\FOR{$t \in T-1, T-2, \cdots, 0$}
\STATE $G \gets \gamma G + R_{t+1}$
\STATE $C \left(S_t, A_t\right) \gets C \left(S_t, A_t\right) + W$
\STATE $Q \left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right)+\frac{W}{C\left(S_{t}, A_{t}\right)}\left[G-Q\left(S_{t}, A_{t}\right)\right]$
\STATE $\pi\left(S_{t}\right) \leftarrow \arg \max _{a} Q\left(S_{t}, a\right)$
\STATE \COMMENT{出现平分情况选取方法应保持一致}
\IF{$A_t \neq \pi \left(S_t\right)$}
\BREAK
\ENDIF
\STATE $W \leftarrow W \frac{1}{b\left(A_{t} \mid S_{t}\right)}$
\ENDFOR
\ENDWHILE
\end{algorithmic}
\end{algorithm}
本文示例代码实现请参见这里。
-
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press. ↩︎
-
CS234: Reinforcement Learning http://web.stanford.edu/class/cs234/index.html ↩︎
-
UCL Course on RL https://www.davidsilver.uk/teaching ↩︎