本文为《强化学习系列》文章
本文内容主要参考自:
1.《强化学习》1
2. CS234: Reinforcement Learning 2
3. UCL Course on RL 3
时序差分预测
时序差分(Temporal Difference,TD)和蒙特卡洛方法都利用经验来解决预测问题。给定策略 $\pi$ 的一些经验,以及这些经验中的非终止状态 $S_t$,一个适用于非平稳环境的简单的每次访问型蒙特卡洛方法可以表示为:
$$ V\left(S_{t}\right) \gets V\left(S_{t}\right)+\alpha\left[G_{t}-V\left(S_{t}\right)\right] \label{eq:mc-update} $$
其中,$G_t$ 是时刻 $t$ 真实的回报,$\alpha$ 是步长参数,称之为常量 $\alpha$ MC。MC 需要等到一幕的结尾才能确定对 $V \left(S_t\right)$ 的增量(此时才能获得 $G_t$),而 TD 则只需要等到下一个时刻即可。在 $t+1$ 时刻,TD 使用观察到的收益 $R_{t+1}$ 和估计值 $V \left(S_{t+1}\right)$ 来进行一次有效更新:
$$ V\left(S_{t}\right) \gets V\left(S_{t}\right)+\alpha\left[R_{t+1}+\gamma V\left(S_{t+1}\right)-V\left(S_{t}\right)\right] \label{eq:td-update} $$
这种 TD 方法称之为 TD(0),算法的完整过程如下:
\begin{algorithm}
\caption{表格型 TD(0) 算法,用于估计 $V \approx v_{\pi}$}
\begin{algorithmic}
\REQUIRE 待评估策略 $\pi$
\STATE 对于所有 $s \in \mathcal{S}^+$,任意初始化 $V \left(s\right)$,其中 $V \left(\text{终止状态}\right) = 0$
\FOR{每一幕}
\STATE 初始化 $S$
\REPEAT
\STATE $A \gets$ 策略 $\pi$ 在状态 $S$ 下做出的决策动作
\STATE 执行动作 $A$,观测到 $R, S'$
\STATE $V\left(S\right) \gets V\left(S\right)+\alpha\left[R+\gamma V\left(S^{\prime}\right)-V\left(S\right)\right]$
\STATE $S \gets S'$
\UNTIL{$S$ 为终止状态}
\ENDFOR
\end{algorithmic}
\end{algorithm}
TD(0) 的更新在某种程度上基于已存在的估计,我们称之为一种自举法。
TD 和 MC 方法都能渐进地收敛于正确的预测,但两种方法谁收敛的更快,目前暂时未能证明。但在如下的随机任务上,TD 方法通常比常量 $\alpha$ MC 方法收敛得更快。假设如下 MRP 所有阶段都同中心 C 开始,每个时刻以相同的概率向左或向右移动一个状态。幕终止于最左侧或最右侧,终止于最右侧时有 +1 的收益,除此之外收益均为零。

由于这个任务没有折扣,因此每个状态的真实价值是从这个状态开始并终止于最右侧的概率,即 A 到 E 的概率分别为 $\frac{1}{6}, \frac{2}{6}, \frac{3}{6}, \frac{4}{6}, \frac{5}{6}$。
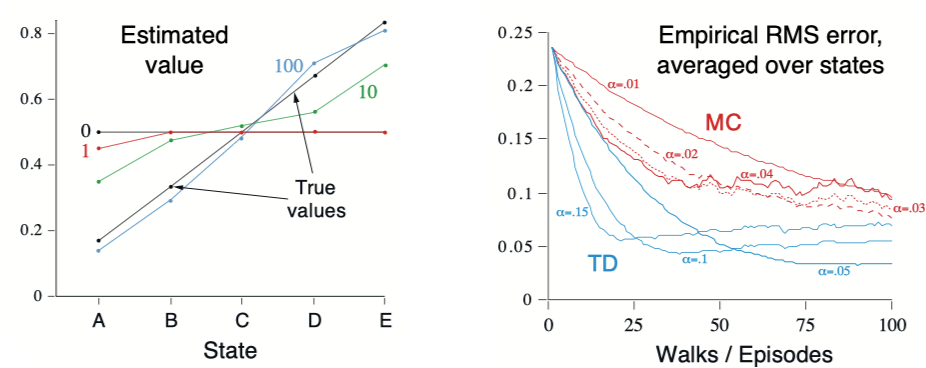
上图左侧显示了在经历了不同数量的幕采样序列之后,运行一次 TD(0) 所得到的价值估计。在 100 幕后,估计值已经非常接近真实值了。上图右侧显示了不同的 $\alpha$ 情况下学习到的价值函数和真实价值函数的均方根(RMS)误差,对于所有的 $s$,近似价值函数都被初始化为中间值 $V \left(s\right) = 0.5$,显示的误差是 5 个状态上运行 100 次的平均误差。
给定近似价值函数 $V$,在访问非终止状态的每个时刻 $t$,使用式 $\ref{eq:mc-update}$ 和 $\ref{eq:td-update}$ 计算相应的增量经验,产生新的总增量,以此类推,直到价值函数收敛。我们称这种方法为批量更新,因为只有在处理了整批的训练数据后才进行更新。批量蒙特卡洛方法总是找出最小化训练集上均方误差的估计,而批量 TD(0) 总是找出完全符合马尔可夫过程模型的最大似然估计参数。因此,MC 在非马尔可夫环境中更加高效,而 TD 在马尔可夫环境中更加高效。
DP,MC 和 TD 的状态价值更新回溯过程如下图所示:
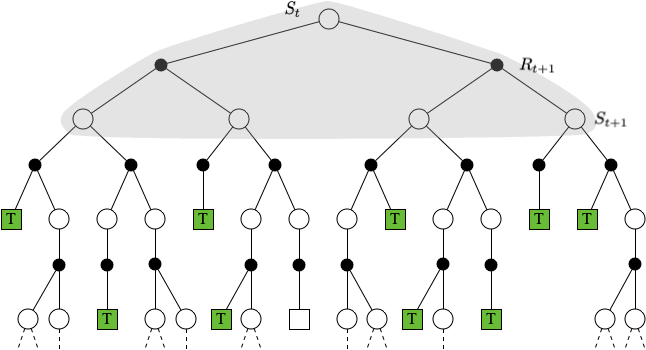
$$ \textbf{DP} \quad V\left(S_{t}\right) \leftarrow \mathbb{E}_{\pi}\left[R_{t+1}+\gamma V\left(S_{t+1}\right)\right] $$
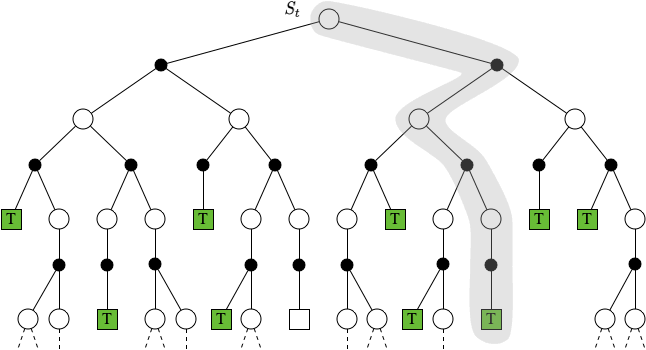
$$ \textbf{MC} \quad V\left(S_{t}\right) \leftarrow V\left(S_{t}\right)+\alpha\left(G_{t}-V\left(S_{t}\right)\right) $$
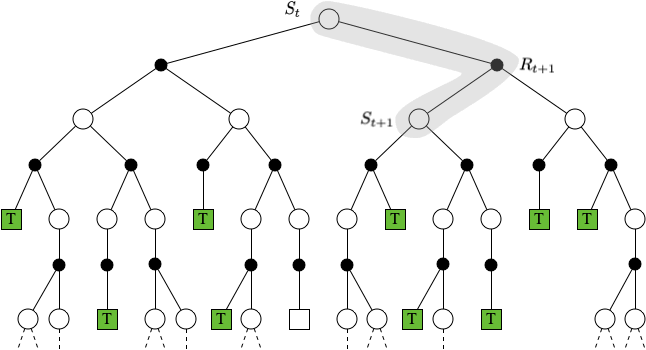
$$ \textbf{TD} \quad V\left(S_{t}\right) \leftarrow V\left(S_{t}\right)+\alpha\left(R_{t+1}+\gamma V\left(S_{t+1}\right)-V\left(S_{t}\right)\right) $$
时序差分控制
利用时序差分方法解决控制问题,我们依然采用广义策略迭代(GPI),只是在评估和预测部分采用时序差分方法。同蒙特卡洛方法一样,我们需要在试探和开发之间做出权衡,因此方法又划分为同轨策略和离轨策略。
Sarsa:同轨策略下的时序差分控制
在同轨策略中,我们需要对所有状态 $s$ 以及动作 $a$ 估计出在当前的行动策略下所有对应的 $q_{\pi} \left(s, a\right)$。确保状态值在 TD(0) 下收敛的定理同样也适用于对应的动作值的算法上
$$ Q\left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right)+\alpha\left[R_{t+1}+\gamma Q\left(S_{t+1}, A_{t+1}\right)-Q\left(S_{t}, A_{t}\right)\right] $$
每当从非终止状态的 $S_t$ 出现一次转移之后,就进行上述的一次更新,如果 $S_{t+1}$ 是终止状态,那么 $Q \left(S_{t+1}, A_{t+1}\right)$ 则定义为 0。这个更新规则用到了描述这个事件的五元组 $\left(S_t, A_t, R_{t+1}, S_{t+1}, A_{t+1}\right)$,因此根据这五元组将这个算法命名为 Sarsa。Sarsa 控制算法的一般形式如下:
\begin{algorithm}
\caption{Sarsa(同轨策略下的 TD 控制)算法,用于估计 $Q \approx q_*$}
\begin{algorithmic}
\STATE 对于所有 $s \in \mathcal{S}^+, a \in \mathcal{A} \left(s\right)$,任意初始化 $Q \left(s, a\right)$,其中 $Q \left(\text{终止状态}, \cdot\right) = 0$
\FOR{每一幕}
\STATE 初始化 $S$
\STATE 使用从 $Q$ 得到的策略(例如 $\epsilon-$ 贪心),在 $S$ 处选择 $A$
\REPEAT
\STATE 执行动作 $A$,观测到 $R, S'$
\STATE 使用从 $Q$ 得到的策略(例如 $\epsilon-$ 贪心),在 $S'$ 处选择 $A'$
\STATE $Q\left(S, A\right) \gets Q\left(S, A\right)+\alpha\left[R+\gamma Q\left(S', A'\right)-Q\left(S, A\right)\right]$
\STATE $S \gets S'$
\STATE $A \gets A'$
\UNTIL{$S$ 为终止状态}
\ENDFOR
\end{algorithmic}
\end{algorithm}
Q-Learning:离轨策略下的时序差分控制
离轨策略下的时序差分控制算法被称为 Q-Learning,其定义为:
$$ Q\left(S_{t}, A_{t}\right) \gets Q\left(S_{t}, A_{t}\right)+\alpha\left[R_{t+1}+\gamma \max_{a} Q\left(S_{t+1}, a\right)-Q\left(S_{t}, A_{t}\right)\right] $$
在这里,待学习的动作价值函数 $Q$ 采用了对最优动作价值函数 $q_*$ 的直接近似作为学习目标,而与用于生成智能体决策序例轨迹的行动策略是什么无关。Q-Learning 算法的流程如下:
\begin{algorithm}
\caption{Q-Learning(离轨策略下的 TD 控制)算法,用于估计 $\pi \approx \pi_*$}
\begin{algorithmic}
\STATE 对于所有 $s \in \mathcal{S}^+, a \in \mathcal{A} \left(s\right)$,任意初始化 $Q \left(s, a\right)$,其中 $Q \left(\text{终止状态}, \cdot\right) = 0$
\FOR{每一幕}
\STATE 初始化 $S$
\REPEAT
\STATE 使用从 $Q$ 得到的策略(例如 $\epsilon-$ 贪心),在 $S$ 处选择 $A$
\STATE 执行动作 $A$,观测到 $R, S'$
\STATE $Q\left(S, A\right) \gets Q\left(S, A\right)+\alpha\left[R+\gamma \max_{a} Q\left(S', a\right)-Q\left(S, A\right)\right]$
\STATE $S \gets S'$
\UNTIL{$S$ 为终止状态}
\ENDFOR
\end{algorithmic}
\end{algorithm}
期望 Sarsa
如果将 Q-Learning 中对于下一个“状态-动作”二元组取最大值这一步换成取期望,即更新规则为:
$$ \begin{aligned} Q\left(S_{t}, A_{t}\right) & \gets Q\left(S_{t}, A_{t}\right)+\alpha\left[R_{t+1}+\gamma \mathbb{E}_{\pi}\left[Q\left(S_{t+1}, A_{t+1}\right) \mid S_{t+1}\right]-Q\left(S_{t}, A_{t}\right)\right] \\ & \gets Q\left(S_{t}, A_{t}\right)+\alpha\left[R_{t+1}+\gamma \sum_{a} \pi\left(a \mid S_{t+1}\right) Q\left(S_{t+1}, a\right)-Q\left(S_{t}, A_{t}\right)\right] \end{aligned} $$
给定下一个状态 $S_{t+1}$,这个算法确定地向期望意义上的 Sarsa 算法所决定的方向上移动,因此这个算法被称为期望 Sarsa。期望 Sarsa 在计算上比 Sarsa 更加复杂,但它消除了因为随机选择 $A_{t+1}$ 而产生的方差。
双学习
在上述算法中,在估计值的基础上进行最大化也可以被看做隐式地对最大值进行估计,而这会产生一个显著的正偏差。假设在状态 $s$ 下可以选择多个动作 $a$,这些动作在该状态下的真实价值 $q \left(s, a\right)$ 全为零,但他们的估计值 $Q \left(s, a\right)$ 是不确定的,可能大于零也可能小于零。真实值的最大值是零,但估计值的最大值是正数,因此就产生了正偏差,我们称其为最大化偏差。
我们用下例进行说明,在如下这个 MDP 中有两个非终止节点 A 和 B。每幕都从 A 开始并选择向左或向右的动作。向右则会立即转移到终止状态并得到值为 0 的收益和回报。向左则会是状态转移到 B,得到的收益也是 0。而在 B 这个状态下有很多种可能的动作,每种动作被选择后会立刻停止并得到一个从均值为 -0.1 方差为 1.0 的分布中采样得到的收益。
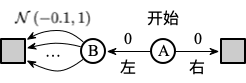
因此,任何一个以向左开始的轨迹的期望回报均为 -0.1,则在 A 这个状态中根本就不该选择向左。然而使用 $\epsilon-$ 贪心策略来选择动作的 Q-Learning 算法会在开始阶段非常明显地选择向左这个动作。即使在算法收敛到稳定时,它选择向左这个动作的概率也比最优值高了大约 5%,如下图所示:
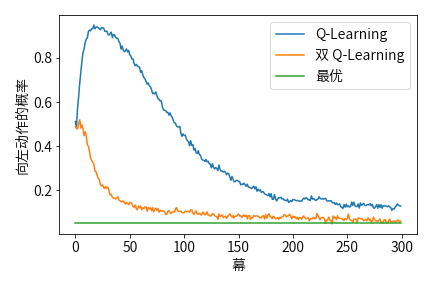
解决该问题的一种方法为双学习。如果们将样本划分为两个集合,并用它们学习两个独立的对真实价值 $q \left(a\right), \forall a \in A$ 的估计 $Q_1 \left(a\right)$ 和 $Q_2 \left(a\right)$。则我们可以使用其中一个 $Q_1$ 来确认最大的动作 $A^* = \arg\max_a Q_1 \left(a\right)$,用另一个 $Q_2$ 来计算其价值的估计 $Q_2 \left(A^*\right) = Q_2 \left(\arg\max_a Q_1 \left(a \right)\right)$。由于 $\mathbb{E} \left[Q_2 \left(A^*\right)\right] = q \left(A^*\right)$,因此这个估计是无偏的。我们可以交换两个估计 $Q_1 \left(a\right)$ 和 $Q_2 \left(a\right)$ 的角色再执行一遍上面的过程,就可以得到另一个无偏的估计 $Q_1 \left(\arg\max_a Q_2 \left(a\right)\right)$。
双学习的 Q-Learning 版本为 Double Q-Learning。Double Q-Learning 在学习时会以 0.5 的概率进行如下更新:
$$ Q_{1}\left(S_{t}, A_{t}\right) \leftarrow Q_{1}\left(S_{t}, A_{t}\right)+\alpha\left[R_{t+1}+\gamma Q_{2}\left(S_{t+1}, \underset{a}{\arg \max } Q_{1}\left(S_{t+1}, a\right)\right)-Q_{1}\left(S_{t}, A_{t}\right)\right] $$
以 0.5 的概率交换 $Q_1$ 和 $Q_2$ 的角色进行同样的更新。使用 $\epsilon-$ 贪心策略的 Double Q-Learning 的完整算法流程如下:
\begin{algorithm}
\caption{Double Q-Learning,用于估计 $Q_1 \approx Q_2 \approx q_*$}
\begin{algorithmic}
\REQUIRE 步长 $\alpha \in \left(0, 1\right]$,很小的 $\epsilon > 0$
\STATE 对于所有 $s \in \mathcal{S}^+, a \in \mathcal{A} \left(s\right)$,任意初始化 $Q_1 \left(s, a\right), Q_2 \left(s, a\right)$,其中 $Q \left(\text{终止状态}, \cdot\right) = 0$
\FOR{每一幕}
\STATE 初始化 $S$
\REPEAT
\STATE 基于 $Q_1 + Q_2$ 使用 $\epsilon-$ 贪心策略在 $S$ 处选择 $A$
\STATE 执行动作 $A$,观测到 $R, S'$
\IF{$Random(0, 1] > 0.5$}
\STATE $Q_{1}(S, A) \leftarrow Q_{1}(S, A)+\alpha\left(R+\gamma Q_{2}\left(S^{\prime}, \arg \max _{a} Q_{1}\left(S^{\prime}, a\right)\right)-Q_{1}(S, A)\right)$
\ELSE
\STATE $Q_{2}(S, A) \leftarrow Q_{2}(S, A)+\alpha\left(R+\gamma Q_{1}\left(S^{\prime}, \arg \max _{a} Q_{2}\left(S^{\prime}, a\right)\right)-Q_{2}(S, A)\right)$
\ENDIF
\STATE $S \gets S'$
\UNTIL{$S$ 为终止状态}
\ENDFOR
\end{algorithmic}
\end{algorithm}
Taxi-v3 示例
我们以 Taxi-v3 为示例来测试 Sarsa,Q-Learning 和 期望 Sarsa 三种不同的算法。Taxi-v3 包含了一个 5x5 的网格,即 25 个可能的位置,我们需要驾驶一辆出租车分别在图中的 R、G、Y、B 四个位置接送乘客。客人共计存在 4 种可能的上车点,4 种可能的下车点,同时考虑出租车的位置,整个环境共有 $5 \times 5 \times \left(4 + 1\right) \times 4 = 500$ 种可能的状态,如下图所示:

出租车需要根据当前环境采取不同的动作,共计 6 种可能的动作:向南走,向北走,向东走,向西走,接上乘客,放下乘客。由于环境中存在墙,出租车每次撞墙不会发生任何移动。每一步动作默认 -1 的回报,当选择错误的地点接上或放下乘客时获得 -10 的回报,在成功运送一个客人后获得 +20 的回报。
分别利用 Sarsa,Q-Learning 和 期望 Sarsa 三种不同的算法训练模型,我们以 100 幕作为窗口计算平均回报,前 1000 个平均回报的对比结果如下图所示:
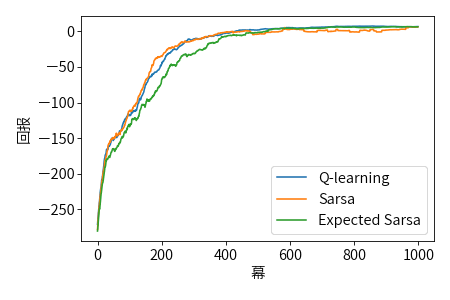
Taxi-v3 的成绩排行榜可参见 这里。利用训练好的模型执行预测的效果如下图所示:

本文示例代码实现请参见这里。
-
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press. ↩︎
-
CS234: Reinforcement Learning http://web.stanford.edu/class/cs234/index.html ↩︎
-
UCL Course on RL https://www.davidsilver.uk/teaching ↩︎