最近邻搜索(Nearest Neighbor Search)是指在一个确定的距离度量和一个搜索空间内寻找与给定查询项距离最小的元素。更精确地,对于一个包含 $N$ 个元素的集合 $\mathcal{X} = \left\{\mathbf{x}_1, \mathbf{x}_2, \cdots, \mathbf{x}_n\right\}$,给定查询项 $\mathbf{q}$ 的最近邻 $NN \left(\mathbf{q}\right) = \arg\min_{\mathbf{x} \in \mathcal{X}} dist \left(\mathbf{q}, \mathbf{x}\right)$,其中 $dist \left(\mathbf{q}, \mathbf{x}\right)$ 为 $\mathbf{q}$ 和 $\mathbf{x}$ 之间的距离。由于维数灾难,我们很难在高维欧式空间中以较小的代价找到精确的最近邻。近似最近邻搜索(Approximate Nearest Neighbor Search)则是一种通过牺牲精度来换取时间和空间的方式从大量样本中获取最近邻的方法。
精确搜索
暴力查找(Brute-force Search)
最简单的最邻近搜索便是遍历整个点集,计算它们和目标点之间的距离,同时记录目前的最近点。这样的算法较为初级,可以为较小规模的点集所用,但是对于点集的尺寸和空间的维数稍大的情况则不适用。对于 $D$ 维的 $N$ 个样本而言,暴力查找方法的复杂度为 $O \left(DN\right)$。
k-D 树
k-D 树(k-Dimesion Tree)1 是一种可以高效处理 $k$ 维空间信息的数据结构。k-D 树具有二叉搜索树的形态,二叉搜索树上的每个结点都对应 $k$ 维空间内的一个点。其每个子树中的点都在一个 $k$ 维的超长方体内,这个超长方体内的所有点也都在这个子树中。k-D 树的构建过程如下:
- 若当前超长方体中只有一个点,返回这个点。
- 选择一个维度,将当前超长方体按照这个维度分割为两个超长方体。
- 选择一个切割点,将小于这个点的归入其中一个超长方体(左子树),其余归入另一个超长方体(右子树)。
- 递归地对分出的两个超长方体构建左右子树。
一个 $k = 2$ 的例子如下:
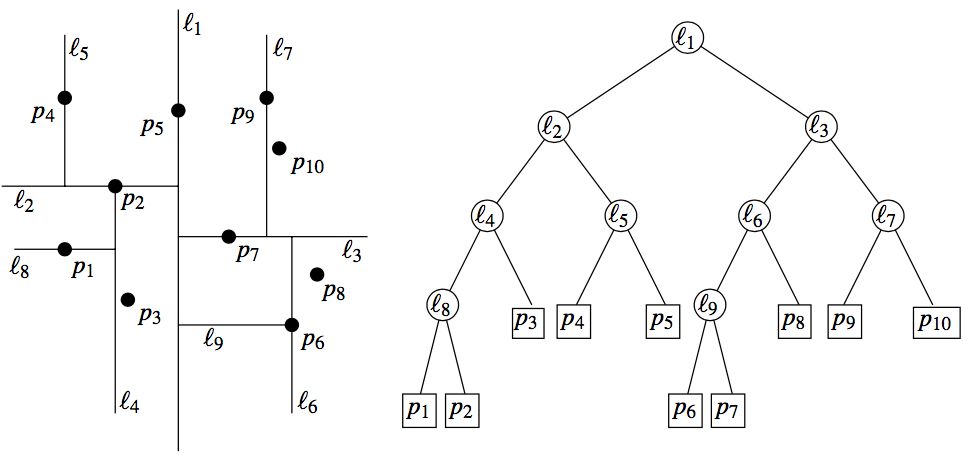
构建 k-D 树目前最优方法的时间复杂度为 $O \left(n \log n\right)$。对于单次查询,当 $2$ 维时,查询时间复杂度最优为 $O \left(\log n\right)$,最坏为 $O \left(\sqrt{n}\right)$,扩展至 $k$ 维,最坏为 $O \left(n^{1 - \frac{1}{k}}\right)$。k-D 树对于低维度最近邻搜索比较好,但当 $k$ 增长到很大时,搜索的效率就变得很低,这也是“维数灾难”的一种体现。
Ball 树
为了解决 k-D 树在高维数据上的问题,Ball 树 2 结构被提了出来。k-D 树是沿着笛卡尔积(坐标轴)方向迭代分割数据,而 Ball 树是通过一系列的超球体分割数据而非超长方体。Ball 树的构建过程如下:
- 若当前超球体中只有一个点,返回这个点。
- 定义所有点的质心为
$c$,离质心$c$最远的点为$c_1$,离$c_1$最远的点为$c_2$。 - 将
$c_1$和$c_2$作为聚类中心对数据点进行聚类得到两个簇$\left(c_1, r_1\right), \left(c_2, r_2\right)$,将其归入左子树和右子树,其中$r$为超球的半径。 - 递归的对分出的两个超球体构建左右子树。
一个二维的例子如下:
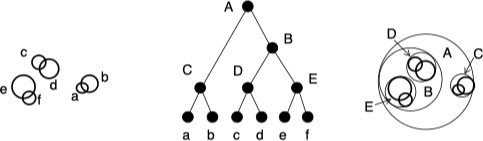
每个点必须只能隶属于一个簇,但不同簇的超球体之间是可以相交的。在利用 Ball 树进行查询时,首先自上而下的找到包含查询点的叶子簇 $\left(c, r\right)$,在这个簇中找到距离查询点最近的观测点,这两个点的距离 $d_{upper}$ 即为最近邻的距离上界。之后检查该叶子簇的所有兄弟簇是否包含比这个上界更小的观测点,在检查时,如果查询节点距离兄弟簇圆心的距离大于兄弟簇的半径与之前计算的上界 $d_{upper}$ 之和,则这个兄弟节点不可能包含所需要的最近邻。
构建 Ball 树的时间复杂度为 $O \left(n \left(\log n\right)^2\right)$,查询时间复杂度为 $O \left(\log \left(n\right)\right)$。
近似搜索
基于哈希的算法
基于哈希的算法的目标是将一个高维数据点转换为哈希编码的表示方式,主要包含两类方法:局部敏感哈希(Local Sensitive Hash, LSH)和哈希学习(Learning to Hash, L2H)。
局部敏感哈希
局部敏感哈希采用的是与数据无关的哈希函数,也就是说整个学习处理过程不依赖于任何的数据内容信息。LSH 通过一个局部敏感哈希函数将相似的数据点以更高的概率映射到相同的哈希编码上去。这样我们在进行查询时就可以先找到查询样本落入那个哈希桶,然后再在这个哈希桶内进行遍历比较就可以找到最近邻了。
要使得相近的数据点通过哈希后落入相同的桶中,哈希函数需要满足如下条件:
- 如果
$d \left(x, y\right) \leq d_1$,则$Pr \left[h \left(x\right), h \left(y\right)\right] \geq p_1$。 - 如果
$d \left(x, y\right) \geq d_2$,则$Pr \left[h \left(x\right), h \left(y\right)\right] \leq p_2$。
其中,$x, y \in \mathbb{R}^n$ 表示 $n$ 维度数据点,$d \left(x, y\right)$ 表示 $x, y$ 之间的距离,$h$ 为哈希函数。满足上述两个条件的哈希函数称为是 $\left(d_1, d_2, p_1, p_2\right)$ 敏感的。
- MinHash(Jaccard 距离)
MinHash 算法的思路是:采用一种哈希函数将元素的位置均匀打乱,然后在新顺序下每个集合的第一个元素作为该集合的特征值。我们以 $s_1 = \left\{a, d\right\}$,$s_2 = \left\{c\right\}$,$s_3 = \left\{b, d, e\right\}$,$s_4 = \left\{a, c, d\right\}$ 为例,集合中可能的元素为 $\left\{a, b, c, d, e\right\}$,则这四个集合可以表示为:
| 元素 | $s_1$ |
$s_2$ |
$s_3$ |
$s_4$ |
|---|---|---|---|---|
$a$ |
1 | 0 | 0 | 1 |
$b$ |
0 | 0 | 1 | 0 |
$c$ |
0 | 1 | 0 | 1 |
$d$ |
1 | 0 | 1 | 1 |
$e$ |
0 | 0 | 1 | 0 |
对矩阵进行随机打乱后有:
| 元素 | $s_1$ |
$s_2$ |
$s_3$ |
$s_4$ |
|---|---|---|---|---|
$b$ |
0 | 0 | 1 | 0 |
$e$ |
0 | 0 | 1 | 0 |
$a$ |
1 | 0 | 0 | 1 |
$d$ |
1 | 0 | 1 | 1 |
$c$ |
0 | 1 | 0 | 1 |
我们利用每个集合的第一个元素作为该集合的特征值,则有 $h \left(s_1\right) = a$,$h \left(s_2\right) = c$,$h \left(s_3\right) = b$,$h \left(s_4\right) = a$,可以看出 $h \left(s_1\right) = h \left(s_4\right)$。MinHash 能够保证在哈希函数均匀分布的情况下,哈希值相等的概率等于两个集合的 Jaccard 相似度,即:
$$ Pr \left(MinHash \left(s_1\right) = MinHash \left(s_2\right)\right) = Jaccard \left(s_1, s_2\right) $$
- SimHash(汉明距离)
SimHash 是由 Manku 等人 3 提出的一种用于用于进行网页去重的哈希算法。SimHash 作为局部敏感哈希算法的一种其主要思想是将高维特征映射到低维特征,再通过两个向量的汉明距离来确定是否存在重复或相似。算法步骤如下:
- 对文本进行特征抽取(例如:分词),并为每个特征赋予一定的权重(例如:词频)。
- 计算每个特征的二进制哈希值。
- 计算加权后的哈希值,当哈希值为 1 时,则对应位置为
$w_i$,否则为$-w_i$,其中$w_i$为该特征对应的权重。 - 将所有特征加权后的哈希值按对应的位置进行累加合并。
- 如果累加位置大于 0 则置为 1,否则置为 0,最终得到哈希结果。
算法流程如下图所示:
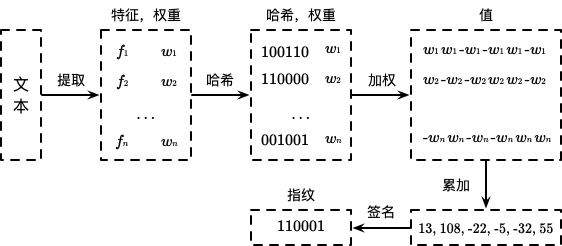
在得到 SimHash 的值后,我们可以通过比较之间的汉明距离来判断相似性。为了提高海量数据的去重效率,以 64 位指纹为例,我们可以将其切分为 4 份 16 位的数据块,根据鸽巢原理,汉明距离为 3 的两个文档必定有一个数据块是相等的。将这 4 分数据利用 KV 数据库和倒排索引进行存储,Key 为 16 位的截断指纹,Value 为剩余的指纹集合,从而提高查询的效率。同时可以选择 16,8 和 4 位进行索引,位数越小越精确,但所需的存储空间越大。
- p-stable 分布(欧式距离)
当一个在 $\Re$ 上的分布 $\mathcal{D}$ 为 $p\text{-stable}$ 时,存在 $p \geq 0$ 使得对于任意 $n$ 个实数 $v_1, \cdots, v_n$ 和独立同分布 $\mathcal{D}$ 下的变量 $X_1, \cdots, X_n$,有随机变量 $\sum_{i}{v_i X_i}$ 和 $\left(\sum_{i}{\left|v_i\right|^p}\right)^{1/p} X$ 具有相同的分布,其中 $X$ 为分布 $\mathcal{D}$ 下的随机变量 4。常见的 p-stable 分布有:
- 柯西分布:密度函数为
$c \left(x\right) = \dfrac{1}{\pi} \dfrac{1}{1 + x^2}$,为$1\text{-stable}$。 - 正态分布:密度函数为
$g \left(x\right) = \dfrac{1}{\sqrt{2 \pi}} e^{-x^2 / 2}$,为$2\text{-stable}$。
p-stable 分布主要可以用于估计 $\left\|v\right\|_p$,对于两个相似的 $v_1, v_2$,它们应该具有更小的 $\left\|v_1 - v_2\right\|_p$,也就是对应的哈希值有更大的概率发生碰撞。对于 $v_1, v_2$,距离的映射 $a \cdot v_1 - a \cdot v_2$ 和 $\left\|v_1 - v_2\right\|_p \cdot X$ 具有相同的分布。$a \cdot v$ 将向量 $v$ 映射到实数集,如果将实轴以宽度 $w$ 进行等分,$a \cdot v$ 落在哪个区间中就将其编号赋予它,这样构造的哈希函数具有局部保持特性。构造的哈希函数族的形式为:
$$ h_{a, b} \left(v\right) = \left\lfloor \dfrac{a \cdot v + b}{w} \right\rfloor $$
其中,向量 $a$ 的元素 $a_i \sim N \left(0, 1\right)$,$b \sim U \left(0, w\right)$。令 $c = \left\|u - v \right\|_p$,则两个向量在被分配到一个桶中的概率为:
$$ Pr \left[h_{a, b} \left(u\right) = h_{a, b} \left(v\right)\right] = \int_{0}^{w} \dfrac{1}{c} \cdot f_p \left(\dfrac{t}{u}\right) \left(1 - \dfrac{t}{w}\right) dt $$
其中,$f_p$ 为概率密度函数。从上式中不难看出,随着距离 $c$ 的减小,两个向量发生碰撞的概率增加。
- 相关问题
局部敏感哈希可以在次线性时间内完成搜索,但缺点在于需要比较长的比特哈希码和比较多的哈希表才能达到预期的性能。
在单表哈希中,当哈希编码位数 $K$ 过小时,每个哈希桶中数据个数较多,从而会增加查询的响应时间。当哈希编码位数 $K$ 较大时,查询样本同最近邻落入同一个桶中的概率会很小。针对这个问题,我们可以通过重复 $L$ 次来增加最近邻的召回率。这个操作可以转化为构建 $L$ 个哈希表,给定一个查询样本,我们可以找到 $L$ 个哈希桶,然后再遍历这 $L$ 个哈希桶中的数据。但这样会增加内存的消耗,因此需要选择合理的 $K$ 和 $L$ 来获得更好的性能。
Multi-probe LSH 5 引入了一种新的策略解决召回的问题。Multi-probe LSH 不仅仅会遍历查询样本所在桶内的元素,同时还会查询一些其他有可能包含最近邻的桶,从而在避免构建多个哈希表的情况下增加召回率。
哈希学习
哈希学习(Learning to Hash)是由 Salakhutdinov 和 Hinton 6 引入到机器学习领域,通过机器学习机制将数据映射成二进制串的形式,能显著减少数据的存储和通信开销,从而有效提高学习系统的效率 7。从原空间中的特征表示直接学习得到二进制的哈希编码是一个 NP-Hard 问题。现在很多的哈希学习方法都采用两步学习策略:
- 先对原空间的样本采用度量学习(Metric Learning)进行降维,得到 1 个低维空间的实数向量表示。
- 对得到的实数向量进行量化(即离散化)得到二进制哈希码。
现有的方法对第二步的处理大多很简单,即通过某个阈值函数将实数转换成二进制位。通常使用的量化方法为 1 个阈值为 0 的符号函数,即如果向量中某个元素大于 0,则该元素被量化为 1,否则如果小于或等于 0,则该元素被量化为 0。
哈希学习相关的具体算法不再一一展开,更多细节请参见下文提供的相关 Survey。
矢量量化算法
矢量量化(Vector Quantization)是信息论中一种用于数据压缩的方法,其目的是减少表示空间的维度。一个量化器可以表示为由 $D$ 维向量 $x \in \mathbb{R}^D$ 到一个向量 $q \left(x\right) \in \mathcal{C} = \left\{c_i; i \in \mathcal{I}\right\}$ 的映射 $q$,其中下标集合 $\mathcal{I}$ 为有限集合,即 $\mathcal{I} = 0, \cdots, k-1$。$c_i$ 称之为形心(centroids),$\mathcal{C}$ 称之为大小为 $k$ 的码本(codebook)。映射后的向量到一个给定下标 $i$ 的集合 $\mathcal{V}_i \triangleq \left\{x \in \mathbb{R}^D: q \left(x\right) = c_i\right\}$(Voronoi),称之为一个单元(cell)。
以一个图像编码为例,我们通过 K-Means 算法得到 $k$ 个 centroids,然后用这些 centroids 的像素值来替换对应簇中所有点的像素值。当 $k = 2, 10, 100$ 时,压缩后的图像和原始图像的对比结果如下图所示:

当 $k = 100$ 时,压缩后的图像和原始图像已经非常接近了,相关代码请参见这里。
矢量量化以乘积量化(Product Quantization,PQ)最为典型,乘积量化的核心思想还是聚类,乘积量化生成码本和量化过程如下图所示:
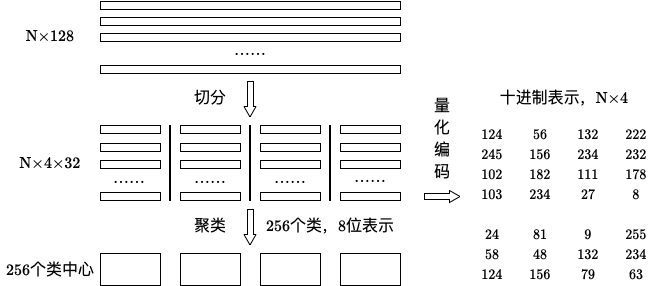
在训练阶段,以维度为 128 的 $N$ 个样本为例,我们将其切分为 4 个子空间,则每个子空间的维度为 32 维。对每一个子空间利用 K-Means 对其进行聚类,令聚类个数为 256,这样每个子空间就能得到一个 256 大小的码本。样本的每个子段都可以用子空间的聚类中心来近似,对应的编码即为类中心的 ID。利用这种编码方式可以将样本用一个很短的编码进行表示,从而达到量化的目的。
在查询阶段,我们将查询样本分成相同的子段,然后在每个子空间中计算子段到该子空间中所有聚类中心的距离,这样我们就得到了 $4 \times 256$ 个距离。在计算某个样本到查询样本的距离时,我们仅需要从计算得到的 4 组距离中将对应编码的距离取出相加即可,所有距离计算完毕排序后即可得到结果。
乘积量化有两种计算距离的方式 8:对称距离和非对称距离,如下图所示:
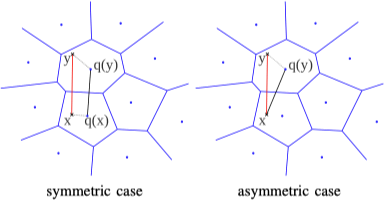
对于 $x$ 和 $y$ 的距离 $d \left(x, y\right)$,对称距离利用 $d \left(q \left(x\right), q \left(y\right)\right)$ 进行估计,非对称距离利用 $d \left(x, q \left(y\right)\right)$ 进行估计。对称距离和非对称距离在不同阶段的时间复杂度如下表所示:
| 对称距离 | 非对称距离 | |
|---|---|---|
编码 $x$ |
$k^* D$ |
0 |
计算 $d \left(u_j \left(x\right), c_{j, i}\right)$ |
0 | $k^* D$ |
对于 $y \in \mathcal{Y}$,计算 $\hat{d} \left(x, y\right)$ 或 $\tilde{d} \left(x, y\right)$ |
$nm$ |
$nm$ |
查找最小 $k$ 个距离 |
$n + k$ |
$\log k \log \log n$ |
其中,$k^*$ 为 centroids 个数,$D$ 为向量维度,$n$ 为样本个数,$m$ 为分割个数。通常情况下我们采用非对称距离,其更接近真实距离。
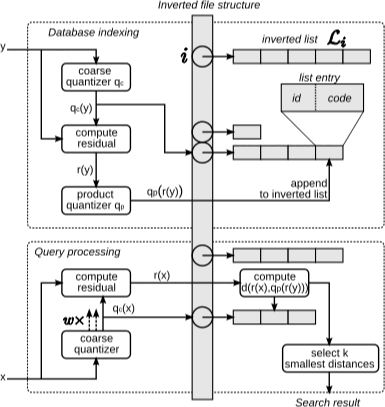
IVFADC 8 是乘积量化的的加速版本,乘积量化在计算距离时仍需逐个遍历相加计算。倒排乘积量化首先对 $N$ 个样本采用 K-Means 进行聚类,此处的聚类中心相比乘积量化应设置较小的数值。在得到聚类中心后,针对每一个样本 $x_i$ 找到距离最近的类中心 $c_i$,两者相减后得到残差 $x_i - c_i$,然后对残差再进行乘积量化的全过程。在查询阶段,通过先前较粗力度的量化快速定位隶属于哪一个 $c_i$,然后在 $c_i$ 区域利用乘积量化获取最终结果。整个流程如下图所示:
Optimized Product Quantization (OPQ) 9 是乘积量化的一个优化方法。通常用于检索的原始特征维度较高,实践中利用乘积量化之前会对高维特征利用 PCA 等方法进行降维处理。这样在降低维度的时候还能够使得对向量进行子段切分的时候各个维度不相关。在利用 PCA 降维后,采用顺序切分子段仍存在一些问题,以 Iterative Quantization (ITQ) 10 中的一个二维平面例子来说明,如下图所示:
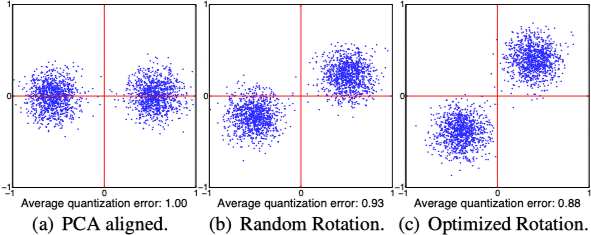
在利用乘积量化进行编码时,对于切分的各个子空间,应尽可能使得各个子空间的方差接近。上图中 $(a)$ 图在 x 和 y 轴上的方差较大,而 $(c)$ 图在两个方向上比较接近。OPQ 致力解决的问题就是对各个子空间方差上的均衡,OPQ 对于该问题的求解分为非参数求解方法和参数求解方法两种,更多算法细节请参见 ITQ 和 OPQ 原文。
基于图的算法
NSW(Navigable Small World)11 算法是一种由 Malkov 等人提出的基于图的索引的方法。我们将 Navigable Small World 网络表示为一个图 $G \left(V, E\right)$,其中数据集合 $X$ 的点被唯一映射到集合 $V$ 中的一条边,边集 $E$ 由构造算法确定。对于与一个节点 $v_i$ 共享一条边的所有节点,我们称之为该节点的“友集”。
之后我们可以利用一个贪婪搜索的变种算法实现一个基本的 KNN 搜索算法。通过选择友集中未被访问过的距离查询样本最近的节点,可以在图中一个接一个的访问不同的节点,直到达到停止准则。整个过程如下图所示:
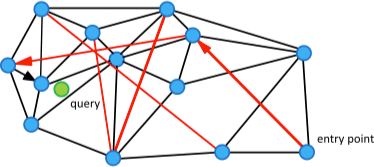
上图中的边扮演着两种不同的角色:
- 短距离边的子集作为 Delaunay 图的近似用于贪婪搜索算法。
- 长距离边的子集用于对数尺度的贪婪搜索,负责构造图的 Navigable Small World 属性。
其中,黑色的边为短距离边,红色的边为长距离边,箭头为迭代查询路径。整个结构的构建可以通过元素的连续插入实现,对于新的元素,我们从当前结构中找到最接近的邻居集合与之相连。随着越来越多的元素插入到结构中,之前的短距离连接就变成了长距离连接。
NSW 的 KNN 查询过程如下所示:
\begin{algorithm}
\caption{NSW 的 KNN 查询}
\begin{algorithmic}
\REQUIRE 查询样本 $q$,查询结果数量 $k$,最大迭代次数 $m$
\STATE $V_{cand} \gets \varnothing, V_{visited} \gets \varnothing, V_{res} \gets \varnothing$
\FOR{$i \gets 1$ \TO $m$}
\STATE $V_{tmp} \gets \varnothing$
\STATE $v_{rand} \gets $ 随机初始节点
\STATE $V_{cand} \gets V_{cand} \cup v_{rand}$
\WHILE{True}
\STATE $v_c \gets V_{cand}$ 中距离 $q$ 最近的元素
\STATE $V_{cand} \gets V_{cand} \setminus v_c$
\IF{$v_c$ 比结果中的 $k$ 个元素距离 $q$ 还远}
\BREAK
\ENDIF
\FOR{$v_e \in v_c$ 的“友集”}
\IF{$v_e \notin V_{visited}$}
\STATE $V_{visited} \gets V_{visited} \cup v_e, V_{cand} \gets V_{cand} \cup v_e, V_{tmp} \gets V_{tmp} \cup v_e$
\ENDIF
\ENDFOR
\ENDWHILE
\STATE $V_{res} \gets V_{res} \cup V_{tmp}$
\ENDFOR
\RETURN{$V_{res}$ 中与查询样本最近的 $k$ 个元素}
\end{algorithmic}
\end{algorithm}
HNSW(Hierarchical Navigable Small World)12 是对 NSW 的一种改进。HNSW 的思想是根据连接的长度(距离)将连接划分为不同的层,然后就可以在多层图中进行搜索。在这种结构中,搜索从较长的连接(上层)开始,贪婪地遍历所有元素直到达到局部最小值,之后再切换到较短的连接(下层),然后重复该过程,如下图所示:
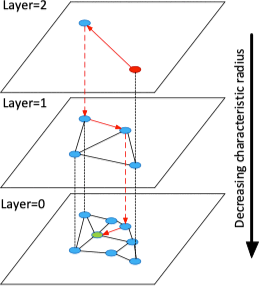
利用这种结构可以将原来 NSW 的多重对数(Polylogarithmic)计算复杂度降低至对数(Logarithmic)复杂度。更多关于数据插入和搜索的细节请参见原文。
NSG 13 提出了一种新的图结构 Monotonic Relative Neighborhood Graph (MRNG) 用于保证一个平均的低搜索时间复杂度(接近对数复杂度)。同时为了进一步降低索引复杂度,作者从确保连接性、降低平均出度、缩短搜索路径和降低索引大小 4 个方面考虑,提出了一个用于近似 MRNG 的 Spreading-out Graph (NSG)。
基于图的方法 HNSW 和基于乘积量化的方法 OPQ 之间的特性对比如下:
| 特点 | OPQ | HNSW |
|---|---|---|
| 内存占用 | 小 | 大 |
| 召回率 | 较高 | 高 |
| 数据动态增删 | 灵活 | 不易 |
本文部分内容参考自 图像检索:向量索引。
算法对比
常用算法的开源实现的评测如下,更多评测结果请参见 erikbern/ann-benchmarks。
")
")
开放资源
Survey
- A Survey on Learning to Hash 14
- A Survey on Nearest Neighbor Search Methods 15
- An Investigation of Practical Approximate Nearest Neighbor Algorithms 16
- Approximate Nearest Neighbor Search on High Dimensional Data - Experiments, Analyses, and Improvement 17
- Binary Hashing for Approximate Nearest Neighbor Search on Big Data: A Survey 18
- Hashing for Similarity Search: A Survey 19
开源库
| 库 | API |
|---|---|
| spotify/annoy | C++, Python, Go |
| vioshyvo/mrpt | C++, Python, Go |
| pixelogik/NearPy | Python |
| aaalgo/kgraph | C++, Python |
| nmslib/nmslib | C++, Python |
| nmslib/hnswlib | C++, Python |
| lyst/rpforest | Python |
| facebookresearch/faiss | C++, Python |
| ekzhu/datasketch | Python |
| lmcinnes/pynndescent | Python |
| yahoojapan/NGT | C, C++, Python, Go, Ruby |
| microsoft/SPTAG | C++, Python |
| puffinn/puffinn | C++, Python |
| kakao/n2 | C++, Python, Go |
| ZJULearning/nsg | C++ |
开源搜索引擎
| 搜索引擎 | API |
|---|---|
| milvus-io/milvus | C, C++, Python, Java Go, Node.js, RESTful API |
| vearch/vearch | Python, Go |
评测
-
Bentley, J. L. (1975). Multidimensional binary search trees used for associative searching. Communications of the ACM, 18(9), 509-517. ↩︎
-
Omohundro, S. M. (1989). Five balltree construction algorithms (pp. 1-22). Berkeley: International Computer Science Institute. ↩︎
-
Manku, G. S., Jain, A., & Das Sarma, A. (2007, May). Detecting near-duplicates for web crawling. In Proceedings of the 16th international conference on World Wide Web (pp. 141-150). ↩︎
-
Datar, M., Immorlica, N., Indyk, P., & Mirrokni, V. S. (2004, June). Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the twentieth annual symposium on Computational geometry (pp. 253-262). ↩︎
-
Lv, Q., Josephson, W., Wang, Z., Charikar, M., & Li, K. (2007, September). Multi-probe LSH: efficient indexing for high-dimensional similarity search. In Proceedings of the 33rd international conference on Very large data bases (pp. 950-961). ↩︎
-
Salakhutdinov, Ruslan, and Geoffrey Hinton. “Semantic hashing.” International Journal of Approximate Reasoning 50.7 (2009): 969-978. ↩︎
-
李武军, & 周志华. (2015). 大数据哈希学习: 现状与趋势. 科学通报, 60(5-6), 485-490. ↩︎
-
Jegou, H., Douze, M., & Schmid, C. (2010). Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence, 33(1), 117-128. ↩︎ ↩︎
-
Ge, T., He, K., Ke, Q., & Sun, J. (2013). Optimized product quantization. IEEE transactions on pattern analysis and machine intelligence, 36(4), 744-755. ↩︎
-
Gong, Y., Lazebnik, S., Gordo, A., & Perronnin, F. (2012). Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE transactions on pattern analysis and machine intelligence, 35(12), 2916-2929. ↩︎
-
Malkov, Y., Ponomarenko, A., Logvinov, A., & Krylov, V. (2014). Approximate nearest neighbor algorithm based on navigable small world graphs. Information Systems, 45, 61-68. ↩︎
-
Malkov, Y. A., & Yashunin, D. A. (2018). Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE transactions on pattern analysis and machine intelligence. ↩︎
-
Fu, C., Xiang, C., Wang, C., & Cai, D. (2019). Fast approximate nearest neighbor search with the navigating spreading-out graph. Proceedings of the VLDB Endowment, 12(5), 461-474. ↩︎
-
Wang, J., Zhang, T., Sebe, N., & Shen, H. T. (2017). A survey on learning to hash. IEEE transactions on pattern analysis and machine intelligence, 40(4), 769-790. ↩︎
-
Reza, M., Ghahremani, B., & Naderi, H. (2014). A Survey on nearest neighbor search methods. International Journal of Computer Applications, 95(25), 39-52. ↩︎
-
Liu, T., Moore, A. W., Yang, K., & Gray, A. G. (2005). An investigation of practical approximate nearest neighbor algorithms. In Advances in neural information processing systems (pp. 825-832). ↩︎
-
Li, W., Zhang, Y., Sun, Y., Wang, W., Li, M., Zhang, W., & Lin, X. (2019). Approximate nearest neighbor search on high dimensional data-experiments, analyses, and improvement. IEEE Transactions on Knowledge and Data Engineering. ↩︎
-
Cao, Y., Qi, H., Zhou, W., Kato, J., Li, K., Liu, X., & Gui, J. (2017). Binary hashing for approximate nearest neighbor search on big data: A survey. IEEE Access, 6, 2039-2054. ↩︎
-
Wang, J., Shen, H. T., Song, J., & Ji, J. (2014). Hashing for similarity search: A survey. arXiv preprint arXiv:1408.2927. ↩︎