网络基础算法
最短路径
最短路径(shortest path)算法是寻找两个顶点之间的最短路径,寻找网络中最短路径的标准算法称为广度优先搜索(breadth-first search)。算法的基本思想如下图所示:
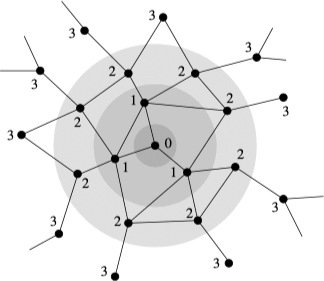
根据广度优先搜索的基本思想,不难证明距 $s$ 最短距离为 $d$ 的每个顶点都有一个到 $s$ 的最短距离为 $d - 1$ 的邻居顶点。一个简单的实现方式是,创建一个有 $n$ 个元素的数组存储从源顶点 $s$ 到其他所有顶点的距离,同时创建一个距离变量 $d$ 来记录当前在搜索过程中所处的层数,算法的具体流程如下:
- 遍历距离数组,查找到
$s$的距离为$d$的所有顶点。 - 查找上述顶点的所有邻居顶点,如果同
$s$的距离未知,则距离置为$d + 1$。 - 如果距离未知的邻居顶点数量为零,则停止算法,否则将
$d$的值加一并重复上述过程。
这种方法在最坏的情况下时间复杂度为 $O \left(m + n^2\right)$,考虑多数网络的直径只随 $\log n$ 增长,算法运行的时间复杂度为 $O \left(m + n \log n\right)$。
上述算法中步骤 1 是最耗时的部分,通过使用队列的数据结构我们可以避免每次都遍历列表来找到距离源顶点 $s$ 距离为 $d$ 的顶点。构造一个队列,一个指针指向下一个要读取的元素,另一个指针指向要填充的空位,这样距离为 $d + 1$ 的顶点就会紧跟在距离为 $d$ 的顶点后面,队列如下图所示:
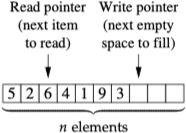
通过队列可以将算法的时间复杂度降至 $O \left(m + n\right)$,对于 $m \propto n$ 的稀疏网络而言,$O \left(m + n\right)$ 相当于 $O \left(n\right)$,所以算法的时间复杂度同顶点数量成正比。
通过对算法进行进一步修改则可以得到源顶点 $s$ 到其他任何顶点的最短路径。方法是在原来的网络上构建一个新的有向网络,该网络代表最短路径,称为最短路径树(shortest path tree),通常情况下,该网络是一个有向非循环网络,而不是树。
对于加权网络,利用广度优先搜索无法找到最短路径,这里需要用到 Dijkstra 算法 2 进行求解。算法将图中的顶点分成两组 $S$ 和 $U$,整个算法过程如下:
- 初始状态,
$S$仅包含源顶点,即$S = \left\{v\right\}$,$U$包含其余顶点。如果$v$与$U$中的顶点$u$为邻居,则距离为边的权重,否则为无穷大。 - 从
$U$中选择一个距离$v$最短的顶点$k$,并把$k$加入到$S$中。 - 若从源点
$v$经过顶点$k$到达$u$的距离比之前$v$到$u$的距离短,则将距离修改为这个更短的距离。 - 重复步骤 2 和 3,直至所有顶点都包含在
$S$中。
整个算法过程的可视化效果如下图所示:

Dijkstra 算法的时间复杂度为 $O \left(m + n^2\right)$,通过二叉堆的数据结构可以将时间复杂度优化至 $O \left(\left(m + n\right) \log n\right)$。
Dijkstra 算法虽然能够处理加权网络,但不能处理存在负权重的网络,需要利用 Floyd-Warshall 算法 3 进行求解。更多 Floyd-Warshall 算法的细节请参见之前的博客计算复杂性 (Computational Complexity) 与动态规划 (Dynamic Programming)。
最大流和最小割
对于连接给定顶点 $s$ 和 $t$ 的两条路径,若没有共享边,则这两条路径是边独立的;若除 $s$ 和 $t$ 外不共享任何其他顶点,则这两条路径是顶点独立的。顶点之间的边连通度和顶点连通度分别是顶点之间边独立路径数和顶点独立路径数。连通度是度量顶点之间连通鲁棒性的简单参数。假设一个网络是一个管线网络,其中每个管线的容量均为单位流量,那么边连通度等于从 $s$ 流向 $t$ 的最大流。
增广路径算法(Ford-Fulkerson Algorithm,FFA)是计算最大流最简单的算法。基本思想是:首先利用广度优先搜索算法找到一条从源 $s$ 到目标 $t$ 的路径。该步骤“消耗”了网络中的一些边,将这些边的容量填充满后,它们不再承载更多流量。之后在剩余边中找到从 $s$ 到 $t$ 的另一条路径,重复该过程直到找不到更多的路径为止。
但这还不是一个有效的算法,如下图中的 (a) 所示,如果在 $s$ 和 $t$ 之间运用广度优先搜索,可以发现黑色标记的路径。一旦这些边的容量被填充满,就不能在剩余边中找到从 $s$ 到 $t$ 的更多路径,但很明显,从 $s$ 到 $t$ 有两条边独立路径(上下各一条)。
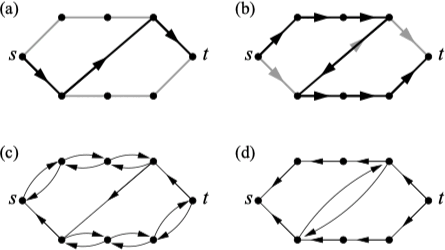
解决该问题的一个简单修正方法是允许网络流量在一条边中能够同时在两个方向流动。更一般地,因为一条边容许承载的最大流是在任意方向的单位流量,那么一条边可以有多个单位流量,只要保证他们能够相互抵消,并且最终每条边承载不超过一个单位流量。
增广路径算法的实现利用了剩余图(residual graph),这是一个有向网络,该网络中的有向边连接原网络中相应的顶点对,并在指定方向承载一个或多个单位流量。例如上图中 (c) 和 (d) 就是对应 (a) 和 (b) 的流量状态的剩余图。算法的正确性在这里就不过多展开说明,该算法在计算两个顶点之间的最大流的平均时间复杂度为 $O \left(\left(m + n\right) m / n\right)$。
在图论中,去掉其中所有边使一张网络不再连通的边集为图的割,一张图上最小的割为最小割。通过对增广路径算法进行改动即可以寻找到边独立路径、最小边割集和顶点独立路径。
图划分和社团发现
图划分(graph partitioning)和社团发现(community detection)都是指根据网络中的边的连接模式,把网络顶点划分成群组、簇或社团。将网络顶点划分成群组后最常见的属性是,同一群组内部的顶点之间通过边紧密连接,而不同群组之间只有少数边。
图划分
最简单的图划分问题是把网络划分成两部分,有时也称其为图对分(graph bisection)。图对分是把一个网络中的顶点划分成为两个指定规模的非重叠群组,使得不同群组之间相互连接的边数最小。群组之间的边数称为割集规模(cut size)。 利用穷举搜索解决该问题是极为耗时的,通过启发式算法我们可以找到较好的网络划分。
Kernighan-Lin 算法
Kernighan-Lin 算法是由 Brian Kernighan 和 Shen Lin 在 1970 年提出的 4,是图对分问题中最简单、最知名的启发式算法之一,如下图所示。
先以任意方式将网络顶点按指定规模划分成两个群组,对于任何由分属不同群组的顶点 $i$ 和顶点 $j$ 组成的顶点对 $\left(i, j\right)$,交换 $i$ 和 $j$ 的位置,并计算交换前后两个群组之间割集规模的变化量。在所有顶点对中找到使割集规模减小最多的顶点对,或者若没有使割集规模减小的顶点对,则找到使割集规模增加最小的顶点对,交换这两个顶点。重复这个过程,同时保证网络中的每个顶点只能移动一次。
继续算法,每一步都交换最大程度减少或最小程度增加群组之间边数的顶点对,直到没有可以变换的顶点对,此时本轮算法停止。在完成所有交换后,检查网络在此过程中经过的每一个状态,然后选择割集规模最小的状态。最后,重复执行上述整个过程,每次始于上次发现的最优网络划分,直到割集规模不在出现改善。
Kernighan-Lin 算法的主要缺点是运算速度缓慢,采用一些技巧来改善算法也只能使时间复杂度降至 $O \left(n^3\right)$,因此该算法仅适用于有几百或几千个顶点的网络,而不适用于更大规模的网络。
谱划分
请先了解附录中的拉普拉斯算子和拉普拉斯矩阵等相关概念。
考虑具有 $n$ 个顶点 $m$ 条边的网络,将其划分为两个群组,称为群组 1 和群组 2。可以把该划分的割集规模,也就是两个群组之间的边数表示为:
$$ \label{eq:r_1} R = \dfrac{1}{2} \sum_{i, j \text{ 属于不同群组}} A_{ij} $$
对于每个网络划分,定义有参数 $s_i$ 组成的集合,集合中每个元素对应于一个顶点 $i$,则有:
$$ s_i = \left\{\begin{array}{ll} +1 & \text{顶点 } i \text{ 在群组 1 中} \\ -1 & \text{顶点 } i \text{ 在群组 2 中} \end{array}\right. $$
那么:
$$ \dfrac{1}{2} \left(1 - s_i s_j\right) = \left\{\begin{array}{ll} 1 & \text{顶点 } i \text{ 和 } j \text{ 在不同的群组中} \\ 0 & \text{顶点 } i \text{ 和 } j \text{ 在相同的群组中} \end{array}\right. $$
则式 \ref{eq:r_1} 可以改写为:
$$ \begin{aligned} R & = \dfrac{1}{4} \sum_{ij} A_{ij} \left(1 - s_i s_j\right) \\ & = \dfrac{1}{4} \left(k_i \delta_{ij} - A_{ij}\right) s_i s_j \\ & = \dfrac{1}{4} \sum_{ij} L_{ij} s_i s_j \end{aligned} $$
其中,$\delta_{ij}$ 是克罗内克函数,$L_{ij}$ 是图拉普拉斯矩阵的第 $ij$ 个元素。写成矩阵的形式有:
$$ R = \dfrac{1}{4} \mathbf{s}^{\top} \mathbf{L} \mathbf{s} $$
由于每个 $s_i$ 的取值只能是 $\left\{+1, -1\right\}$,所以在给定 $\mathbf{L}$ 时求解 $\mathbf{s}$ 使其割集规模最小时并不容易。具体求解方法的推导在此不再展开说明,最终谱划分算法的过程如下所示:
- 计算图拉普拉斯矩阵的第二小特征值
$\lambda_2$,称为网络的代数连通度(algebraic connectivity),及其对应的特征向量$\mathbf{v}_2$。 - 按从大到小的顺序对特征向量的元素进行排序。
- 把前
$n_1$个最大元素对应的顶点放入群组 1,其余放入群组 2,计算割集规模。 - 把前
$n_1$个最小(注意:中文译本中有错误)元素对应的顶点放入群组 2,其余放入群组 1,并重新计算割集规模。 - 在两种网络划分中,选择割集规模较小的那个划分。
谱划分方法在稀疏网络上的时间复杂度为 $O \left(n^2\right)$,这比 Kernighan-Lin 算法时间复杂度少了一个因子 $n$,从而使该算法能应用于更大规模的网络。
社团发现
社团发现(社区发现,社群发现,Community Detection)的基本目的与图划分类似,即把网络分成几个节点点群组,并使节点群组之间的连接较少。主要的差别就是群组的数量和规模是不确定的。社团发现的算法分类和具体实现很多,本文仅介绍几个常用的算法,更多方法及其细节请参见如下开放资源:
- Community Detection in Graphs 5
- Deep Learning for Community Detection: Progress, Challenges and Opportunities 6
- 复杂网络社团发现算法研究新进展 7
- benedekrozemberczki/awesome-community-detection
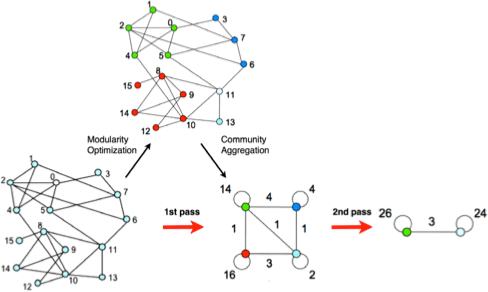
Fast Unfolding (Louvain)
Fast Unfolding (Louvain) 8 是一种基于模块度的社团发现算法,通过模块度来衡量一个社团的紧密程度。算法包含两个阶段:
- 历遍网络中所有的节点,通过比较将节点给每个邻居社团带来的模块度变化,将这个节点加入到使模块度增加最大的社团中。
- 对于步骤 1 的结果,将属于同一个社团的节点合并成为一个大的节点,进而重型构造网络。新的节点之间边的权重是所包含的之前所有节点之间相连的边权重之和,然后重复步骤 1。
算法的两个步骤如下图所示:
Label Propagation Algorithm (LPA)
标签传播算法(Label Propagation Algorithm,LPA)是一种基于半监督学习的社团发现算法。对于每个节点都有对应的标签(即节点所隶属的社团),在算法迭代过程中,节点根据其邻居节点更新自身的标签。更新的规则是选择邻居节点中最多的标签作为自身的标签。
标签传播的过程中,节点的标签更新方式分为同步更新和异步更新两种方式。同步更新是指对于节点 $x$,在第 $t$ 步时,根据其所有邻居节点在 $t - 1$ 步时的标签对其进行更新,即:
$$ C_{x}(t)=f\left(C_{x_{1}}(t-1), C_{x_{2}}(t-1), \cdots, C_{x_{k}}(t-1)\right) $$
同步更新对于一个二分或者近似二分的网络来说可能会出现标签震荡的现象。对于异步更新方式,更新公式为:
$$ C_{x}(t)=f\left(C_{x_{i 1}}(t), \cdots, C_{x_{i m}}(t), C_{x_{i(m+1)}}(t-1), \cdots, C_{x_{i k}}(t-1)\right) $$
其中,邻居节点 $x_{i1}, \cdots, x_{im}$ 的标签在第 $t$ 步时已经更新过,而 $x_{i(m+1)}, \cdots, x_{ik}$ 的标签还未更新。
附录
拉普拉斯算子(Laplace operator,Laplacian)是由欧式空间中的一个函数的梯度的散度给出的微分算子,通常写作 $\Delta$,$\nabla^2$ 或 $\nabla \cdot \nabla$。
梯度(gradient)是对多元导数的概括,函数沿着梯度的方向变化最快,变化率则为梯度的模。假设二元函数 $f \left(x, y\right)$ 在区域 $G$ 内具有一阶连续偏导数,点 $P \left(x, y\right) \in G$,则称向量:
$$ \nabla f = \left(\dfrac{\partial f}{\partial x}, \dfrac{\partial f}{\partial y} \right) = \dfrac{\partial f}{\partial x} \mathbf{i} + \dfrac{\partial f}{\partial y} \mathbf{j} $$
为函数 $f$ 在点 $P$ 处的梯度,其中 $\mathbf{i}$ 和 $\mathbf{j}$ 为单位向量,分别指向 $x$ 和 $y$ 坐标方向。
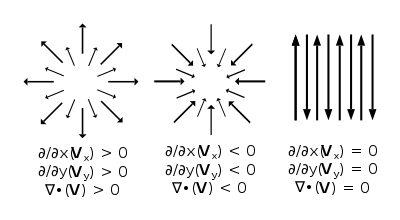
散度(divergence)将向量空间上的一个向量场对应到一个标量场上,记为 $\nabla \cdot$。散度的意义是场的有源性,当 $\nabla \cdot F > 0$ 时,表示该点是发源点;当 $\nabla \cdot F < 0$ 时,表示该点是汇聚点;当 $\nabla \cdot F = 0$ 时,表示该点无源,如下图所示。
拉普拉斯离散化后即为拉普拉斯矩阵(laplacian matrix),也称为调和矩阵(harmonic matrix)。离散化的拉普拉斯算子形式如下:
$$ \begin{aligned} \Delta f & = \dfrac{\partial^2 f}{\partial x^2} + \dfrac{\partial^2 f}{\partial y^2} \\ & = f \left(x + 1, y\right) + f \left(x - 1, y\right) - 2 f \left(x, y\right) + f \left(x, y + 1\right) + f \left(x, y - 1\right) - 2 f \left(x, y\right) \\ & = f \left(x + 1, y\right) + f \left(x - 1, y\right) + f \left(x, y + 1\right) + f \left(x, y - 1\right) - 4 f \left(x, y\right) \end{aligned} $$
从上述离散化后的拉普拉斯算子形式可以看出,拉普拉斯矩阵表示的是对矩阵进行微小扰动后获得的收益。
设图 $G$ 有 $n$ 个节点,节点的邻域为 $N$,图上的函数 $f = \left(f_1, f_2, \cdots, f_n\right)$,其中 $f_i$ 表示节点 $i$ 处的函数值。对 $i$ 进行扰动,其可能变为邻域内的任意一个节点 $j \in N_i$:
$$ \Delta f_{i}=\sum_{j \in N_{i}}\left(f_{i}-f_{j}\right) $$
设每一条边 $e_{ij}$ 的权重为 $w_{ij}$,$w_{ij} = 0$ 表示节点 $i$ 和节点 $j$ 不相邻,则有:
$$ \begin{aligned} \Delta f_i & = \sum_{j \in N} w_{ij} \left(f_i - f_j\right) \\ & = \sum_{j \in N} w_{ij} f_i - \sum_{j \in N} w_{ij} f_i \\ & = d_i f_i - W_{i:} f \end{aligned} $$
对于所有节点有:
$$ \begin{aligned} \Delta f & = \left(\begin{array}{c} \Delta f_{1} \\ \vdots \\ \Delta f_{N} \end{array}\right)=\left(\begin{array}{c} d_{1} f_{1}-W_{1:} f \\ \vdots \\ d_{N} f_{N}-W_{N:} f \end{array}\right) \\ & = \left(\begin{array}{ccc} d_{1} & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & d_{N} \end{array}\right) f-\left(\begin{array}{c} W_{1:} \\ \vdots \\ W_{N:} \end{array}\right) f \\ & = diag \left(d_i\right) f - W f \\ & = \left(D - W\right) f \\ & = L f \end{aligned} $$
令图 $G$ 的邻接矩阵为 $W$,度矩阵为 $D$,从上式可知拉普拉斯矩阵 $L = D - W$,其中:
$$ L_{ij} = \left\{\begin{array}{ll} \deg \left(v_i\right) & \text{如果 } i = j \\ -1 & \text{如果 } i \neq j \text{ 且 } v_i \text{ 与 } v_j \text{ 相邻} \\ 0 & \text{其他情况} \end{array}\right. $$
以下面的图为例:
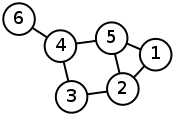
邻接矩阵为:
$$ \left(\begin{array}{llllll} 0 & 1 & 0 & 0 & 1 & 0 \\ 1 & 0 & 1 & 0 & 1 & 0 \\ 0 & 1 & 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 & 1 & 1 \\ 1 & 1 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 & 0 & 0 \end{array}\right) $$
度矩阵为:
$$ \left(\begin{array}{cccccc} 2 & 0 & 0 & 0 & 0 & 0 \\ 0 & 3 & 0 & 0 & 0 & 0 \\ 0 & 0 & 2 & 0 & 0 & 0 \\ 0 & 0 & 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 & 3 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 \end{array}\right) $$
拉普拉斯矩阵为:
$$ \left(\begin{array}{rrrrrr} 2 & -1 & 0 & 0 & -1 & 0 \\ -1 & 3 & -1 & 0 & -1 & 0 \\ 0 & -1 & 2 & -1 & 0 & 0 \\ 0 & 0 & -1 & 3 & -1 & -1 \\ -1 & -1 & 0 & -1 & 3 & 0 \\ 0 & 0 & 0 & 1 & 0 & 1 \end{array}\right) $$
开放资源
常用网络算法包
| 名称 | 语言 |
|---|---|
| NetworkX | Python |
| graph-tool | Python |
| SNAP | C++, Python |
| NetworKit | C++, Python |
| igraph | C, C++, Python, R |
| lightgraphs | Julia |
不同扩展包之间的性能比较如下表所示 9:
| 数据集 | 算法 | graph-tool | igraph | LightGraphs | NetworKit | NetworkX | SNAP |
|---|---|---|---|---|---|---|---|
| Amazon | CC | 0.08 | 0.22 | 0.07 | 0.09 | 2.22 | 0.31 |
| Amazon | k-core | 0.08 | 0.15 | 0.04 | 0.15 | 3.63 | 0.37 |
| Amazon | loading | 2.61 | 0.57 | 4.66 | 0.98 | 4.72 | 1.61 |
| Amazon | page rank | 0.04 | 0.57 | 0.02 | 0.02 | 8.59 | 0.58 |
| Amazon | shortest path | 0.03 | 0.05 | 0.01 | 0.04 | 1.37 | 0.12 |
| CC | 0.28 | 1.38 | 0.29 | 0.37 | 7.77 | 1.56 | |
| k-core | 0.39 | 0.92 | 0.16 | 0.83 | 42.6 | 1.31 | |
| loading | 11.02 | 3.87 | 16.75 | 4.38 | 19.24 | 7.56 | |
| page rank | 0.36 | 2.42 | 0.06 | 0.1 | 33.5 | 2.31 | |
| shortest path | 0.08 | 0.41 | 0.01 | 0.14 | 3.41 | 0.26 | |
| Pokec | CC | 1.83 | 3.96 | 1.5 | 1.75 | 61.74 | 9.75 |
| Pokec | k-core | 3.6 | 5.99 | 0.95 | 5.05 | 296.26 | 6.91 |
| Pokec | loading | 71.46 | 25.75 | 170.63 | 26.77 | 140.19 | 52.73 |
| Pokec | page rank | 1.1 | 23.39 | 0.21 | 0.24 | 239.75 | 8.62 |
| Pokec | shortest path | 0.48 | 0.6 | 0.05 | 0.56 | 5.65 | 2.3 |
常用网络可视化软件
| 软件 | 平台 |
|---|---|
| Cytoscape | Windows, macOS, Linux |
| Gephi | Windows, macOS, Linux |
| Tulip | Windows, macOS, Linux |
| Pajek | Windows |
不同可视化软件之间的比较如下表所示 10:
| Cytoscape | Tulip | Gephi | Pajek | |
|---|---|---|---|---|
| Scalability | ★★ | ★ | ★★★ | ★★★★ |
| User friendliness | ★★ | ★★★★ | ★★★ | ★ |
| Visual styles | ★★★★ | ★★ | ★★★ | ★ |
| Edge bundling | ★★★ | ★★★★ | ★★ | - |
| Relevance to biology | ★★★★ | ★★ | ★★★ | ★ |
| Memory efficiency | ★ | ★★ | ★★★ | ★★★★ |
| Clustering | ★★★★ | ★★★ | ★ | ★★ |
| Manual node/edge editing | ★★★ | ★★★★ | ★★★ | ★ |
| Layouts | ★★★ | ★★ | ★★★★ | ★ |
| Network profiling | ★★★★ | ★★ | ★★★ | ★ |
| File formats | ★★ | ★★★ | ★★★★ | ★ |
| Plugins | ★★★★ | ★★ | ★★★ | ★ |
| Stability | ★★★ | ★ | ★★★★ | ★★★ |
| Speed | ★★ | ★ | ★★★ | ★★★★ |
| Documentation | ★★★★ | ★ | ★★ | ★★★ |
其中,★ 表示较弱、★★ 表示中等、★★★ 表示较好、★★★★ 表示优秀。
-
Newman, M. E. J. (2014) 网络科学引论. 电子工业出版社. ↩︎
-
Kernighan, B. W., & Lin, S. (1970). An efficient heuristic procedure for partitioning graphs. The Bell system technical journal, 49(2), 291-307. ↩︎
-
Fortunato, S. (2010). Community detection in graphs. Physics reports, 486(3-5), 75-174. ↩︎
-
Liu, F., Xue, S., Wu, J., Zhou, C., Hu, W., Paris, C., … & Yu, P. S. (2020). Deep Learning for Community Detection: Progress, Challenges and Opportunities. arXiv preprint arXiv:2005.08225. ↩︎
-
骆志刚, 丁凡, 蒋晓舟, & 石金龙. (2011). 复杂网络社团发现算法研究新进展. 国防科技大学学报, (1), 12. ↩︎
-
Blondel, V. D., Guillaume, J. L., Lambiotte, R., & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of statistical mechanics: theory and experiment, 2008(10), P10008. ↩︎
-
Pavlopoulos, G. A., Paez-Espino, D., Kyrpides, N. C., & Iliopoulos, I. (2017). Empirical comparison of visualization tools for larger-scale network analysis. Advances in bioinformatics, 2017. ↩︎