本文为《复杂网络系列》文章
图存储
语义网络与 RDF 存储
1968 年 Ross Quillian 在其博士论文中最先提出语义网络(Semantic Web),把它作为人类联想记忆的一个显式心理学模型,并在他设计的可教式语言理解器 TLC(Teachable Language Comprehenden)中用作知识表示方法。
语义网络的基本思想是在网络中,用“节点”代替概念,用节点间的“连接弧”(称为联想弧)代替概念之间的关系,因此,语义网络又称联想网络。它在形式上是一个带标识的有向图。由于所有的概念节点均通过联想弧彼此相连知识推导。
一个语义网络的基本构成如下:
- 语义网络中的节点:表示各种事物、概念、情况、属性、动作、状态等,每个节点可以带有若干属性,一般用框架或元组表示。此外,节点还可以是一个语义子网络,形成一个多层次的嵌套结构。
- 语义网络中的弧:表示各种语义联系,指明它所连接的节点间某种语义关系。
- 节点和弧都必须带有标识,以便区分各种不同对象以及对象间各种不同的语义联系。
之后 Tim Berners-Lee 又提出了语义网堆栈(Semantic Web Stack)的概念。语义网堆栈利用图示解释是不同层面的语言所构成的层级结构,其中,每一层面都将利用下游层面的能力,语义网堆栈如下图所示:
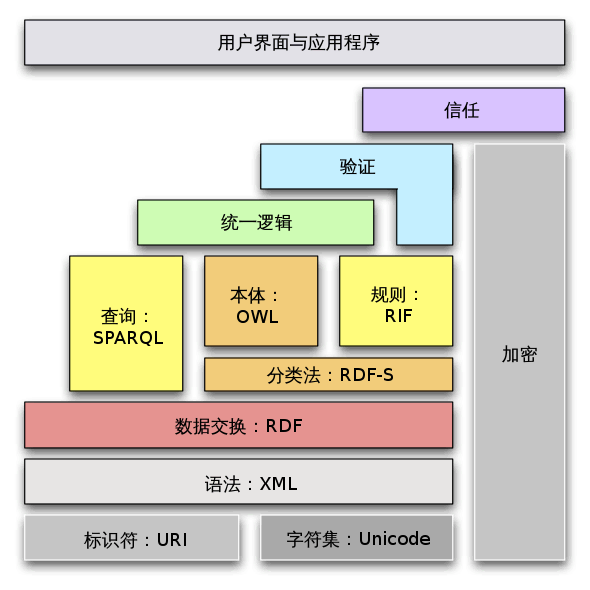
资源描述框架(Resource Description Framework,RDF)是用于描述网络资源的 W3C 标准,比如网页的标题、作者、修改日期、内容以及版权信息。
RDF 使用 Web 标识符来标识事物,并通过属性和属性值来描述资源。
对资源、属性和属性值的解释:
- 资源是可拥有 URI 的任何事物,比如
http://www.w3school.com.cn/rdf - 属性是拥有名称的资源,比如
author或homepage - 属性值是某个属性的值,比如
David或http://www.w3school.com.cn(请注意一个属性值可以是另外一个资源)
下面是一个 RDF 示例文档(这是一个简化的例子,命名空间被忽略了):
<?xml version="1.0"?>
<RDF>
<Description about="http://www.w3school.com.cn/RDF">
<author>David</author>
<homepage>http://www.w3school.com.cn</homepage>
</Description>
</RDF>
资源、属性和属性值的组合可形成一个陈述(被称为陈述的主体、谓语和客体)。上述的 RDF 文档包含了如下两个陈述:
- 陈述:The
authorofhttp://www.w3school.com.cn/rdfisDavid- 陈述的主体是:
http://www.w3school.com.cn/rdf - 谓语是:
author - 客体是:
David
- 陈述的主体是:
- 陈述:The
homepageofhttp://www.w3school.com.cn/rdfishttp://www.w3school.com.cn- 陈述的主体是:
http://www.w3school.com.cn/rdf - 谓语是:
homepage - 客体是:
http://www.w3school.com.cn
- 陈述的主体是:
更多 RDF 介绍请参见:https://www.w3school.com.cn/rdf/index.asp 。
Apache Jena 是一个用于构建语义网络(Semantic Web)和链接数据(Linked Data)应用的开源 Java 框架。Jena 提供了 3 大部分功能:
- RDF
- Triple store
- TDB:提供一种原生高效的 Triple 存储 TDB,全面支持 Jena APIs。
- Fuseki:提供 REST 风格的 RDF 数据交互方式。
- OWL
- Ontology API:通过 RDFS,OWL 等为 RDF 数据添加更多语义信息。
- Inference API:通过内置的 OWL 和 RDFS 语义推理器 构建个性化的推理规则。
下面以 Graph of The Gods 的关系图对 Jena 的基本功能进行说明。Graph of The Gods 是一张描述希腊神话相关事物之间关系的图,其中顶点的类型有:titan(泰坦,希腊神话中曾经统治师姐的古老神族),god(神),demigod(半神),human(人),monster(怪物),location(地点);关系的类型有:father(父亲),brother(兄弟),mother(母亲),battled(战斗),lives(居住)。

以 Apache Tomcat 作为容器来安装 Apache Jena Fuseki,下载最新版的 Apache Jena Fuseki 并解压,将其中的 fuseki.war 复制到已经安装并运行的 Apache Tomcat 的 webapps 路径下。安装完毕后,进入 http://127.0.0.1:8080/fuseki 即可使用 Apache Jena Fuseki。
在导入 Graph of The Gods 数据后,执行如下查询语句可以获得 jupiter 的所有兄弟:
PREFIX gods: <http://leovan.me/gods/>
SELECT DISTINCT ?god
WHERE {
?god gods:brother gods:jupiter
}
查询结果为:
| god | |
|---|---|
| 1 | gods:pluto |
| 2 | gods:neptune |
图数据库
图数据库是一个使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。不同于关系型数据库,图数据库为 NoSQL(Not Only SQL)的一种,属于联机事务处理(OLTP)的范畴,可以解决现有关系数据库的局限性。
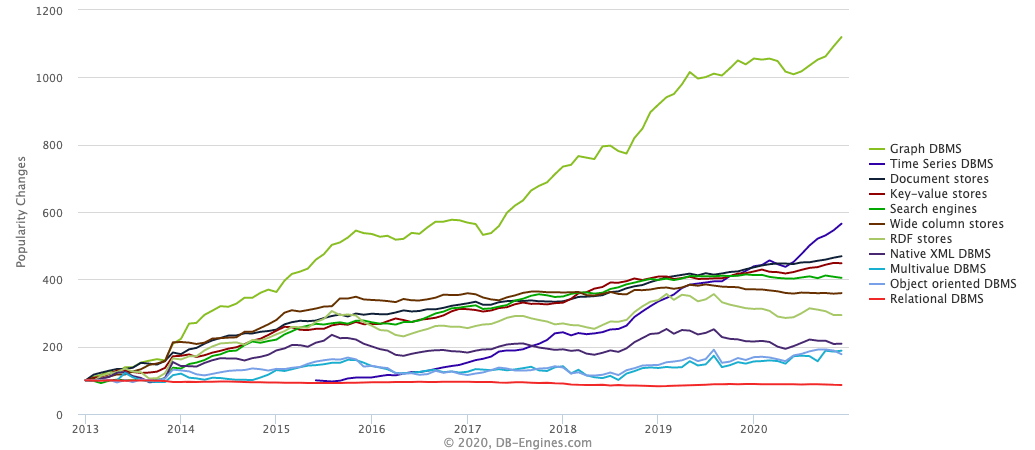
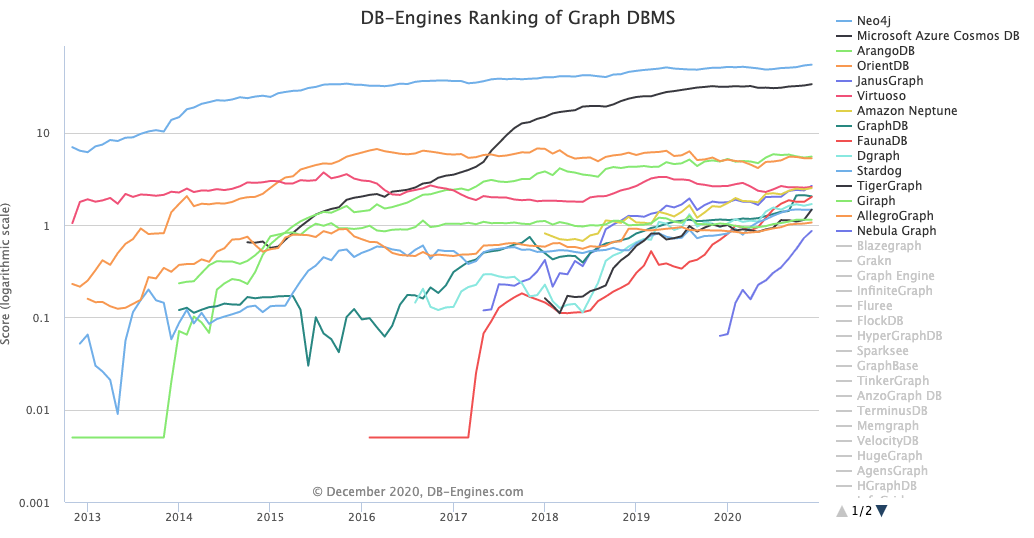
下图展示了近年来不同类型数据库的流行度趋势,不难看出近年来越来越多的人开始关注图数据库。
截止到 2020 年 12 月,图数据库的排名如下图所示:
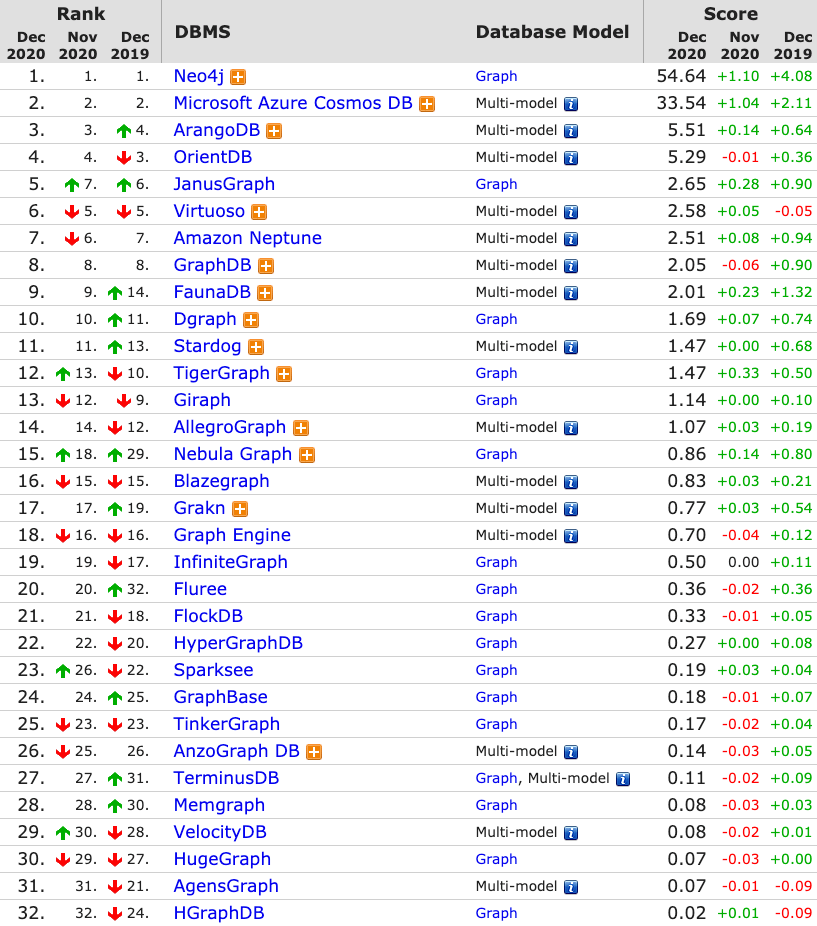
其中,Neo4j、JanusGraph、Dgraph、TigerGraph、Nebula Graph 均为时下常用的图数据库。从下图的流行度趋势角度来看,JanusGraph、Dgraph、TigerGraph 和 Nebula Graph 等后起之秀发展迅速。
不同的图数据库有着不同的优劣势,用户可以根据实际业务场景选择合适的图数据库。下面给到一些较新的图数据库对比和评测:
查询语言
图查询语言(Graph Query Language,GQL)是一种用于图数据库的查询语言,类比于关系型数据库的查询语言 SQL。2019 年 9 月,GQL 被提议为一种新的数据库查询语言(ISO/IEC WD 39075),目前仍处于开发当中,因此市面上还没有统一的图查询语言标准。
Gremlin
Gremlin 是 Apache TinkerPop 框架下的图遍历语言。Gremlin 适用于基于 OLTP 的图数据库以及基于 OLAP 的图分析引擎,支持命令式和声明式查询。支持 Gremlin 的图数据库有:Neo4j、JanusGraph 等。
Cypher
Cypher 是一种声明式图查询语言,这使得在不必编写遍历逻辑的情况下可以实现高效的查询。支持 Cypher 的图数据库有:Neo4j、RedisGraph、Nebula Graph 等。
nGQL
nGQL 是一种声明式的图查询语言,支持图遍历、模式匹配、聚合运算和图计算等特性。支持 nGQL 的图数据库有:Nebula Graph。
比较
针对 3 种不同的查询语言,对于图中相关概念的表示也略有不同,如下表所示:
| 术语 | Gremlin | Cypher | nGQL |
|---|---|---|---|
| 点 | Vertex | Node | Vertex |
| 边 | Edge | Relationship | Edge |
| 点类型 | Label | Label | Tag |
| 边类型 | label | RelationshipType | edge type |
| 点 ID | vid | id(n) | vid |
| 边 ID | eid | id(r) | 无 |
| 插入 | add | create | insert |
| 删除 | drop | delete | delete / drop |
| 更新属性 | setProperty | set | update |
更多不同查询语言之间的详细对比可以参见如下资料:
图计算
图计算框架
GraphX
GraphX 是一个基于 Spark 大规模图计算框架。GraphX 通过引入一个包含带有属性的顶点和变的有向图对 Spark 的 RDD 进行了扩展。通过 subgraph、joinVertices 和 aggregateMessages 等算子实现了 PageRank、连通子图、LPA 等图算法。
Plato
Plato 是由腾讯开源的高性能图计算框架。Plato 主要提供两方面的能力:离线图计算和图表示学习,目前支持的图算法如下:
| 算法分类 | 算法 |
|---|---|
| 图特征 | 树深度/宽度;节点数/边数/密度/节点度分布;N-阶度;HyperANF |
| 节点中心性指标 | KCore;Pagerank;Closeness;Betweenness |
| 连通图 & 社团识别 | Connected-Component;LPA;HANP |
| 图表示学习 | Node2Vec-Randomwalk;Metapath-Randomwalk |
| 聚类/分圈算法 | FastUnfolding |
| 其他图相关算法 | BFS;共同类计算 |
| 待开源算法 | Word2Vec;Line;GraphVite;GCN |
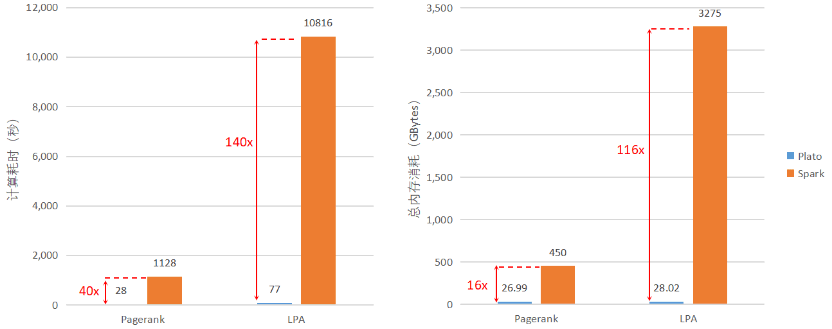
在计算性能上,Plato 与 Spark GraphX 在 PageRank 和 LPA 两个算法上的计算耗时与内存消耗对比如下图所示:
GraphScope
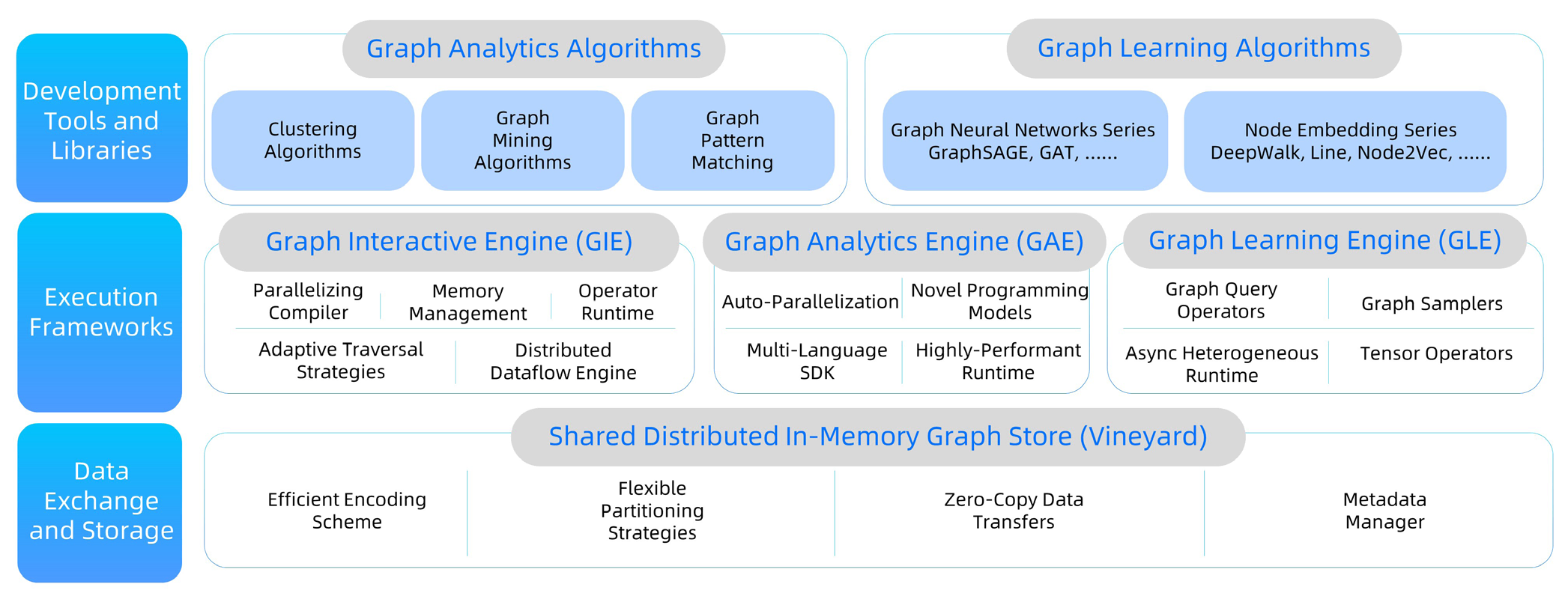
GraphScope 由有阿里巴巴开源的一个统一的分布式图计算平台。GraphScope 提供了一个一站式环境,可以通过用户友好的 Python 接口在集群内对图进行操作。GraphScope 利用一系列开源技术使得集群上的大规模图数据的多阶段处理变得简单,这些技术包括:用于分析的 GRAPE、用于查询的 MaxGraph 、用于图神经网络计算的 Graph-Learn 和用于提供高效内存数据交换的 vineyard。GraphScope 的整体架构如下图所示:
GraphScope Interactive Engine(GIE)是一个用于探索性分析大规模复杂图结构数据的引擎,它通过 Gremlin 提供高级别的图查询语言,同时提供自动并行执行功能。
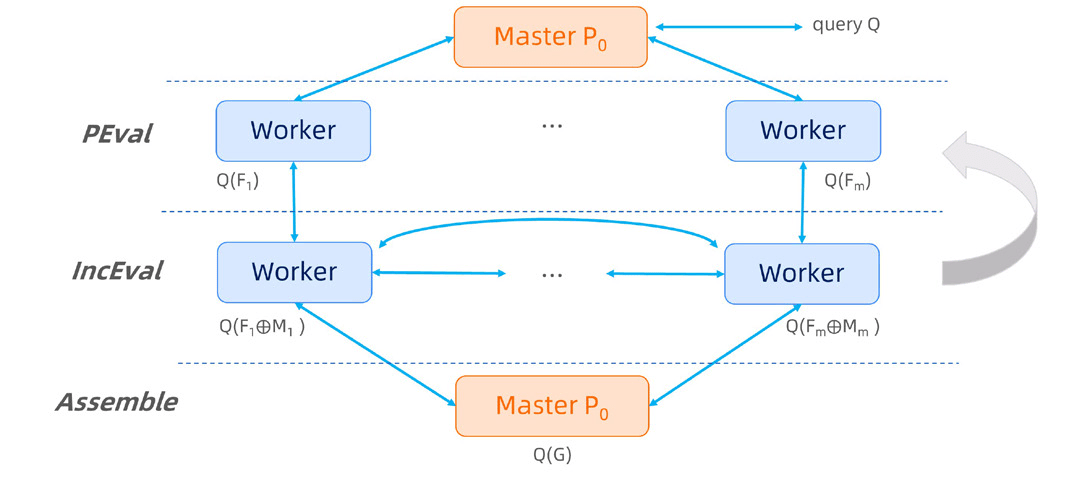
GraphScope Analytical Engine(GAE)是一个基于 GRAPE 1 提供并行图算法的分析引擎。除了提供基础的内置算法以外,GAE 允许用户利用 Python 基于 PIE 1 编程模型编写自定义算法,PIE 编程模型的运行方式如下图所示:
GraphScope 还提供以顶点为中心的 Pregel 模型 2,用户可以使用 Pregel 模型来实现自定义算法。
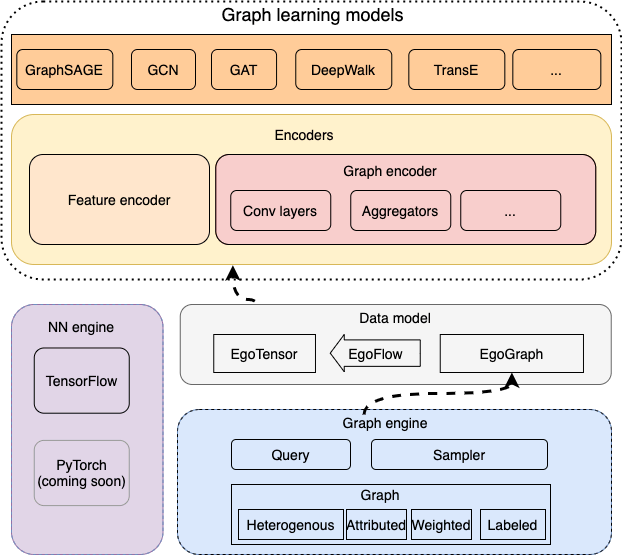
GraphScope Learning Engine(GLE)是一个用于开发和训练大规模图神经网络的分布式框架。GLE 提供基于全量图(用于 GCN、GAT 等算法)和采样子图(用于 GraphSAGE,FastGCN、GraphSAINT 等算法)两种不同方式训练图模型。整体架构如下图所示:
Galileo
Galileo 是由京东零售研发的图计算平台,提供离线和在线图计算和图数据服务能力。目前 Galileo 暂未开源,待开源后补充相关信息。
图神经网络
关于图神经网络内容,请参见之前的博客 图嵌入 (Graph Embedding) 和图神经网络 (Graph Neural Network)。
🎉🎉🎉 Happy New Year! 🎉🎉🎉
-
Fan, W., Yu, W., Xu, J., Zhou, J., Luo, X., Yin, Q., … & Xu, R. (2018). Parallelizing sequential graph computations. ACM Transactions on Database Systems (TODS), 43(4), 1-39. ↩︎ ↩︎
-
Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, I., Leiser, N., & Czajkowski, G. (2010, June). Pregel: a system for large-scale graph processing. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (pp. 135-146). ↩︎