最近观察自己和团队在使用 AI 上遇到了一些情况,比如生成的东西(代码、报告、网页等)“虾”味儿比较重,交付质量上也良莠不齐(准确性和深度等方面)。甚至在一些没有必要的场景(至少我认为没有必要)非要把 AI 用上,我想 FOMO 和组织压力是两个重要的“罪魁祸首”。彼时大家考虑更多的是如何“用上” AI,而不是如何“用好” AI。以任何一个角度去切入去尝试 AI 都是对的,欠妥的是当遇到“为什么一会儿行一会不行”,“为什么他那行我这不行”的时候,又会去质疑 AI 不行而不是自己用得不好。
思辨的意义在于过程中的反复,而不是最后的对与错和好与坏。在评判 AI 是否应该介入一个工作的时候我会关注两个点:
- ROI:一切抛开成本的使用都是耍流氓。典型的例子就是一个事儿一年都干不了几次,不确定性还很高,想要 AI 帮你一步到位纯纯就是幻想(至少现在是)。
- 角色:它在这件事儿中扮演什么样的角色。以画图为例(这里说的是思维导图、架构图之类,而非数据图),我可以和 AI 探讨思路,然后把结果按照想要的样子放上去。而不是一句话:帮我把 XXX 画一个架构图出来。图的意义从来不是这张图本身,而是拼拼凑凑形成过程中的思考,当你想一句话画出来的时候,你不想干的一定不是“画”而是“思考”。
一篇『文科生 72 小时杀入 GitHub 全球榜:我没写一行代码,但指挥了一支 AI 军队』让“技术平权”再次沸腾,但我希望在团队拥抱 AI 的过程中成为一个仁慈的独裁者 1 2,确定性和掌控欲不是阻碍 AI 落地的绊脚石,当个“甩手掌柜”才是加速被淘汰的慢性毒药。
技术视角
在之前的文章中提过 LLM 本身是一个无状态的服务,你给他什么样的输入,它就会预测什么样的输出。产生不确定性的核心在于当今 AI 的背后是一个概率预测模型:
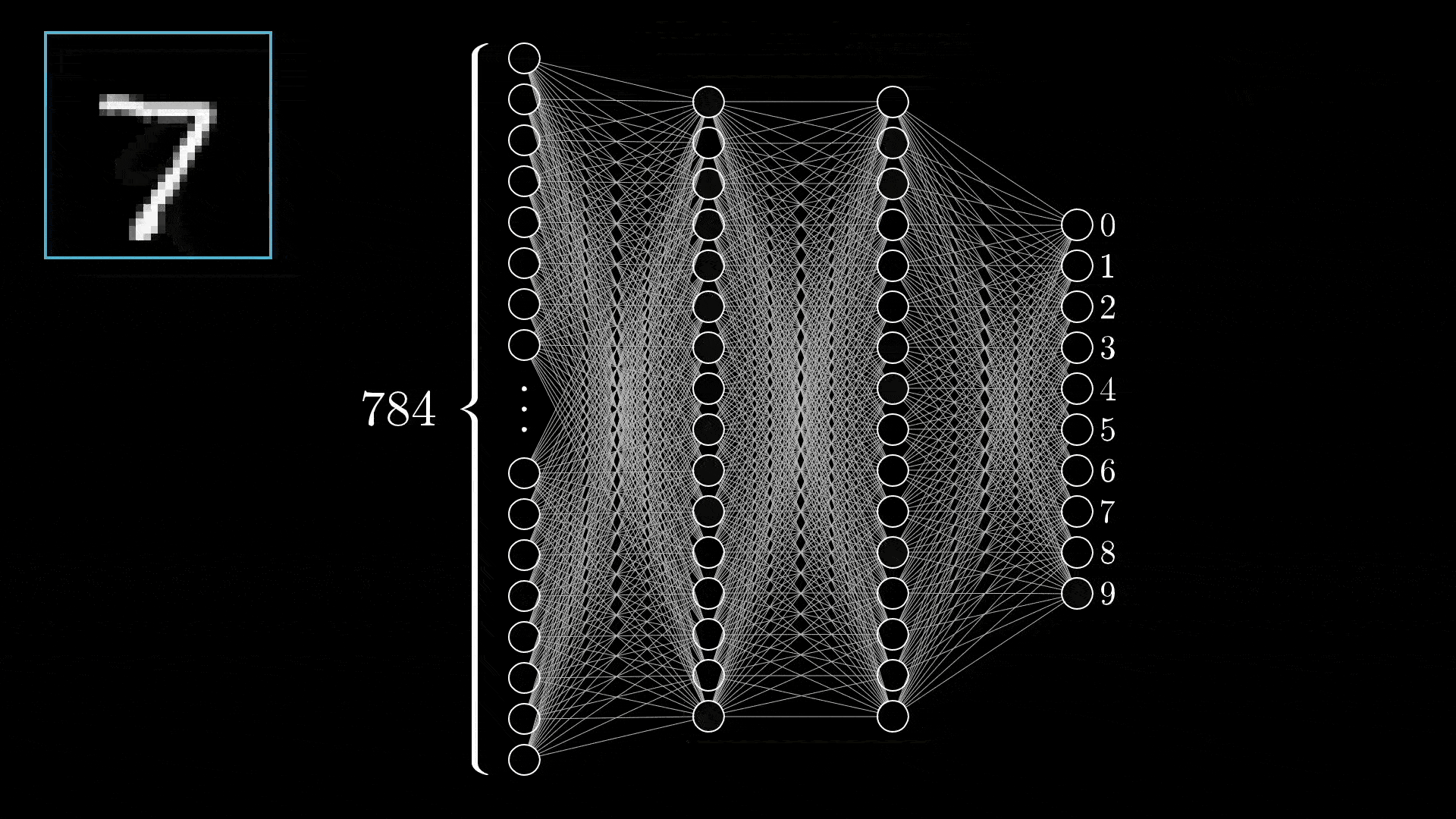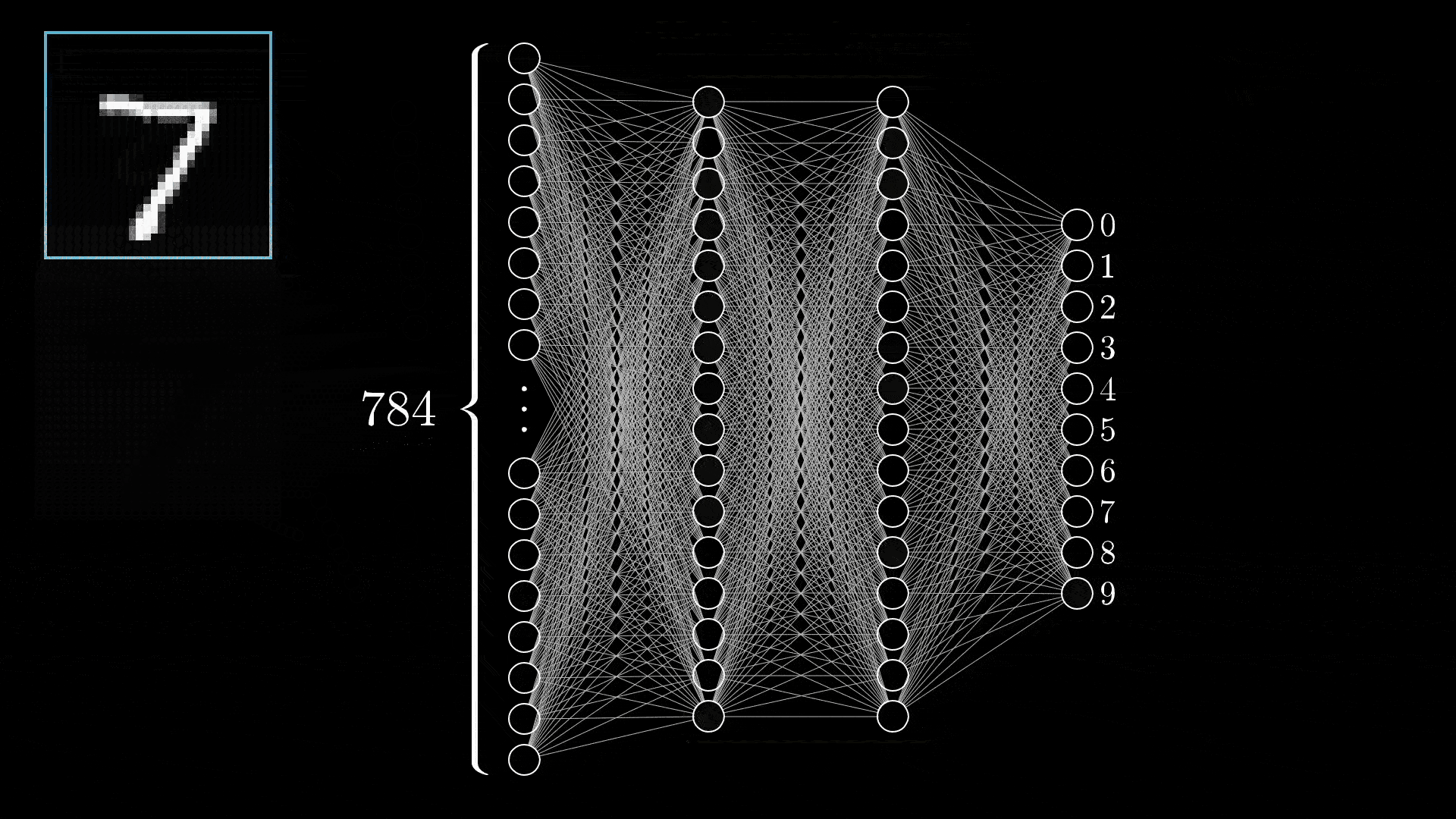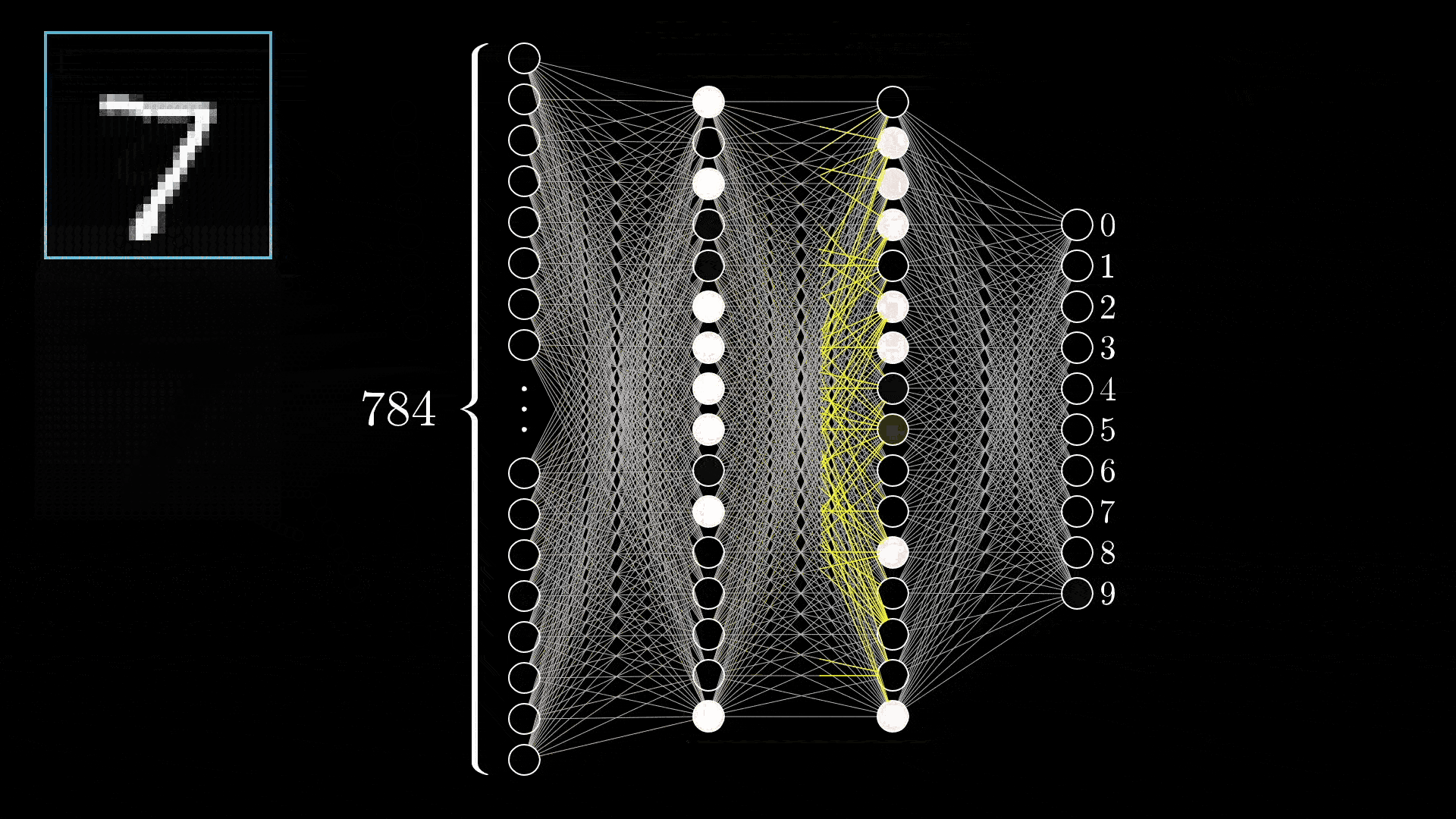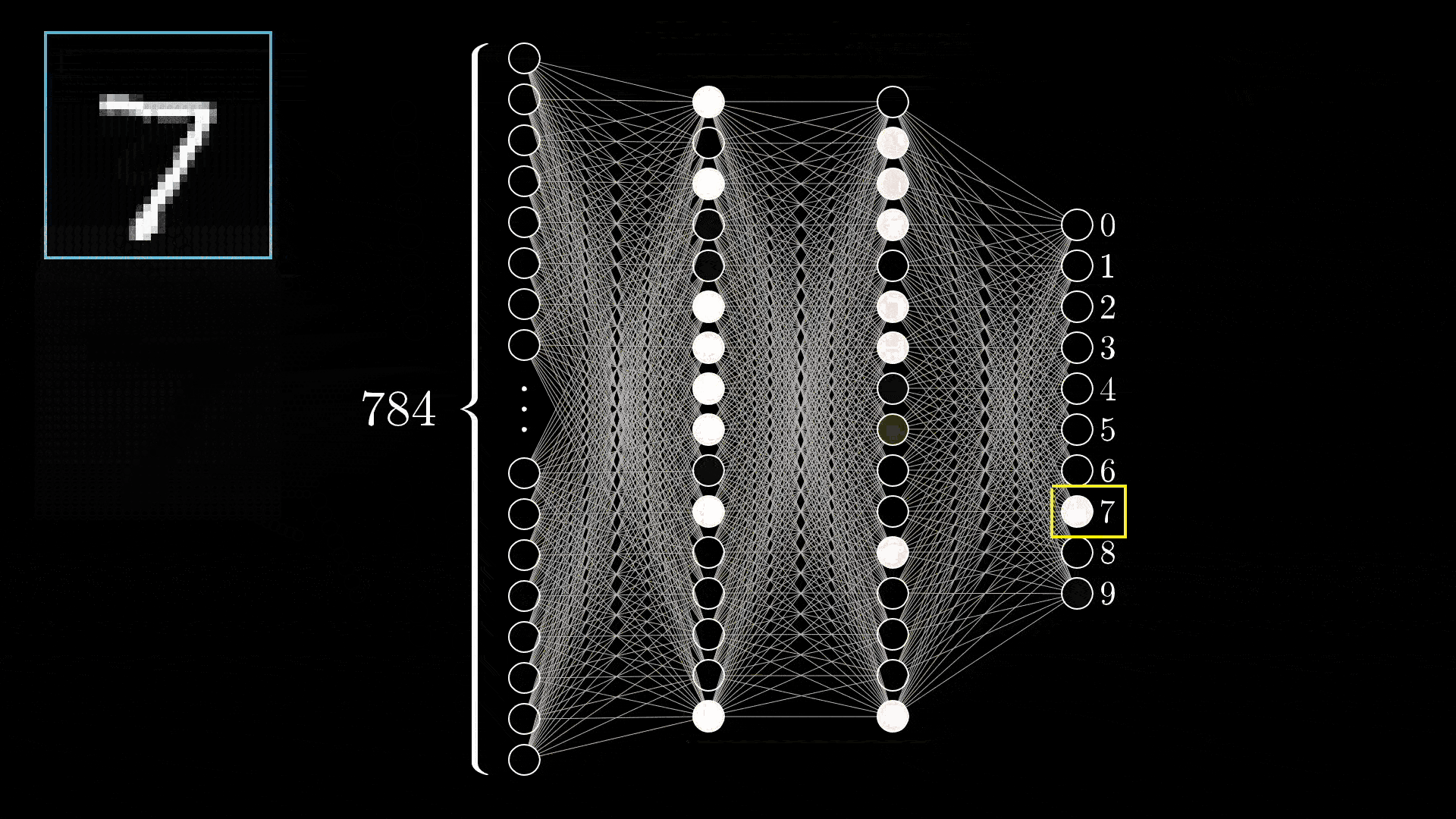
排除网络架构的不同 3 4,即使最朴素的全连接神经网络,在给到足够的训练数据时,其仍可以拟合任意函数:
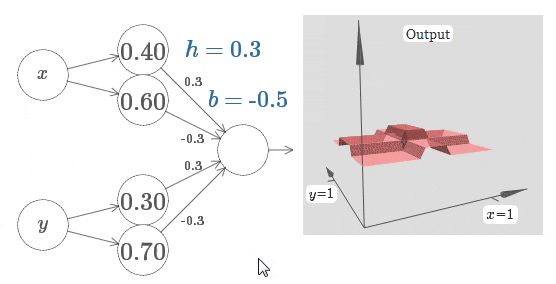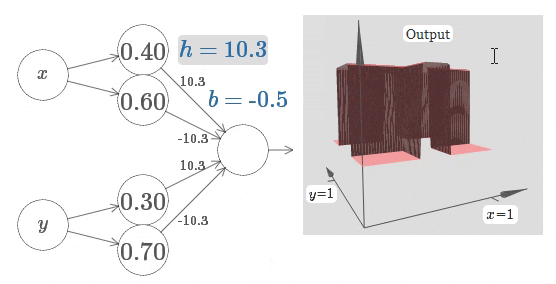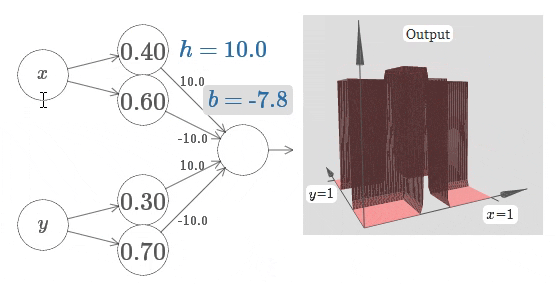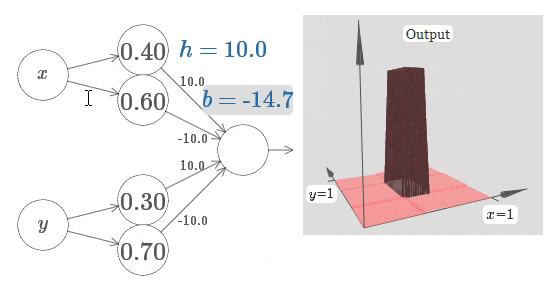
在以 Transformer 为基础的 LLM 中,还有着多个用于控制模型输出不确定性的参数。
| 参数 | 图示 | 描述 |
|---|---|---|
| 最大 Token 数 |

|
控制生成的最大 Token 数, 取值范围 $\left[1, \infty\right]$ |
| 温度 |
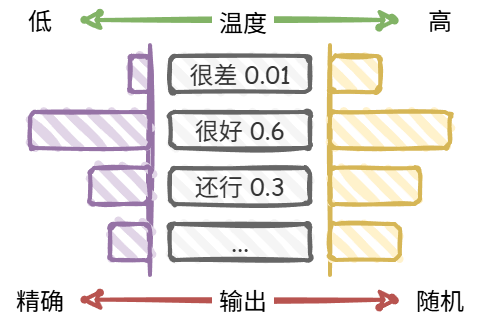
|
控制模型输出的随机性,值越大越随机, 取值范围 $\left[0, 2\right]$ |
| $\text{Top}_p$ |
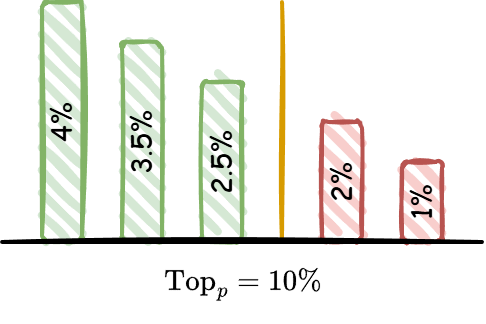
|
控制 Token 采样时的累计概率, 取值范围 $\left[0, 1\right]$ |
| $\text{Top}_k$ |
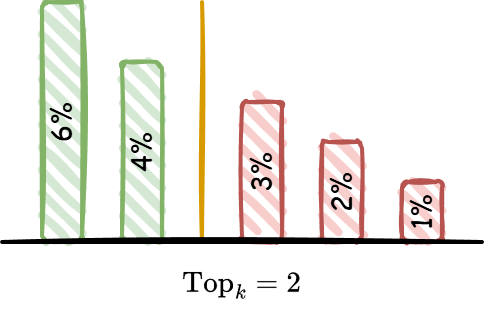
|
控制 Token 采样时当候选数量, 取值范围 $\left[1, \infty\right]$ |
| 频率惩罚 |

|
减少重复内容的生成,正值减少重复 取值范围 $\left[-2, 2\right]$ |
| 存在惩罚 |

|
鼓励生成新的内容,正值鼓励新内容 取值范围 $\left[-2, 2\right]$ |
| 停止词 |

|
自定义的停止词列表 |
| 图片参考 https://blog.dailydoseofds.com/p/7-llm-generation-parameters 进行重绘 | ||
通过调整如上参数,你可以一定程度上控制 AI 输出的不确定性,当写代码时可以让其更确定些,当做内容创作时可以让其更随机些。用好 AI,而不是当 AI 彻底放飞自我的时候只会吐槽它又变“傻”了。Harness Engineering 也在尝试从应用层解决产出可靠性的问题。
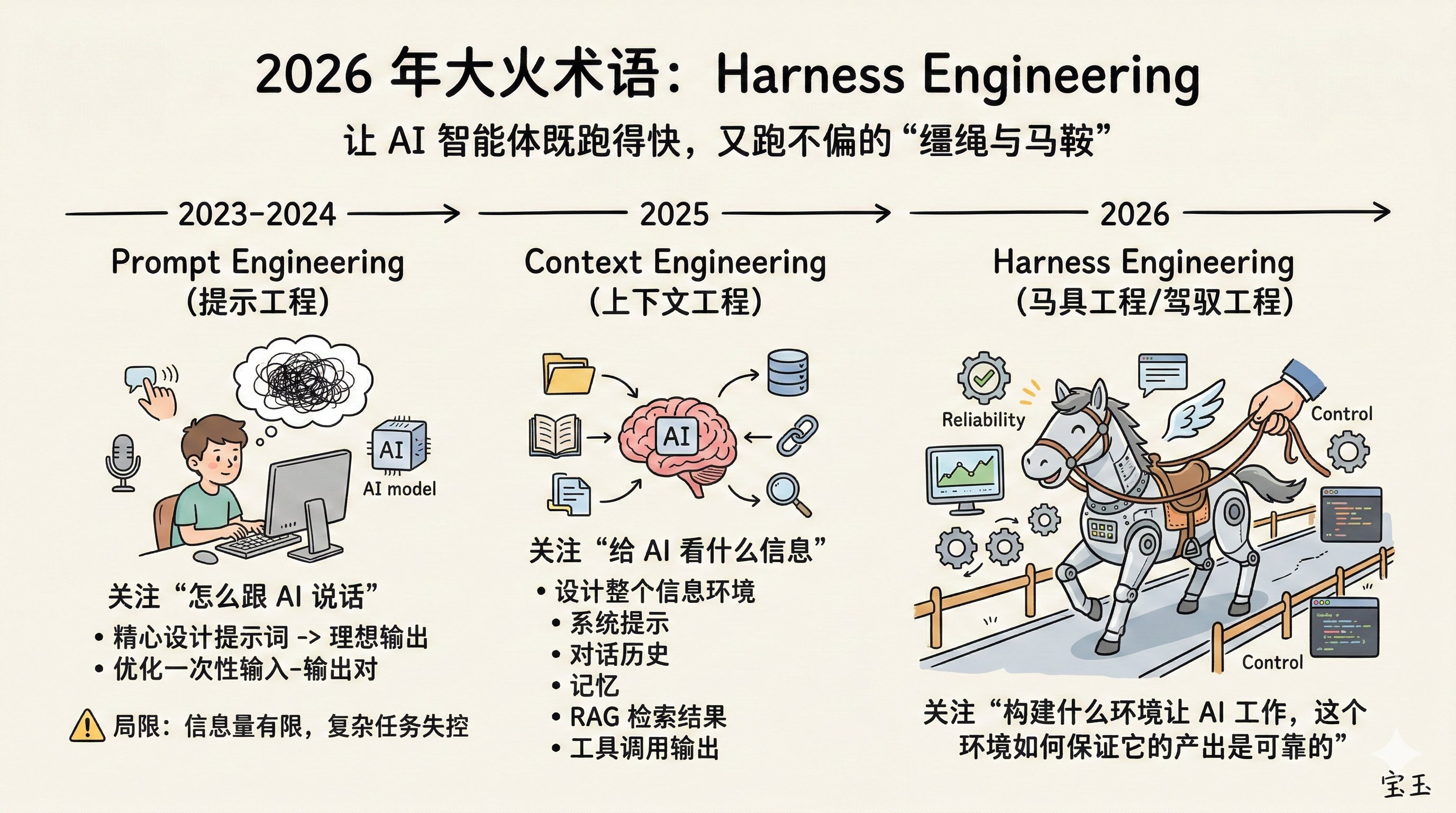
在写 Skill 的时候,根据 Claude Code 的 Skill 编写规范,SKILL.md 文件应该在 500 行以下,更详细的参考资料应该转移到单独的文件中去。确定性的事情应该放在 scripts 中用代码实现,当下用 AI 写 Skill 的时候虽然它知道利用脚本实现一些确定性的事情,但脚本自身是否正确是否鲁棒你心里还需有个谱。知其然,知其所以然,AI 时代没有要求大家都需要搞明白模型中的各种数学公式,但用好 AI 的人也绝不仅限于知道几个 AI 名词而已。
管理视角
现在面向代码春暖花开的我曾经学了 7 年的管理,记得管理学老师开堂的第一句话是:管理学既是一门科学,又是一门艺术。科学性在于我们有经典的马斯洛需求层次理论和双因素理论,艺术性在于人与社会的复杂和管理实践中“度”的拿捏,例如放权。网上有这样一篇文章:不懂代码反而是优势,为什么控制欲强的人用不好 AI?。我个人的观点是五五开,当前技术发展之迅猛前所未有,不懂代码就不会陷入固有的行为模式中去,确实更容易拥抱变化,但控制欲强并不代表不放权,随着 AI 时代生产力和生产关系的变化,放权的艺术也需要与时俱进。
文章中提到“以结果为导向”,这点我很赞同,商业体系中生存之本就是拿结果。“拿结果”这三个字说起来容易,但拿什么、怎么拿、谁来拿这都是问题。组织的层级设置,从战略到战术的层层拆解,这些都是复杂的工程。以一线管理者为例(我理解和当前大家使用和管理自己的智能体场景类似),如果你只一味的抓结果不抓过程,那么等 Deadline 到了却没有合格的产出时,一切终究都是徒劳。因为这里的结果不是你三两句指令做出来的 MVP,而是需要在线上稳定高效运行的系统。
最近出差在飞机上听了《面基》播客中一期:新一波超级婴儿潮:Agent 人口大爆发和加速的时间,里面提到在 AI Coding 的当下人人都可以在自己的电脑上手搓“小板凳”,那在这样的时代如何定义“好”呢?“小板凳”说的是很多人在家做小板凳,但客户真正需要的是沙发。也就是说你费劲做出来的那点东西,离真正被市场需要、愿意付钱的成熟产品,往往还差得很远。但为什么明明很多人知道自己做的就是小板凳,却还是忍不住一张接一张地做呢?原因可能会有很多:一条新赛道的好奇感,一个新时代的压迫感,抑或是?做小板凳本身并没有什么不好,板凳和沙发之间也不是说相差十万八千里,做沙发的老师傅也是从做小板凳开始的。我希望团队里的人可以在做完十个小板凳之后去尝试做一个沙发,或者停下来了解下更底层的榫卯结构。
战略的制定者一定是从战术的执行者到战术的制定者再一步一步走过来的,掌控欲并非是要事必躬亲(Sometimes maybe),而是需要了解更多可以支持战略制定的信息。战略性的失误会比战术性的失误可怕的多,如果可以我也想对 AI 说你自己看着办吧,然后我就在旁悠闲的喝茶,甚至连监督都不想做。在此推荐一下宝玉的一篇文章:为什么我不“凭感觉编程”,权当是一个新的视角,任凭弱水三千,我只取一瓢饮。
伦理视角
我个人现在从事安全相关工作,日常处理的工作内容中包括很多“坏”事儿,这里的“坏”并不是代表我要去做坏事,而是事情的背景中充斥的一些敏感的内容。基于这种情况,在我使用 AI 的过程中会存在两类问题:
- AI 触发审查机制,尽管我的要求合法合规,但由于给定的上下文背景中存在敏感信息,AI 最终会拒绝我的要求。
- AI 在授权的场景下,为了实现要求会“不择手段”的尝试尽可能多的路径,但对于路径在物理世界的风险评估不够,有时会造成一些不好的结果。例如:因为现有系统存在 BUG,AI 执行了本不该执行的操作,最后导致原有系统发生崩溃。这锅你说是让 AI 背,还是你来背,还是现有系统背,还是各打五十大板?
两个问题存在一定的冲突,有时候我们需要更多的“自由”,有时候我们又不太想让它太过“自由”。这里我们有很多的技术方式可以去尝试解决,但除此之外我们更需要从伦理视角去重新审视 AI 之于我们的关系。
- 摆正思想,善(善良)用 AI:不为恶(Don’t be Evil)是 Google 提出的企业座右铭,真的很难做到,但我们又必须去做。我的底线可以低些,但不能没有。
- 摆正角色,善(善于)用 AI:当下我们需要为 AI 犯下的错误承当全部责任,不要以为你说的三两句指令无关痛痒,一切的后果及其引发的一连串问题你都难以想象。
你的 AI 不是你的 AI,这里回应多年前看的一部剧『你的孩子不是你的孩子』,对于 AI 的培养可以像培养孩子一样,两者是有很多共通之处的。