本文主要参考自 SIFT meets CNN: A decade survey of instance retrieval 1 和 Deep Learning for Instance Retrieval: A Survey 2。
基于内容的图像检索(Content-based image retrieval,CBIR),属于图像分析的一个研究领域。基于内容的图像检索目的是在给定查询图像的前提下,依据内容信息或指定查询标准,在图像数据库中搜索并查找出符合查询条件的相应图片 3。
根据不同的视觉表示方法,可以将基于内容的图像检索方法分为两类:基于 SIFT 特征的和基于深度学习的。基于 SIFT 特征的方法分为如下 3 类:
- 使用小型编码本:视觉词汇少于几千个,紧凑向量在降维和编码之前生成。
- 使用中型编码本:考虑到 BoW 的稀疏性和视觉词汇的低区分度,使用倒排索引和二进制签名方法。准确率和效率之间的权衡是该算法的主要影响因素。
- 使用大型编码本:考虑到 BoW 直方图的稀疏性和视觉词汇的高区分度,在算法中使用了倒排索引和存储友好型的签名方式。在编码本生成和编码中使用了类似的方法。
基于深度学习的方法分为如下 3 类:
- 混合型方法:图像块被多次输入到 CNN 中用于特征提取。编码与索引方法和基于 SIFT 的检索方法类似。
- 使用预训练的模型:通过在类似 ImageNet 的大数据集预训练的 CNN 模型进行单通道特征提取,同时使用紧凑编码和池化技术。
- 使用微调的模型:在图像与目标数据具有相似分布的训练集上对 CNN 模型进行微调。通过端到端的方法利用 CNN 模型进行单通道特征提取。这种视觉表示方法可以提升模型的区分能力。
各类模型的异同点如下表所示:
| 方法类型 | 检测 | 描述 | 编码 | 维度 | 索引 | |
|---|---|---|---|---|---|---|
| 基于 SIFT | 大编码本 | DoG, Hessian-Affine, dense patches 等 |
局部不变 描述,例如: SIFT |
Hard, soft | 高 | 倒排索引 |
| 中编码本 | Hard, soft, HE | 中 | 倒排索引 | |||
| 小编码本 | VLAD, FV | 低 | ANN 模型 | |||
| 基于深度学习 | 混合模型 | 图像块 | CNN 特征 | VLAD, FV, pooling | 不定 | ANN 模型 |
| 预训练模型 | 预训练 CNN 模型的列特征或全连接层 | VLAD, FV, pooling | 低 | ANN 模型 | ||
| 微调模型 | 从预训练 CNN 模型中端到端提取的全局特征 | 低 | ANN 模型 | |||
基于内容的图像检索里程碑节点如下图所示:
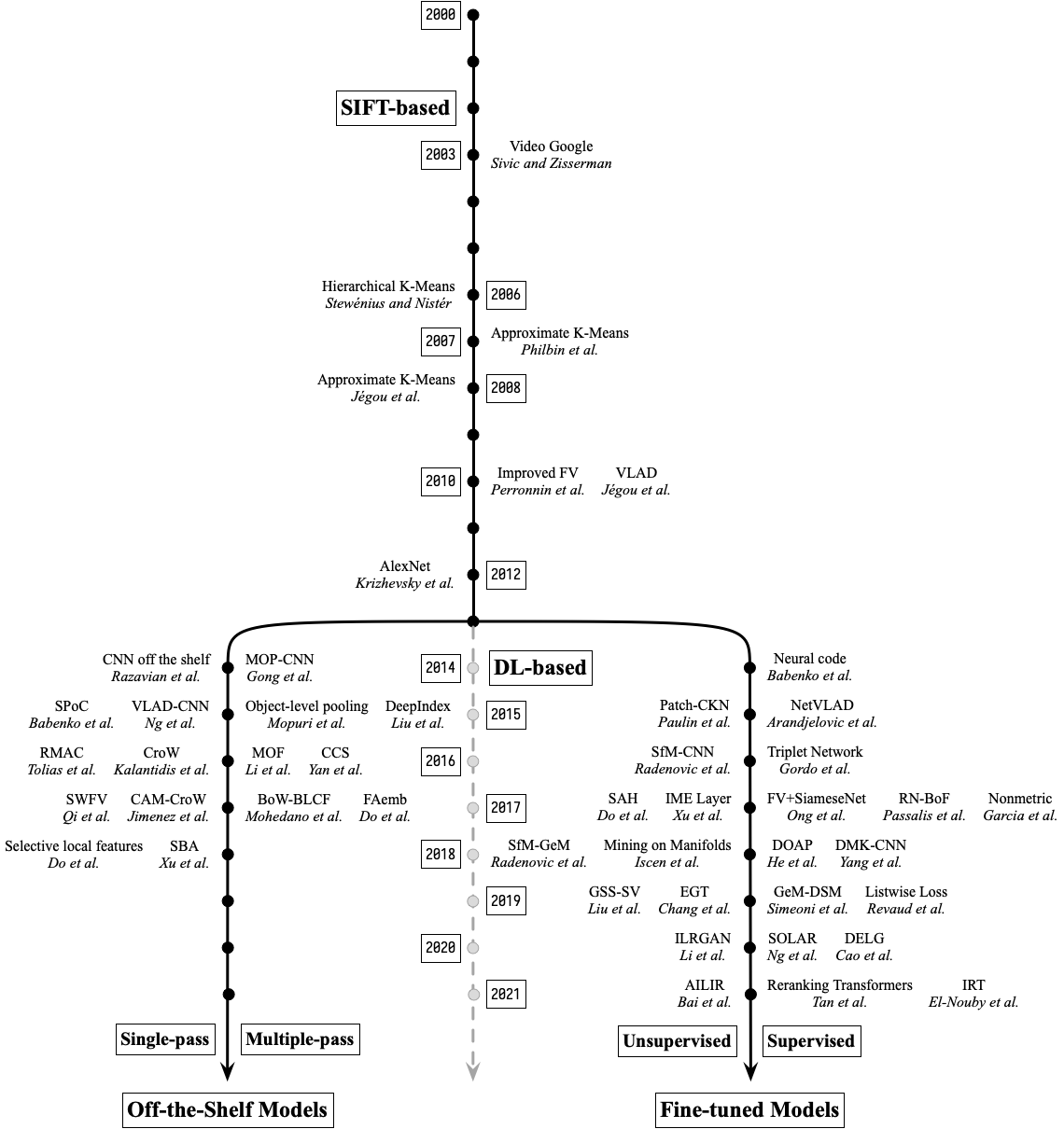
基于 SIFT 的图像检索
基于 SIFT 的图像检索流程如下图所示:
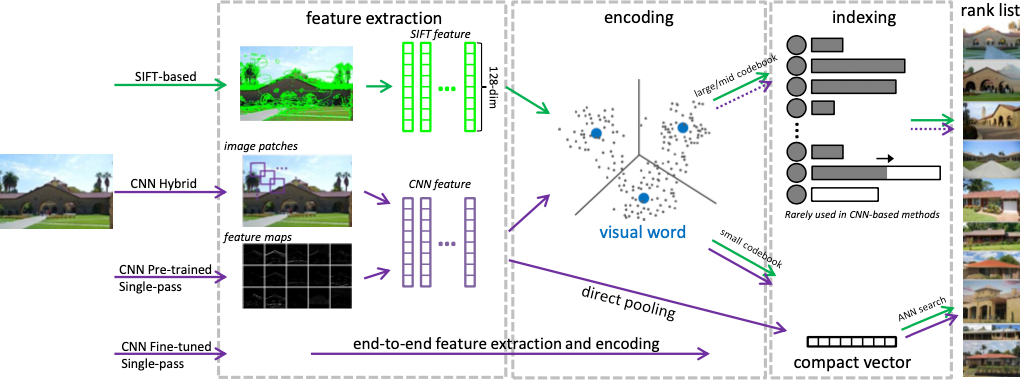
- 局部特征提取:假设有一个包含
$N$张图片的集合$\mathcal{G}$。指定一个特征检测器,从稀疏的兴趣点或密集的图像块中提取局部描述符。我们用$D$表示局部描述符,$\left\{f_{i}\right\}_{i=i}^{D}, f_{i} \in \mathbb{R}^{p}$表示图像中被检测的区域。 - 编码本训练:基于 SIFT 的方法需要离线训练一个编码本。编码本中的每个视觉词汇位于子空间的中心,称为 Voronoi Cell。一个更大的密码本对应一个更精细的划分,进而产生更有区分性的视觉词汇,反之亦然。假设存在一个用无标注数据集训练的局部描述符池
$\mathcal{F} \equiv\left\{f_{i}\right\}_{i=1}^{M}$,一个基准方法是利用 K-means 将$M$个点聚类成$K$个簇,这$K$个视觉词汇则构成了大小为$K$的编码本。 - 特征编码:一个局部描述符
$f_{i} \in \mathbb{R}^{p}$通过特征编码过程$f_{i} \rightarrow g_{i}$被映射到嵌入特征$g_{i} \in \mathbb{R}^{l}$。当使用 K-means 聚类时,$f_i$可以根据其与视觉词汇的距离进行编码。
局部特征提取
Harris 角点检测
特征点在图像中一般有具体的坐标,并具有某些数学特征,如局部最大或最小灰度、以及某些梯度特征等。可以通过加权的差值平方和来形式化的比较一个图像的两个区块:
$$ \label{eq:e_u_v} E\left(u, v\right) = \sum_{x, y} w\left(x, y\right)\left[I\left(x + u, y + v\right)-I\left(x, y\right)\right]^{2} $$
其中,$I$ 为待比较的图像,$\left(u, v\right)$ 为平移向量,$w\left(x, y\right)$ 是在空间上变化的权重。
根据泰勒展开,窗口平移后图像的一阶近似为:
$$ \begin{aligned} I(x + u, y + v) &= I(x, y) + I_{x}(x, y) u + I_{y}(x, y) v + O\left(u^2, v^2\right) \\ & \approx I(x, y) + I_{x}(x, y) u + I_{y}(x, y) v \end{aligned} $$
其中,$I_{x}$ 和 $I_{y}$ 是图像 $I(x, y)$ 的偏导数,那么式 $\ref{eq:e_u_v}$ 可以简化为:
$$ \begin{aligned} E\left(u, v\right) & \approx \sum_{x, y} w(x, y)\left[I_{x}(x, y) u + I_{y}(x, y) v\right]^{2} \\ &=\left[\begin{array}{ll} u & v \end{array}\right] M(x, y)\left[\begin{array}{c} u \\ v \end{array}\right] \end{aligned} $$
其中,
$$ M=\sum w(x, y)\left[\begin{array}{cc} I_{x}^{2} & I_{x} I_{y} \\ I_{x} I_{y} & I_{y}^{2} \end{array}\right] $$
通过求解 $M$ 的特征向量,我们可以获得 $E(u, v)$ 最大和最小增量的方向,对应的特征值则为实际的增量值。Harris 角点检测方法对每一个窗口定义了一个 $R$ 值:
$$ R = \operatorname{det} M - k (\operatorname{trace} M)^{2} $$
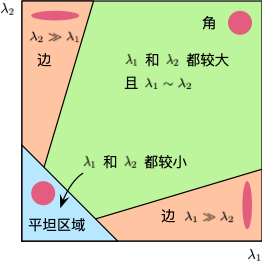
其中,$\operatorname{det} M = \lambda_1 \lambda_2$ 是矩阵 $M$ 的行列式,$\operatorname{trace} M = \lambda_1 + \lambda_2$ 是矩阵 $M$ 的迹,$\lambda_1$ 和 $\lambda_2$ 为矩阵 $M$ 特征值,$k$ 为经验常数,通常取值为 $[0.04, 0.06]$。特征值决定了当前区域是一个角、边还是平坦区域。
- 当
$\lvert R \rvert$比较小时,$\lambda_1$和$\lambda_2$均比较小,则区域为平坦区域。 - 当
$R < 0$时,$\lambda_1 \gg \lambda_2$或$\lambda_1 \ll \lambda_2$,则区域为边。 - 当
$R$较大时,$\lambda_1$和$\lambda_2$都很大且$\lambda_1 \sim \lambda_2$,则区域为角。
Harris 角点检测方法具备如下性质:
$k$影响被检测角点数量:增大$k$将减小$R$,从而减少被检测角点的数量,反之亦然。- 对亮度和对比度的变化不敏感:Harris 角点检测对图像进行微分运算,微分运算对图像密度的拉升或收缩和对亮度的抬高或下降不敏感。
- 具有旋转不变性:Harris 角点检测算子使用的是角点附近区域的灰度二阶矩矩阵。而二阶矩矩阵可以表示成一个椭圆,椭圆的长短轴正是二阶矩矩阵特征值平方根的倒数。当特征椭圆转动时,特征值并不发生变化,所以判断角点的
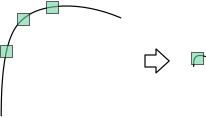
$R$值也不发生变化。 - 不具有尺度不变性:如下图所示,当左图被缩小时,在检测窗口尺寸不变的前提下,在窗口内所包含图像的内容是完全不同的。左侧的图像可能被检测为边缘或曲线,而右侧的图像则可能被检测为一个角点。
利用 Harris 方法检测角点的效果如下图所示(代码详见这里):

尺度空间极值检测
为了使检测到的特征点具备尺度不变性,使能够在不同尺度检测到尽可能完整的特征点或关键点,则需要借助尺度空间理论来描述图像的多尺度特征。相关研究证明高斯卷积核是实现尺度变换的唯一线性核。因此可用图像的高斯金字塔表示尺度空间,而且尺度规范化的 LoG 算子具有尺度不变性,在具体实现中,可用高斯差分( DoG)算子近似 LoG 算子,在构建的尺度空间中检测稳定的特征点。
在图像处理模型中引入一个被视为尺度的参数,通过连续变化尺度参数获取多尺度下的空间表示序列,对这些空间序列提取某些特征描述子,抽象成特征向量,实现图像在不同尺度或不同分辨率的特征提取。尺度空间中各尺度图像的模糊程度逐渐变大,模拟人在由近到远时目标在人眼视网膜上的成像过程。而且尺度空间需满足一定的不变性,包括图像灰度不变性、对比度不变性、平移不变性、尺度不变性以及旋转不变性等。在某些情况下甚至要求尺度空间算子具备仿射不变性。
图像的尺度空间 $L(x, y, \sigma)$ 可以定义为图像 $I(x, y)$ 与可变尺度的高斯函数 $G(x, y, \sigma)$ 的卷积:
$$ \begin{aligned} L(x, y, \sigma) &= G(x, y, \sigma) * I(x, y) \\ G(x, y, \sigma) &= \frac{1}{2 \pi \sigma^{2}} e^{-\frac{x^{2}+y^{2}}{2 \sigma^{2}}} \end{aligned} $$
其中,$\sigma$ 是尺度变化因子,大小决定图像的平滑程度,值越大图像越模糊。大尺度对应图像的概貌特征,小尺度对应图像的细节特征。一般根据 $3 \sigma$ 原则,高斯核矩阵的大小设为 $(6 \sigma+1) \times(6 \sigma+1)$。
尺度归一化的高斯拉普拉斯函数 $\sigma^{2} \nabla^{2} G$ 可以提取稳定的特征,高斯差分函数(Difference-of-Gaussian,DoG)
4 与尺度归一化的高斯拉普拉斯函数近似:
$$ \begin{aligned} LoG &= \sigma^{2} \nabla^{2} G \\ DoG &= G(x, y, \sigma_2) - G(x, y, \sigma_1) \end{aligned} $$
利用差分近似替代微分,有:
$$ \sigma \nabla^{2} G=\frac{\partial G}{\partial \sigma} \approx \frac{G(x, y, k \sigma)-G(x, y, \sigma)}{k \sigma-\sigma} $$
因此有:
$$ G(x, y, k \sigma)-G(x, y, \sigma) \approx(k-1) \sigma^{2} \nabla^{2} G $$
其中,$k - 1$ 是个常数,不影响极值点的检测,DoG 和 LoG 的对比图如下:
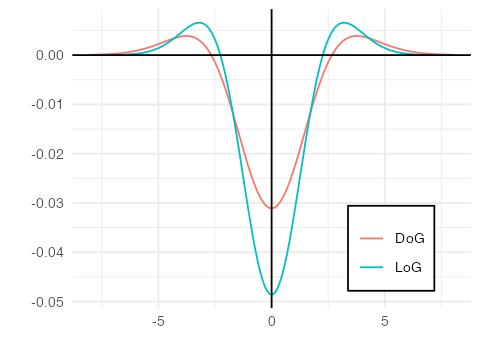
在使用高斯金字塔构建尺度空间时,主要包括两部分:对图像做下采样,以及对图像做不同尺度的高斯模糊。对图像做降采样得到不同尺度的图像,也就是不同的组(Octave),后面的 Octave(高一层的金字塔)为上一个 Octave(低一层的金字塔)下采样得到,图像宽高分别为上一个 Octave 的 1/2 。每组(Octave)又分为若干层(Interval),通过对图像做不同尺度的高斯模糊得到,如下图所示:
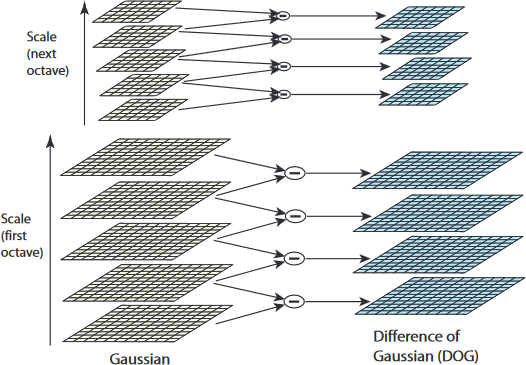
在由图像金字塔表示的尺度空间中,Octave 由原始图像的大小和塔顶图像的大小决定:
$$ Octave = \log_2 \left(\min\left(w_b, h_b\right)\right) - \log_2 \left(\min\left(w_t, h_t\right)\right) $$
其中,$w_b$ 和 $h_b$ 分别为原始图像的宽和高,$w_t$ 和 $h_t$ 分别为金字塔顶部图像的宽和高。
尺度参数 $\sigma$ 的取值与金字塔的组数和层数相关,设第一组第一层的尺度参数取值为 $\sigma \left(1, 1\right)$,一般取值为 $1.6$,则第 $m$ 组第 $n$ 层的取值为:
$$ \sigma(m, n)=\sigma\left(1, 1\right) \cdot 2^{m-1} \cdot k^{n-1}, \quad k=2^{1/S} $$
其中,$S$ 为金字塔中每组的有效层数,$k=2^{1/S}$ 是变化尺度因子。在检测极值点前对原始图像的高斯平滑会导致图像高频信息的丢失,所以在建立尺度空间之前,先利用双线性插值将图像扩大为原来的两倍,以保留原始图像信息,增加特征点数量。
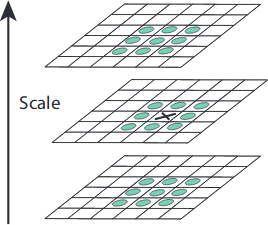
为了寻找 DoG 尺度空间的极值点,每一个采样点要和其所有邻域像素相比较,如下图所示,中间检测点与其同尺度的 8 个邻域像素点以及上下相邻两层对应的 9×2 个像素点一共 26 个点作比较,以确保在图像空间和尺度空间都能检测到极值点。一个像素点如果在 DoG 尺度空间本层及上下两层的 26 邻域中取得最大或最小值时,就可以认为该点是图像在该尺度下的一个特征点。
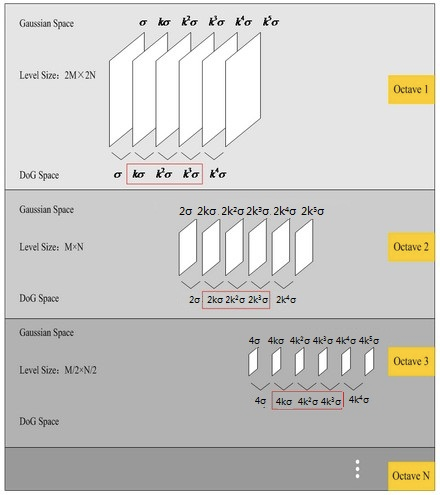
在极值比较的过程中,每一组差分图像的首末两层是无法比较的,为了在每组中检测 $S$ 个尺度的极值点,则 DoG 金字塔每组须有 $S+2$ 层图像,高斯金字塔每组须有 $S+3$ 层图像。另外,在下采样时,高斯金字塔中后一组(Octive)的底层图像是由前一组图像的倒数第 3 张图像($S+1$ 层)隔点采样得到。这样也保证了尺度变化的连续性,如下图所示:
关键点定位
在 DoG 尺度空间检测到的极值点是离散的,通过拟合三元二次函数可以精确定位关键点的位置和尺度,达到亚像素精度。同时去除低对比度的检测点和不稳定的边缘点(因为 DoG 算子会产生较强的边缘响应),以增强匹配稳定性,提高抗噪声能力。
离散空间的极值点并不是真正的极值点,如下图所示一维函数离散空间得到的极值点与连续空间极值点的差别。利用已知的离散空间点插值得到的连续空间极值点的方法叫做子像素插值(Sub-pixel Interpolation)。
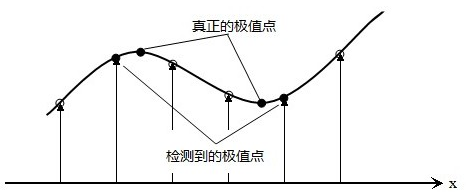
假设在尺度为 $\sigma$ 的尺度图像 $D(x, y, \sigma)$ 检测到一个局部极值点,空间位置为 $(x, y, \sigma)$。根据上图直观可知,它只是离散情况下的极值点,而连续情况下,极值点可能坐落在 $(x, y, \sigma)$ 附近,设连续情况的正真极值点偏离 $(x, y, \sigma)$ 的坐标为 $(\Delta x, \Delta y, \Delta \sigma)$。则对 $D(x + \Delta x, y + \Delta y, \sigma + \Delta \sigma)$ 在 $D(x, y, \sigma)$ 处进行泰勒展开(保留二阶),有:
$$ \begin{split} & \ D(x+\Delta x, y+\Delta y, \sigma+\Delta \sigma) \\ \approx & \ D(x, y, \sigma)+\left[\begin{array}{lll} \frac{\partial D}{\partial x} & \frac{\partial D}{\partial y} & \frac{\partial D}{\partial \sigma} \end{array}\right]\left[\begin{array}{c} \Delta x \\ \Delta y \\ \Delta \sigma \end{array}\right] \\ & +\frac{1}{2}\left[\begin{array}{lll} \Delta x & \Delta y & \Delta \sigma \end{array}\right]\left[\begin{array}{lll} \frac{\partial D^{2}}{\partial x^{2}} & \frac{\partial D^{2}}{\partial x \partial y} & \frac{\partial^{2} D}{\partial x \partial \sigma} \\ \frac{\partial D^{2}}{\partial y \partial x} & \frac{\partial D^{2}}{\partial y^{2}} & \frac{\partial D^{2}}{\partial y \partial \sigma} \\ \frac{\partial D^{2}}{\partial \sigma \partial x} & \frac{\partial D^{2}}{\partial \sigma \partial y} & \frac{\partial D^{2}}{\partial \sigma^{2}} \end{array}\right]\left[\begin{array}{c} \Delta x \\ \Delta y \\ \Delta \sigma \end{array}\right] \end{split} $$
将上式写成矢量形式如下:
$$ D(X+\Delta X)=D(X)+\frac{\partial D^{\top}(X)}{\partial X} \Delta X+\frac{1}{2} \Delta X^{\top} \frac{\partial^{2} D(X)}{\partial X^{2}} \Delta X $$
上式对 $\Delta X$ 求导,并令其等于零,可以得到极值点的偏移量:
$$ \Delta X=-\frac{\partial^{2} D(X)}{\partial X^{2}}^{-1} \frac{\partial D^{\top}(X)}{\partial X} $$
通过多次迭代(Lowe SIFT 算法里最多迭代 5 次),得到最终候选点的精确位置与尺度 $\hat{X}$。当超出所设定的迭代次数或者超出图像边界的范围时应删除该点,如果 $\lvert D(\hat{X}) \rvert$ 小于某个阈值则将该极值点也应该删除。
高斯差分函数有较强的边缘响应,对于比较像边缘的点应该去除掉。这样的点的特征为在某个方向有较大主曲率,而在垂直的方向主曲率很小。主曲率可通过一个 $2 \times 2$ 的 Hessian 矩阵求出:
$$ H=\left[\begin{array}{ll} D_{x x} & D_{x y} \\ D_{x y} & D_{y y} \end{array}\right] $$
$D$ 的主曲率和 $H$ 的特征值成正比,令 $\alpha$ 为较大的特征值,$\beta$ 为较小的特征值,$\alpha = \gamma\beta$,则有:
$$ \begin{aligned} \operatorname{trace}(H) &= D_{x x}+D_{y y}=\alpha+\beta \\ \operatorname{det}(H) &= D_{x x} D_{y y}-\left(D_{x y}\right)^{2}=\alpha \beta \\ \frac{\operatorname{trace}(H)^{2}}{\operatorname{det}(H)} &= \frac{(\alpha+\beta)^{2}}{\alpha \beta}=\frac{(\gamma+1)^{2}}{\gamma} \end{aligned} $$
上式的结果只与两个特征值的比例有关,而与具体特征值无关。当两个特征值相等时,$\dfrac{(\gamma+1)^{2}}{\gamma}$ 的值最小,随着 $\gamma$ 的增加,$\dfrac{(\gamma+1)^{2}}{\gamma}$ 的值也增加。设定一个阈值 $\gamma_t$(Lowe SIFT 算法里最 $\gamma_t = 10$),若:
$$ \frac{\operatorname{trace}(H)^{2}}{\operatorname{det}(H)}<\frac{\left(\gamma_{t}+1\right)^{2}}{\gamma_{t}} $$
则认为该关键点不是边缘,否则予以剔除。
关键点方向指定
为了使特征描述符具有旋转不变性,需要利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数。对于在 DoG 金字塔中检测出的关键点,在其邻近高斯金字塔图像的 3𝜎 邻域窗口内计算其梯度幅值和方向,公式如下:
$$ \begin{aligned} &m(x, y)=\sqrt{(L(x+1, y)-L(x-1, y))^{2}+(L(x, y+1)-L(x, y-1))^{2}} \\ &\theta(x, y)=\arctan ((L(x, y+1)-L(x, y-1)) /(L(x+1, y)-L(x-1, y))) \end{aligned} $$
其中,$L$ 为关键点所在尺度空间的灰度值,$m(x, y)$ 为梯度幅值,$\theta(x, y)$ 为梯度方向。对于模值 $m(x, y)$ 按照 $\theta = 1.5 \theta_{oct}$ 邻域窗口为 $3 \theta$ 的高斯分布加权。在完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向,梯度直方图将梯度方向 $\left(0,360^{\circ}\right)$ 分为 36 个柱(bins),如下图所示(为简化,图中只画了八个方向的直方图),直方图的峰值所在的方向代表了该关键点的主方向。
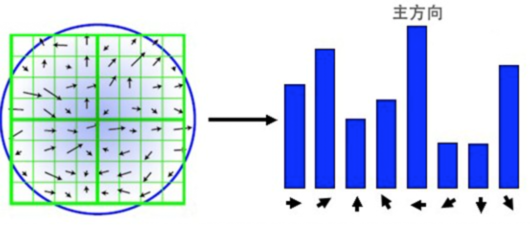
梯度方向直方图的峰值代表了该特征点处邻域梯度的主方向,为了增强鲁棒性,保留峰值大于主方向峰值 80% 的方向作为该关键点的辅方向。因此,在相同位置和尺度,将会有多个关键点被创建但方向不同,这可以提高特征点匹配的稳定性。
关键点特征描述符
在经过上述流程后,检测到的每个关键点有三个信息:位置、尺度以及方向,接下来就是为每个关键点建立一个描述符,用一组向量将这个关键点描述出来。这个特征描述符不但包括关键点,还包括其邻域像素的贡献,而且需具备较高的独特性和稳定性,以提高特征点匹配的准确率。SIFT 特征描述符是关键点邻域梯度经过高斯加权后统计结果的一种表示。通过对关键点周围图像区域分块,计算块内的梯度直方图,得到表示局部特征点信息的特征向量。例如在尺度空间 $4 \times 4$ 的窗口内统计 8 个方向的梯度直方图,生成一个 $4 \times 4 \times 8 = 128$ 维的表示向量。
特征描述符与特征点所在的尺度有关,因此,对梯度的求取应在特征点对应的高斯图像上进行。将关键点附近的邻域划分为 $d \times d$ 个子区域 $(d = 4)$,每个子区域做为一个种子点,每个种子点有 8 个方向。每个子区域的大小与关键点方向分配时相同,即每个区域边长为 $3 \theta_{oct}$。考虑到实际计算时需要进行三线性插值,采样窗口区域半边长设为 $\dfrac{3 \theta_{oct} (d + 1)}{2}$,又考虑到旋转因素(坐标轴旋转至关键点主方向),这个值需要乘以 $\sqrt{2}$,最后所需的图像区域半径为:
$$ \text{radius} = \dfrac{3 \sigma_{oct} \times \sqrt{2} \times(d+1)}{2} $$
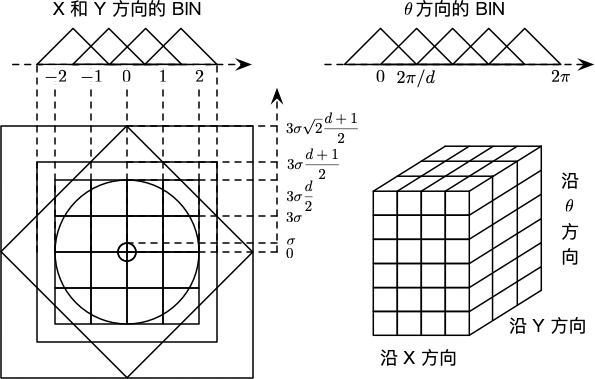
将坐标轴旋转至关键点主方向,以确保旋转不变性。如下图所示:
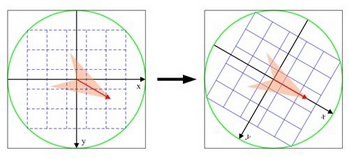
旋转后采样点的新坐标为:
$$ \left[\begin{array}{l} x^{\prime} \\ y^{\prime} \end{array}\right]=\left[\begin{array}{cc} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \end{array}\right]\left[\begin{array}{l} x \\ y \end{array}\right] \quad(x, y \in[\text {-radius, radius }]) $$
在图像半径区域内对每个像素点求其梯度幅值和方向,并对每个梯度幅值乘以高斯权重:
$$ w=m(u+x, b+v) \times e^{-\frac{x^{\prime 2}+y^{\prime 2}}{2 \sigma_{w}^{2}}} $$
其中,$u$ 和 $v$ 表示关键点在高斯金字塔图中的位置坐标,$x$ 和 $y$ 为旋转坐标轴至关键点主方向之前相对关键点的偏移量,$x^{\prime}$ 和 $y^{\prime}$ 为旋转坐标轴至关键点主方向之后相对关键点的偏移量。
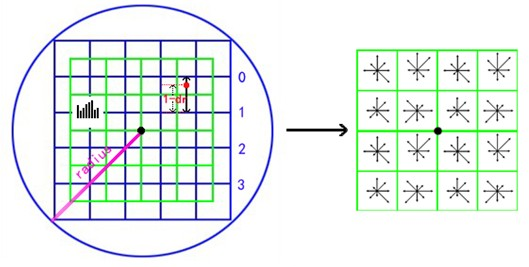
将旋转后的采样点坐标分配到对应的子区域,计算影响子区域的采样点的梯度和方向,分配到 8 个方向上。旋转后的采样点 $(x^{\prime}, y^{\prime})$ 落在子区域的下标为:
$$ \left[\begin{array}{l} x_{d} \\ y_{d} \end{array}\right]=\frac{1}{3 \sigma_{o c t}}\left[\begin{array}{c} x^{\prime} \\ y^{\prime} \end{array}\right]+\frac{d}{2}, \quad x_{d}, y_{d} \in[0, d] $$
将采样点在子区域的下标进行三线性插值,根据三维坐标计算与周围子区域的距离,按距离远近计算权重,最终累加在相应子区域的相关方向上的权值为:
$$ w^{\prime} = w \cdot\left[d_{r}^{i} \cdot\left(1-d_{r}\right)^{1-i}\right] \cdot\left[d_{c}^{j} \cdot\left(1-d_{c}^{1-j}\right)\right] \cdot\left[d_{o}^{k} \cdot\left(1-d_{o}\right)^{1-k}\right] $$
其中,$i, j, k$ 取值为 0 或 1,$d_r, 1- d_r$ 是对相邻两行的贡献因子,$d_c, 1- d_c$ 是对相邻两列的贡献因子,$d_o, 1- d_o$ 是对相邻两个方向的贡献因子。插值计算每个种子点八个方向的梯度,最终结果如下图所示:
得到 128 维特征向量后,为了去除光照变化的影响,需要对向量进行归一化处理。非线性光照变化仍可能导致梯度幅值的较大变化,但对梯度方向影响较小。因此对于超过阈值 0.2 的梯度幅值设为 0.2 ,然后再进行一次归一化。最后将特征向量按照对应高斯金字塔的尺度大小排序。至此,SIFT 特征描述符形成。
利用 SIFT 方法检测关键点的效果如下图所示(代码详见这里):

SIFT 方法的优点如下:
- 局部:SIFT 特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性。
- 独特:信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配。
- 大量:即使少数的几个物体也可以产生大量的 SIFT 特征向量。
- 高效:经优化的 SIFT 匹配算法甚至可以达到实时的要求。
- 可扩展:可以很方便的与其他形式的特征向量进行联合。
SIFT 方法的缺点如下:
- 默认算法的实时性不高。
- 部分情况下特征点较少。
- 对边缘光滑的目标无法准确提取特征点。
对于 SIFT 的改进可以参考 SURF 5 和 CSIFT 6。
本小节参考:
特征编码
BoF
BoF(Bag of Features, Bag of Visual Words)7 8 借鉴了文本中的 BoW(Bag of Words)模型的思路。从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」频率,得到图片的特征向量。BoF 算法的流程如下:
- 局部特征提取:利用上文中的 SIFT 等类似方法提取图片的局部特征,每个图片提取的特征数量不同,但每个特征的维度是相同的(例如:128 维)。
- 构建视觉词典:利用 K-means 等算法将所有图片的所有特征向量进行聚类,得到
$K$个聚类中心,即$K$个视觉词汇(Visual Word)。由于特征数量可能非常大,使用 K-means 算法聚类会相当耗时。 - 生成 BoF 特征:对于一个图像中的每一个特征,都可以在视觉词典中找到一个最相似的视觉词汇,因此可以对该图像统计得到一个
$K$维的直方图,每个值表示图像中局部特征在视觉词典中相似视觉词汇的频率。针对该步骤可以利用 TF-IDF 的思想获取加权的 BoF 特征结果。
BoF 算法的一些缺点也比较明显:
- 在使用 K-means 进行聚类时,
$K$和初始聚类中心的选取对结果敏感。字典过大,词汇缺乏一般性,对噪声敏感;字典过小,词汇区分性较差,无法充分表示图片。对于海量数据计算所需的时间和空间复杂度都比较高。 - 将图像表示成一个无序的特征,丢失了图片中的空间信息,表示上存在一定局限。
VLAD
VLAD(Vector of Local Aggregated Descriptors)9 方法同 BoF 类似,但在生成特征时采用如下公式:
$$ V(j, k)=\sum_{i=1}^{N} \operatorname{sign}_{k}\left(x_{i}\right)\left(x_{i}(j)-c_{k}(j)\right), \quad k \in K, j \in D $$
其中,$K$ 为词典大小,$N$ 为图片的局部特征数量,$D$ 为每个局部特征的维度,$x_i$ 表示第 $i$ 个局部特征,$c_k$ 表示第 $k$ 个聚类中心,$\operatorname{sign}_k$ 是一个符号函数,如果 $x_i$ 不属于聚类中心 $c_k$ 则为 $0$,反之则为 $1$。
从上式中可以看出 VLAD 累加了每个聚类的所有特征残差,通过 $x_i - c_k$ 将图像本身的局部特征分布差异转换为聚类中心的分布差异,通过归一化和降维等手段得到最终的全局特征。
FV
FV(Fisher Vector)10 本质上是用似然函数的梯度向量表示一幅图像。梯度向量的物理意义就是描述能够使模型更好地适应数据的参数变化方向,也就是数据拟合中参数调优的过程。在 FV 中我们采用高斯混合模型(Gaussian Mixture Model,GMM)。
高斯混合模型是由多个高斯模型线性叠加而成,公式如下:
$$ p(x)=\sum_{k=1}^{K} \pi_{k} N\left(x \mid \mu_{k}, \Sigma_{k}\right) $$
其中,$p(x)$ 表示数据 $x$ 出现的概率,$K$ 表示高斯模型个数,$\pi_k$ 表示第 $k$ 个高斯模型的权重,$\mu_k$ 表示第 $k$ 个高斯分布的均值,$\Sigma_k$ 表示第 $k$ 个高斯分布的方差。理论上,只要 $K$ 足够大,GMM 可以逼近任意一种概率分布。
GMM 的目标是求解参数 $\pi_k, \mu_k, \Sigma_k$ 使得它确定的概率分布生成这些给定数据的概率最大,即 $\Pi_{i=1}^{N} p\left(x_{i}\right)$ 最大。假设各个数据点之间满足独立同分布,可以将其转换成对数似然函数:
$$ \sum_{i=1}^{N} \log \left(p \left(x_i\right)\right) $$
假设 GMM 模型包含 $K$ 个高斯模型,则模型的参数集合为 $\lambda = \left\{w_i, \mu_k, \Sigma_k, k = 1, \cdots, K\right\}$,假设共有 $T$ 个特征向量,则似然函数可以表示为:
$$ \mathcal{L} (x \mid \lambda)=\sum_{t=1}^{T} \log \left(p\left(x_{t} \mid \lambda\right)\right) $$
其中的高斯分布是多个基高斯分布的混合:
$$ \label{eq:fv_gmm} p\left(x_{t} \mid \lambda\right)=\sum_{k=1}^{K} w_{k} * p_{k}\left(x_{t} \mid \lambda\right) $$
每个基高斯分布又可以表示为:
$$ p_{k}\left(x_{t} \mid \lambda\right) = \dfrac{1}{\left(2 \pi\right)^{\frac{D}{2}} \lvert\Sigma_k\rvert^{\frac{1}{2}}} e^{-\frac{1}{2} \left(x - \mu_k\right)^{\prime} \Sigma_k^{-1} \left(x - \mu_k\right)} $$
由贝叶斯公式可知,描述符 $x_t$ 数据第 $i$ 个高斯模型的概率为:
$$ \gamma_{t}(i)=\frac{w_{i} u_{i}\left(x_{t}\right)}{\sum_{k=1}^{K} w_{k} u_{k}\left(x_{t}\right)} $$
则公式 $\ref{eq:fv_gmm}$ 的梯度分量为:
$$ \begin{aligned} \frac{\partial \mathcal{L}(X \mid \lambda)}{\partial w_{i}} &=\sum_{t=1}^{T}\left[\frac{\gamma_{t}(i)}{w_{i}}-\frac{\gamma_{t}(1)}{w_{1}}\right] \text { for } i \geq 2, \\ \frac{\partial \mathcal{L}(X \mid \lambda)}{\partial \mu_{i}^{d}} &=\sum_{t=1}^{T} \gamma_{t}(i)\left[\frac{x_{t}^{d}-\mu_{i}^{d}}{\left(\sigma_{i}^{d}\right)^{2}}\right], \\ \frac{\partial \mathcal{L}(X \mid \lambda)}{\partial \sigma_{i}^{d}} &=\sum_{t=1}^{T} \gamma_{t}(i)\left[\frac{\left(x_{t}^{d}-\mu_{i}^{d}\right)^{2}}{\left(\sigma_{i}^{d}\right)^{3}}-\frac{1}{\sigma_{i}^{d}}\right] . \end{aligned} $$
由于概率空间和欧氏空间的归一化方式不同,在此引入 Fisher Matrix 进行归一化:
$$ \begin{aligned} f_{w_{i}} &=T\left(\frac{1}{w_{i}}+\frac{1}{w_{1}}\right) \\ f_{\mu_{i}^{d}} &=\frac{T w_{i}}{\left(\sigma_{i}^{d}\right)^{2}}, \\ f_{\sigma_{i}^{d}} &=\frac{2 T w_{i}}{\left(\sigma_{i}^{d}\right)^{2}} . \end{aligned} $$
归一化后即为 Fisher 向量:
$$ \begin{aligned} \mathscr{G}_{\alpha_{k}}^{X} &= f_{w_i}^{1/2} \frac{\partial \mathcal{L}(X \mid \lambda)}{\partial w_{i}} =\frac{1}{\sqrt{w_{k}}} \sum_{t=1}^{T}\left(\gamma_{t}(k)-w_{k}\right), \\ \mathscr{G}_{\mu_{k}}^{X} &= f_{\mu_i^d}^{1/2} \frac{\partial \mathcal{L}(X \mid \lambda)}{\partial \mu_{i}^{d}} =\frac{1}{\sqrt{w_{k}}} \sum_{t=1}^{T} \gamma_{t}(k)\left(\frac{x_{t}-\mu_{k}}{\sigma_{k}}\right), \\ \mathscr{G}_{\sigma_{k}}^{X} &= f_{\sigma_i^d}^{1/2} \frac{\partial \mathcal{L}(X \mid \lambda)}{\partial \sigma_{i}^{d}} =\frac{1}{\sqrt{w_{k}}} \sum_{t=1}^{T} \gamma_{t}(k) \frac{1}{\sqrt{2}}\left[\frac{\left(x_{t}-\mu_{k}\right)^{2}}{\sigma_{k}^{2}}-1\right] \end{aligned} $$
其中 $\mathscr{G}_{\alpha_{k}}^{X}$ 同 BoF 有类似效果,$\mathscr{G}_{\mu_{k}}^{X}$ 同 VLAD 有类似效果。
图像检索
倒排索引
倒排索引是一种提高存储和检索效率的算法,它常被用于大/中等规模的编码本中,结构如下图所示:
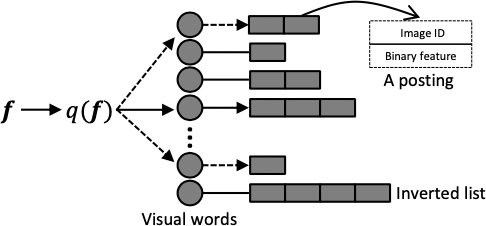
倒排索引是一个一维结构,其中每一个条目对应编码本中的一个视觉词汇。每一个视觉词汇都包含一个倒排表,每个倒排表中的索引被称为索引特征或者记录。倒排索引很好地发挥了大规模编码本词汇直方图稀疏性的特点。
ANN
基于近似最近邻搜索(Approximate Nearest Neighbor Search,ANN)的方法,请参考之前的博客。
基于深度学习的图像检索
基于深度学的图像检索流程如下图所示:
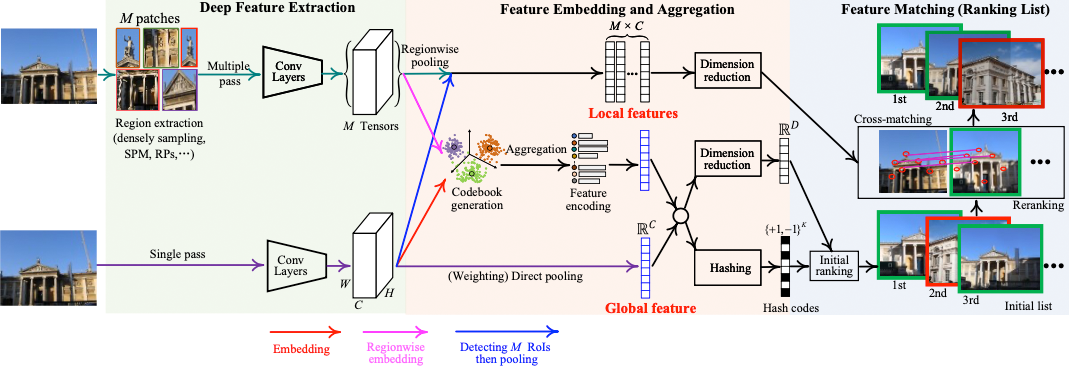
- 网络前馈方式:将图片输入 DCNN 的方式有两种:单路和多路。单路将整个图片作为输入,多路依赖区域提取,例如空间金字塔模型(Spatial Pyramid Models)和区域候选网络(Region Proposal Networks,RPN)。
- 深度特征提取:基于整个图像或部分区块的输入,网络的激活值可以用作原始的特征。全连接层提供了一个全局的视野,将一整个图片表示为单个向量。
- 特征嵌入和集成:基于图片级别或区块级别的描述符,构造全局或局部特征时包含两个重要步骤,通常为 PCA 和白化。特征嵌入将独立的局部特征映射到一个高维向量,特征集成则将多个映射的向量合并成一个单一向量。
- 特征匹配:特征匹配用来衡量图片之间特征的相似度。全局匹配可以通过欧式、汉明或其他距离度量进行高效计算。对于局部特征,可以通过 RANSAC 11 和近期的一些改进方法对局部特征进行相似度汇总来评估相似性。
关于卷积神经网络的细节介绍,请参考之前的博客。
网络前馈方式
单路前馈方法
单路前馈方法是将整个图片直接输入模型来提取特征。由于仅将图片输入模型一次,该方法效率较高。对于这类方法,全连接层和最后一个卷积层可以作为特征提取器。
多路前馈方法
相比于单路前馈方法,多路前馈方法由于需要将生成的多个图像块输入到模型中,因此相对耗时。这类方法通常包含两个步骤:图像块识别和图像块描述。使用不同方法可以获得不同尺度的图像块,如下图所示:

其中,(a) 为固定窗口大小划分的区块,(b) 为空间金字塔模型(Spatial Pyramid Model,SPM)划分的区块,(c) 为稠密采样的区块,(d) 为通过区域候选网络(Region Proposal Network,RPN)获得的候选区块。
深度特征选择
特征选择决定了提取特征的表达范围,例如:从全连接层可以获得全局级别特征,从卷积层可以获得区块级别特征。
从全连接层提取
将全连接层作为全局特征提取器,通过 PCA 降维和标准化后可以用于度量图像的相似性。但由于这一层是全连接的,每个神经元都会产生图像级别的描述符,这会导致两个明显的缺陷:包括无关信息和缺少局部几何不变性。
针对第一个缺陷,可以通过多路前馈方法来提取区块级别特征。针对第二个缺陷,缺乏几何不变性会影响图像变换(如:裁剪、遮挡)时的鲁棒性,通过使用中间卷积层可以来解决。
从卷积层提取
从卷积层(通常是最后一层)提取的特征保留了更多的结构细节,这对实例检索尤为有利。卷积层的神经元仅同局部区域相连接,这样较小的视野确保所生成的特征包含更多局部结构信息,同时对于图像变换更为鲁棒。
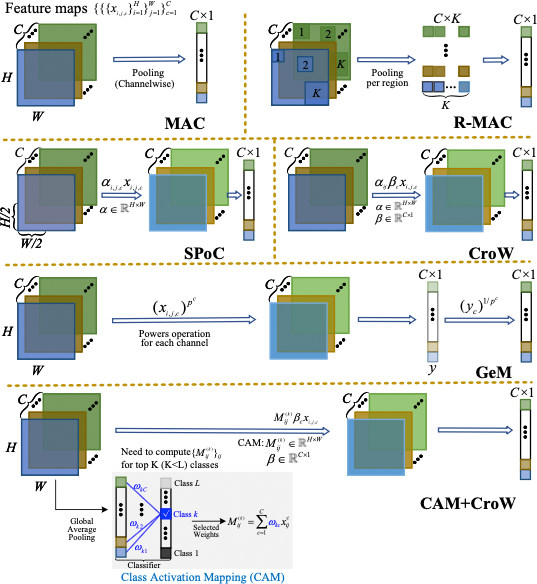
加和/平均和最大池化是用于生成全局特征的两个简单的集成方法,一些其他的集成方法,例如:MAC 12,R-MAC 13,GeM polling 14,SPoC 15,CroW 16 和 CAM+CroW 17 如下图所示:
特征融合策略
层级别融合
通过层级别融合,可以在深度网络中融合多个全连接层。全连接层的特征保留了全局高层级语义信息,卷积层的特征保留了局部中低层级的信息。因此,全局特征和局部特征在测量语义相似度时相辅相成,可以在一定程度上保证检索的效果。
模型级别融合
融合不同模型的特征也是可行的,这种融合方式关注于模型之间的互补性质,其可以分为:intra-model 和 inter-model 两类。intra-model 融合方式建议使用多个具有相似性或者结构上高度兼容的模型,而 inter-model 融合方式则使用结构上具有很大不同的模型。
inter-model 和 intra-model 融合同模型选择有关。融合候选模型的所有特征,然后根据拼接的特征学习得到一个度量,这种方式称为 early fusion 策略。或者对每个模型的特征学习各自的最优度量,然后组合这些度量用于最终的检索排名,这种方式称为 late fusion 策略。
特征嵌入和集成
特征嵌入和集成的主要目的是进一步提高从 DCNN 中提取的特征的区分能力,来生成用于检索特定实例的最终全局或局部特征。
匹配全局特征
全局特征可以从全连接层中提取,然后进行降维和标准化,通常情况下没有进一步的聚合过程。卷积特征也可以被集成到全局特征中,简单的方式是通过加和/平均或最大池化。卷积特征可以作为局部区域的描述符,因此可以利用基于 SIFT 的图像检索中提到的 BoF,VLAD,FV 等模型对其进行编码,然后再将他们聚合为一个全局描述符。
匹配局部特征
尽管全局特征匹配对于特征提取和相似度计算都具有很高的效率,但全局特征与空间验证和对应估计不兼容,这些是实例级别检索任务的重要过程。在匹配过程中,全局特征只匹配一次,而局部特征匹配通过汇总所有单个局部特征的相似性来评估(即多对多匹配)。
注意力机制
注意力机制可以看作是一种特征聚合,其核心思想是突出最相关的特征部分,通过计算注意力映射来实现。获取注意力映射的方法可以分为两类:非参数和参数,如下图所示,主要区别在于注意力映射中的重要性权重是否可学习。
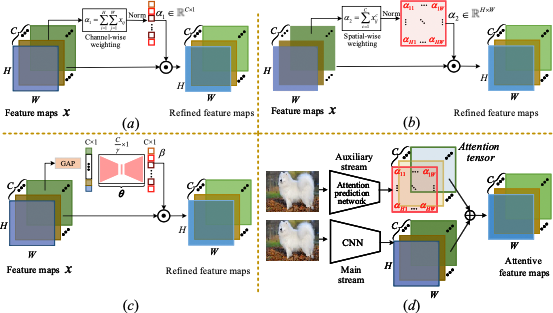
非参数加权是一种突出特征重要性的直接方法,相应的注意力映射可以通过通道或空间池化获得,如 (a) 和 (b) 所示。参数注意力映射可以通过深度网络学习,其输入可以是图像块或特征映射,这些方法通常用于有监督的度量学习,如 (c) 和 (d) 所示。
哈希嵌入
深度网络提取的实值特征通常是高维的,不太适合检索。因此,将深层特征转换为更紧凑的编码具有重要意义。由于其计算和存储效率,哈希算法已被广泛用于全局和局部描述符。
哈希函数可以作为一个层插入到深度网络中,以便可以通过有监督或无监督的方式同时训练和优化哈希码和深度网络。哈希函数训练时,相似图像的哈希码嵌入会尽可能的接近,不相似图像的哈希码嵌入会尽可能的分离。
模型微调
微调方法已被广泛研究以学习更好的检索特征。在基于图像分类的数据集上预训练的 DCNN 对类间可变性非常稳健,随后将成对的监督信息引入排名损失中,通过对检索表示进行正则化来微调网络。具有清晰且定义良好的真实标签的标准数据集对于微调深度模型以执行准确的实例级检索是必不可少的,否则就需要开发无监督的微调方法。在网络微调之后,可以将特征作为全局或局部来进行检索。
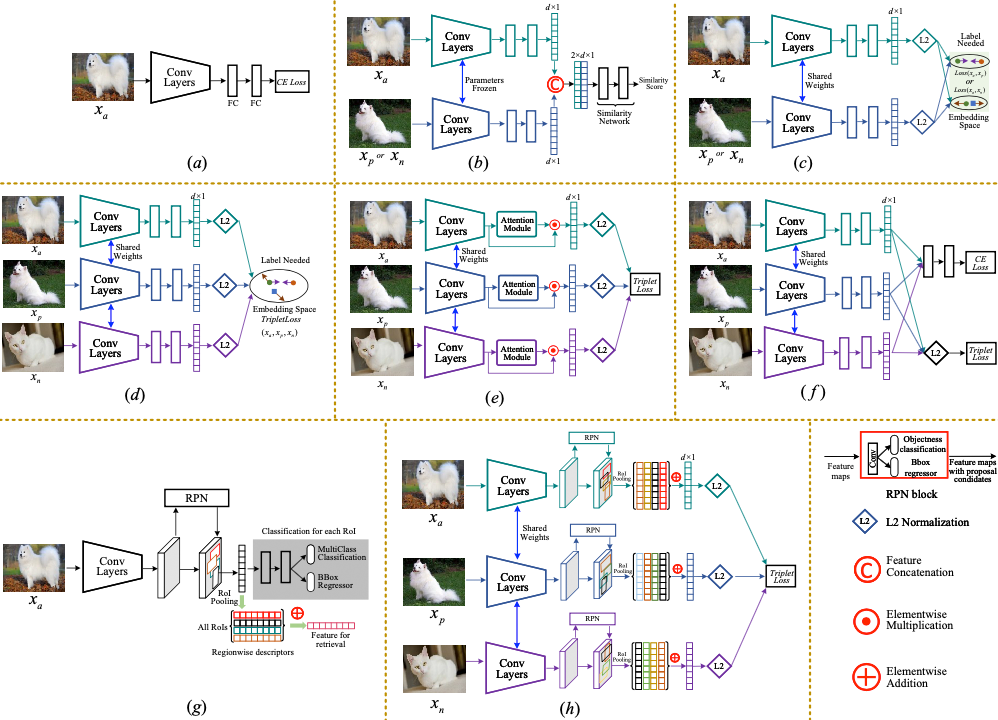
有监督微调
下图展示了不同类型的有监督微调方法:
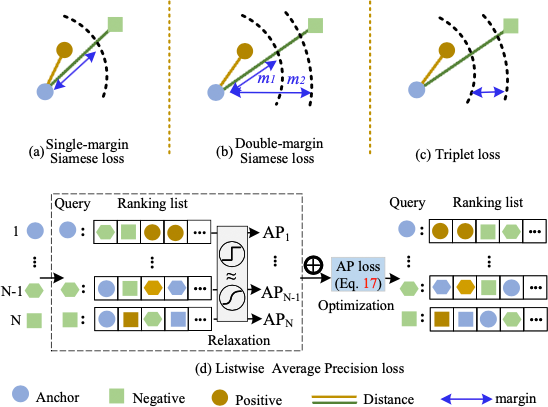
下图展示了不同类型的有监督微调损失函数:
无监督微调
由于成本等问题可能导致监督信息不足,从而监督网络微调变得不可行。因此,用于图像检索的无监督微调方法是非常必要的。对于无监督微调,两个方向是通过流形学习和聚类技术挖掘特征之间的相关性。具体细节不再展开讨论,详细内容请参见原文。
开放资源
- Stanford Online Products Retrieval Leaderboard
- CARS196 Retrieval Leaderboard
- CUB-200-2011 Retrieval Leaderboard
- In-shop Clothes Retrieval Leaderboard
- Image Retrieval - Paper with code
-
Zheng, L., Yang, Y., & Tian, Q. (2017). SIFT meets CNN: A decade survey of instance retrieval. IEEE transactions on pattern analysis and machine intelligence, 40(5), 1224-1244. ↩︎
-
Chen W., Liu Y., Wang W., Bakker E., Georigiou T., Fieguth P., Liu L., & Lew M. (2022). Deep Learning for Instance Retrieval: A Survey. arXiv:2101.11282 ↩︎
-
https://zh.wikipedia.org/wiki/基于内容的图像检索 ↩︎
-
Lindeberg, T. (1994). Scale-space theory: A basic tool for analyzing structures at different scales. Journal of applied statistics, 21(1-2), 225-270. ↩︎
-
Bay, H., Tuytelaars, T., & Van Gool, L. (2006, May). Surf: Speeded up robust features. In European conference on computer vision (pp. 404-417). Springer, Berlin, Heidelberg. ↩︎
-
Abdel-Hakim, A. E., & Farag, A. A. (2006, June). CSIFT: A SIFT descriptor with color invariant characteristics. In 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR'06) (Vol. 2, pp. 1978-1983). Ieee. ↩︎
-
Sivic, J., & Zisserman, A. (2003, October). Video Google: A text retrieval approach to object matching in videos. In Computer Vision, IEEE International Conference on (Vol. 3, pp. 1470-1470). IEEE Computer Society. ↩︎
-
Radenović, F., Jégou, H., & Chum, O. (2015, June). Multiple measurements and joint dimensionality reduction for large scale image search with short vectors. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval (pp. 587-590). ↩︎
-
Jégou, H., Douze, M., Schmid, C., & Pérez, P. (2010, June). Aggregating local descriptors into a compact image representation. In 2010 IEEE computer society conference on computer vision and pattern recognition (pp. 3304-3311). IEEE. ↩︎
-
Perronnin, F., Sánchez, J., & Mensink, T. (2010, September). Improving the fisher kernel for large-scale image classification. In European conference on computer vision (pp. 143-156). Springer, Berlin, Heidelberg. ↩︎
-
Fischler, M. A., & Bolles, R. C. (1981). Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 24(6), 381-395. ↩︎
-
Razavian, A. S., Sullivan, J., Carlsson, S., & Maki, A. (2016). Visual instance retrieval with deep convolutional networks. ITE Transactions on Media Technology and Applications, 4(3), 251-258. ↩︎
-
Tolias, G., Sicre, R., & Jégou, H. (2015). Particular object retrieval with integral max-pooling of CNN activations. arXiv preprint arXiv:1511.05879. ↩︎
-
Radenović, F., Tolias, G., & Chum, O. (2018). Fine-tuning CNN image retrieval with no human annotation. IEEE transactions on pattern analysis and machine intelligence, 41(7), 1655-1668. ↩︎
-
Babenko, A., & Lempitsky, V. (2015). Aggregating local deep features for image retrieval. In Proceedings of the IEEE international conference on computer vision (pp. 1269-1277). ↩︎
-
Kalantidis, Y., Mellina, C., & Osindero, S. (2016, October). Cross-dimensional weighting for aggregated deep convolutional features. In European conference on computer vision (pp. 685-701). Springer, Cham. ↩︎
-
Jimenez, A., Alvarez, J. M., & Giro-i-Nieto, X. (2017). Class-weighted convolutional features for visual instance search. arXiv preprint arXiv:1707.02581. ↩︎